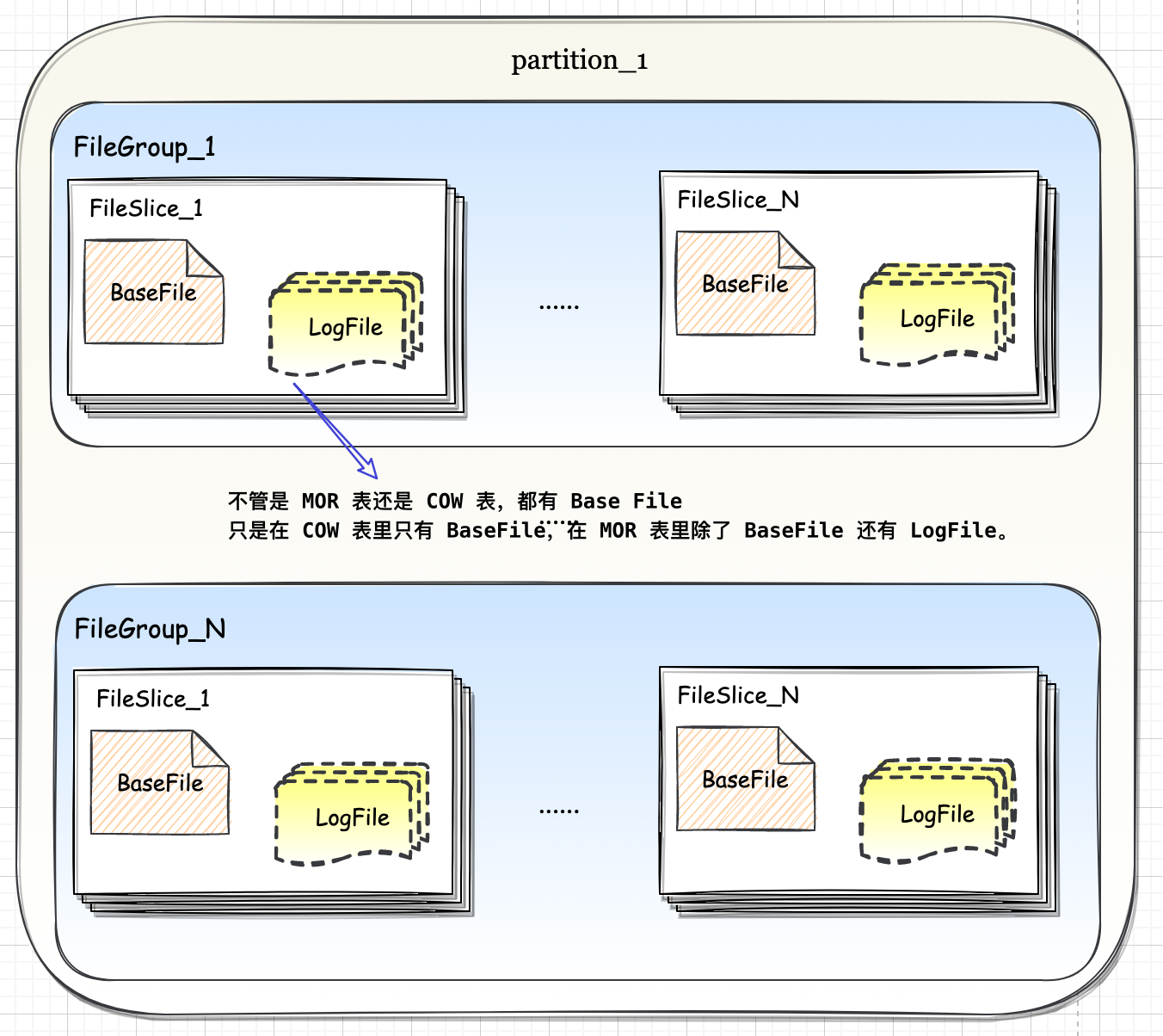
Spark-源码学习-架构设计-DataSource 体系-保存数据
一、概述
1 | df.write.format("hudi") |
二、write()
初始化 DataFrameWriter
1 | def write: DataFrameWriter[T] = { |
三、save()
save() 方法首先添加 path 参数,然后判断 source 是否等于 Hive,接下来通过 DataSource#lookupDataSource() 查找 hudi 对应的 DataSouce 类。
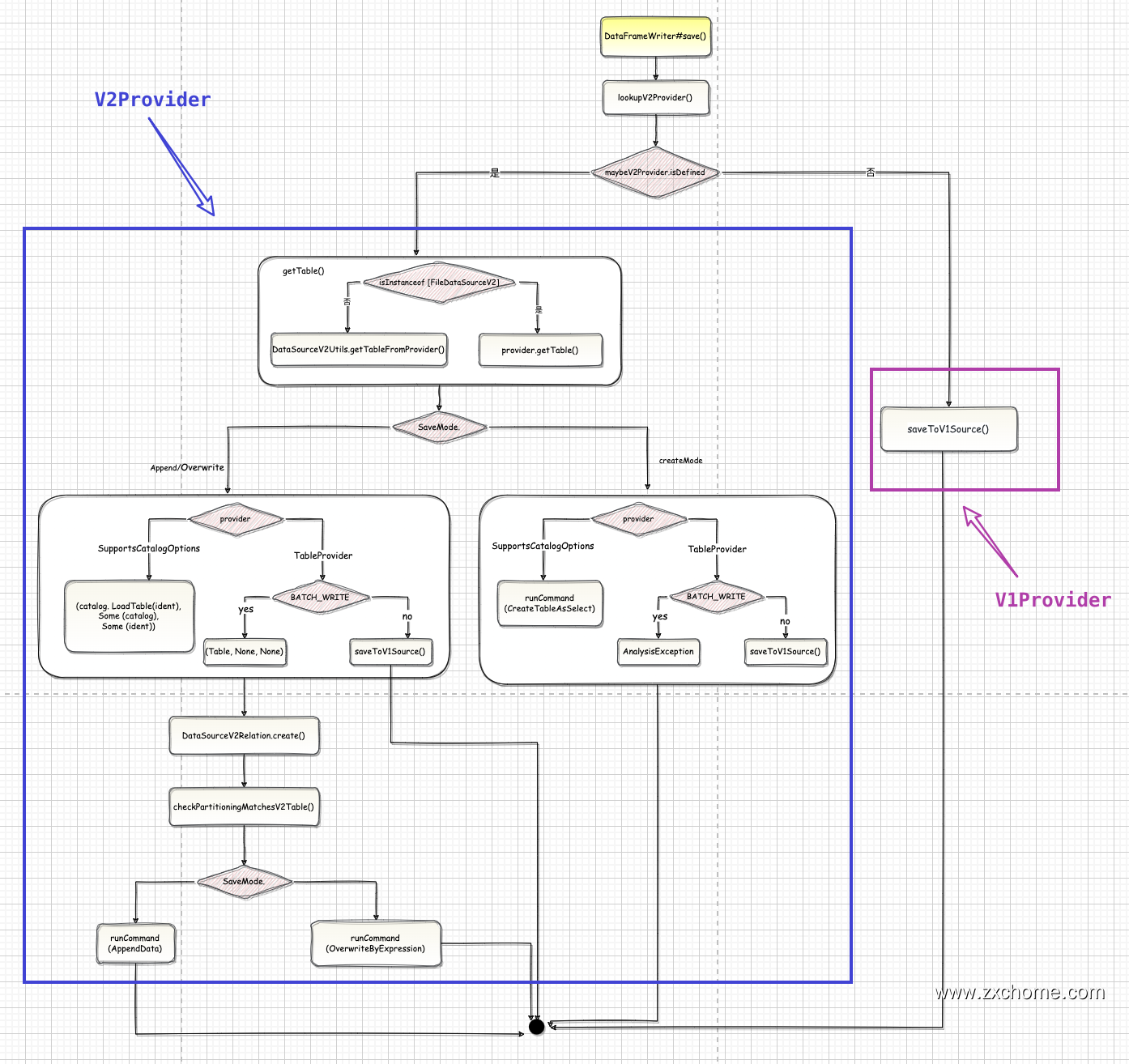
3.1. lookupV2Provider()
其实我们在上篇文章中讲isV2Provider时涉及到Spark3.2.1版本的lookupDataSource方法了,spark2.4.4的也差不多,我们再来看一下:其中的provider1 = hudi, provider2 = hudi.DefaultSource,然后加载所有的META-INF/services/org.apache.spark.sql.sources.DataSourceRegister,再返回里面的内容,和Hudi相关的有org.apache.hudi.DefaultSource org.apache.hudi.Spark2DefaultSource org.apache.spark.sql.execution.datasources.parquet.HoodieParquetFileFormat 等,然后过滤shortName=hudi的,只有Spark2DefaultSource满足,所以直接返回Spark2DefaultSource。这里和Spark3.2.1不同的是: Spark2对应Spark2DefaultSource Spark3对应Spark3DefaultSource
3.2. V2
3.2.1. Append/Overwrite
