数据湖-Hudi-源码学习-Kernel-TableFormat-FileLayouts-分区目录-数据层设计
一、概述
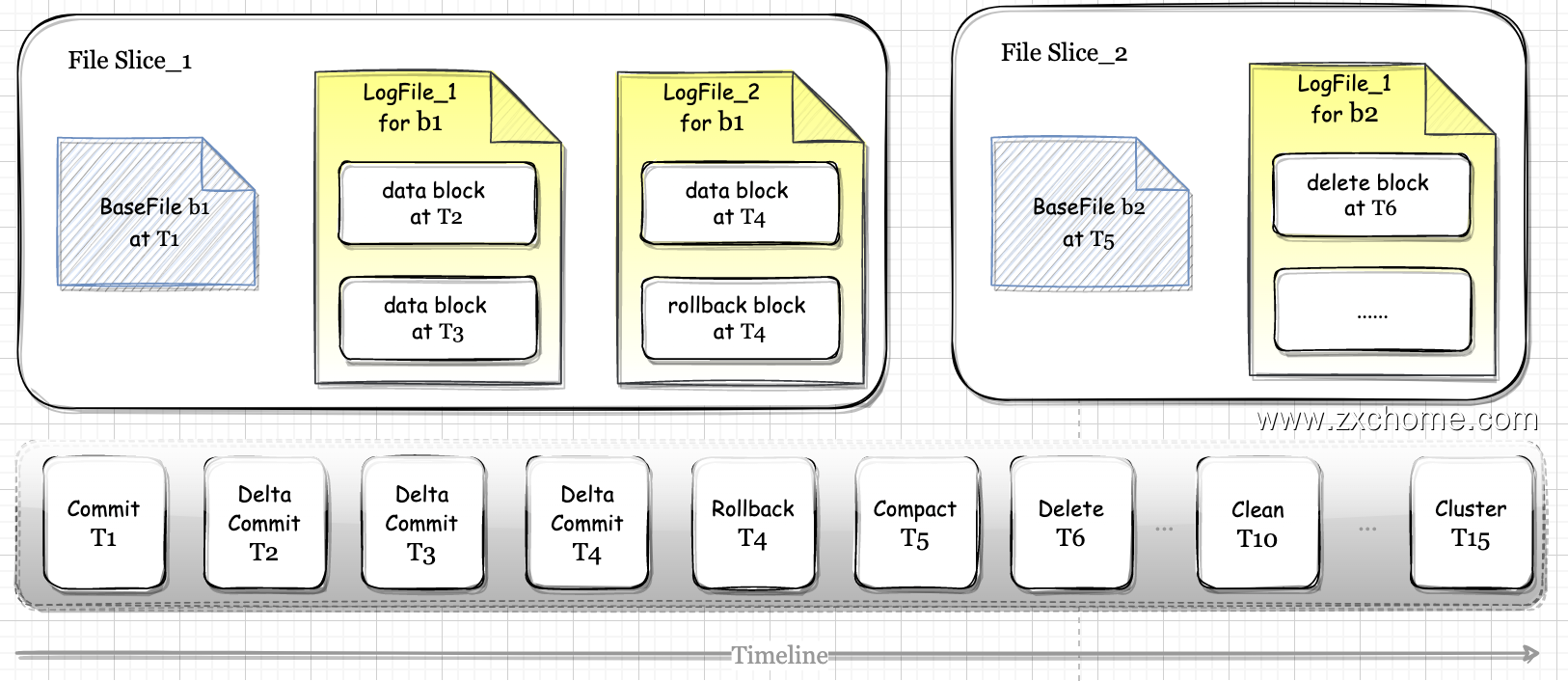
Hudi 数据文件被组织为三层逻辑架构: File Group -> File Slice -> Base/Log Files,文件首先被组织为文件组(File