获取 Tuple(Table, TableCatalog, Identifier)
SupportsCatalogOptions
Identifier: SupportsCatalogOptions#extractSessionConfigs()
TableCatalog: CatalogV2Util#getTableProviderCatalog()
Table: TableCatalog#loadTable()
TableProvider
BATCH_WRITE- Table: getTable()
- TableCatalog: None
- Identifier: None
STREAMING_WRITE1
return saveToV1Source()
初始化 DataSourceV2Relation
1
val relation = DataSourceV2Relation.create(table, catalog, ident, dsOptions)
检查分区
1
checkPartitioningMatchesV2Table(table)
runCommand
1
2
3
4private def runCommand(session: SparkSession, name: String)(command: LogicalPlan): Unit = {
val qe = session.sessionState.executePlan(command)
SQLExecution.withNewExecutionId(qe, Some(name))(qe.toRdd)
}Append1
2
3runCommand(df.sparkSession, "save") {
AppendData.byName(relation, df.logicalPlan, extraOptions.toMap)
}Overwrite1
2
3
4runCommand(df.sparkSession, "save") {
OverwriteByExpression.byName(
relation, df.logicalPlan, Literal(true), extraOptions.toMap)
}
3.2.2. createMode
SupportsCatalogOptions
1
2
3
4
5
6
7
8
9
10runCommand(df.sparkSession) {
CreateTableAsSelect(
catalog,
ident,
partitioningAsV2,
df.queryExecution.analyzed,
Map(TableCatalog.PROP_PROVIDER -> source) ++ location,
extraOptions.toMap,
ignoreIfExists = createMode == SaveMode.Ignore)
}TableProvider
BATCH_WRITE
1
2
3throw new AnalysisException(s"TableProvider implementation $source cannot be " +
s"written with $createMode mode, please use Append or Overwrite " +
"modes instead.")STREAMING_WRITE
1
saveToV1Source()
3.3. V1
1 | saveToV1Source() |
saveToV1Source() 核心是后面的runCommand,先看他的参数 DataSource.planForWriting
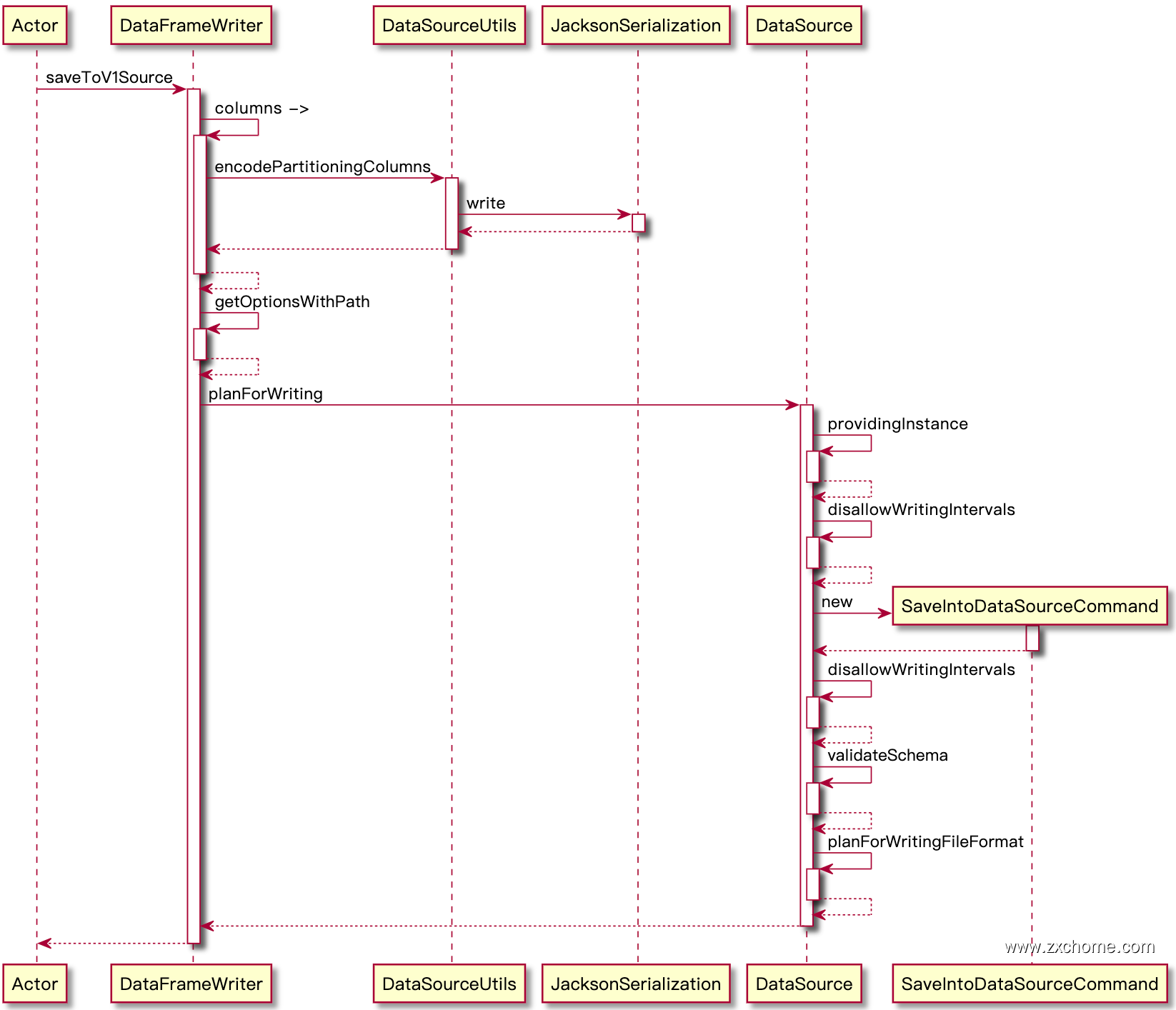
3.1. 获取数据源写入 Command
3.1.1. 初始化 DataSource
3.1.2. DataSource#planForWriting()
DataSource.lookupDataSource返回的为Spark2DefaultSource,并且它的父类DefaultSource实现了CreatableRelationProvider,所以返回SaveIntoDataSourceCommand
1 | def planForWriting(mode: SaveMode, data: LogicalPlan): LogicalPlan = { |
3.2. 运行 Command
1 | private def runCommand(session: SparkSession)(command: LogicalPlan): Unit = { |
这里的executedPlan 为ExecutedCommandExec,因为SaveIntoDataSourceCommand是RunnableCommand也是Command的子类,同样在我之前写的文章Hudi Spark SQL源码学习总结-Create Table我们可知无论是df.logicalPlan还是executedPlan都会触发一遍完整的Spark SQL的parsing、analysis、optimization 、planning,并且在planning阶段的planner.plan方法中会遍历strategies并应用其apply方法,其中有一个BasicOperators,它的apply方法为
1 | object BasicOperators extends Strategy { |
SaveIntoDataSourceCommand 是 RunnableCommand 的子类,所以返回 ExecutedCommandExec,它是 SparkPlan 的子类,至于如何触发 Spark SQL 的parsing、analysis、optimization 、planning

这里的SparkPlan的子类是ExecutedCommandExec,它的doExecute会调用sideEffectResult,继而调用cmd.run,这里的cmd为SaveIntoDataSourceCommand
它的run方法会调用自定义数据源的 createRelation() 方法~,
 微信
微信 支付宝
支付宝