Group),每个文件组包含多个文件切片(File Slice)。每个切片都包含一个在特定提交时生成的基本文件(Base Files),以及
在 MOR 表中的一组包含对基本文件的更新的日志文件(Log Files)。
二、设计
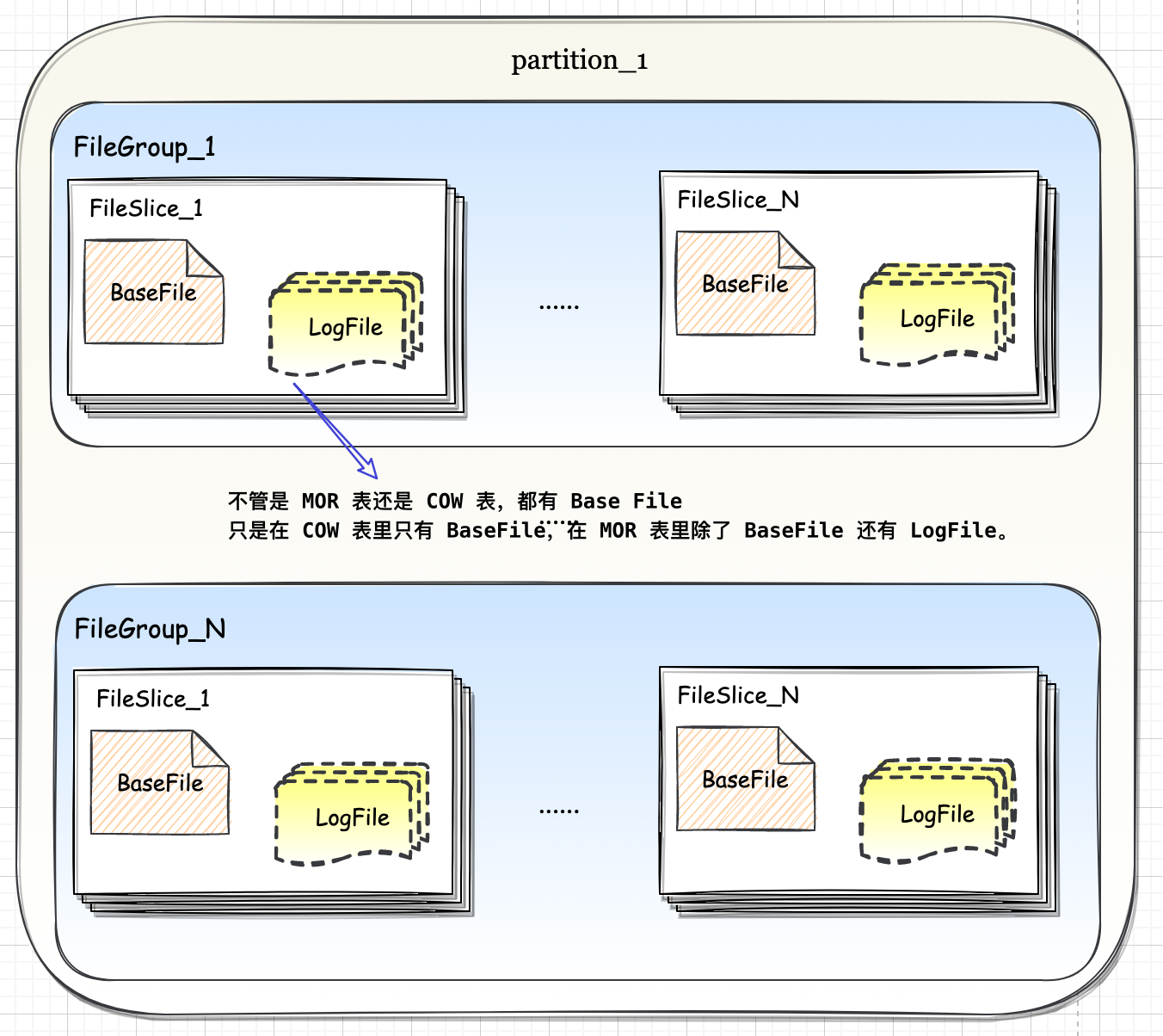
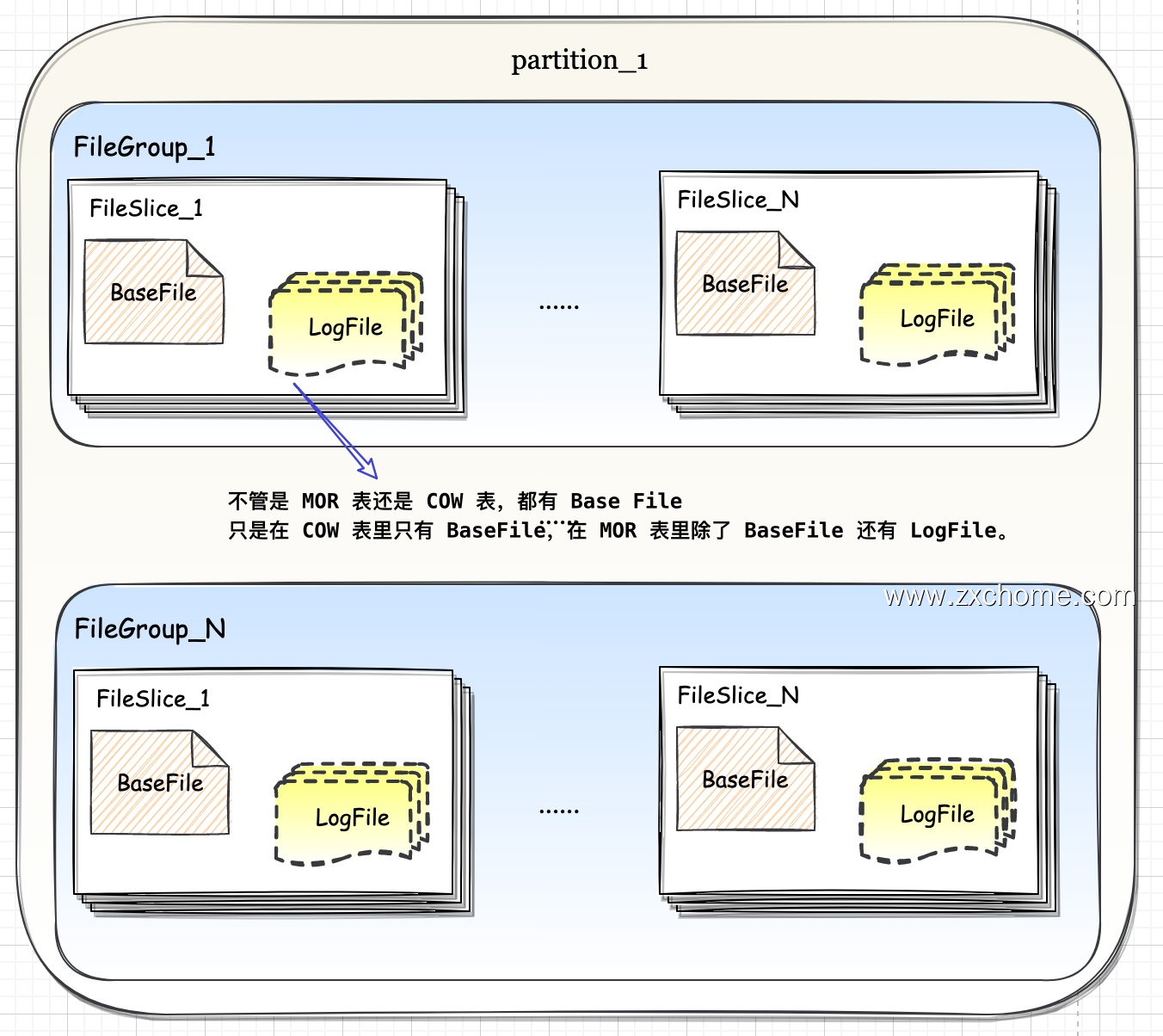
Hudi 文件布局的顶层结构是数据表对应的 base 目录,下一层是各分区目录,分区目录可根据分区列数量嵌套多层。在最底层分区文件夹上,Hudi不再创建子文件夹,全部都是平铺的数据文件,但是这些文件在逻辑上依然有着清晰的层级关系。
顶层的文件集合是 File Group, File Group 下面是 File Slice, File Slice 下面是具体的数据文件。
2.1. 数据文件 Base File / Log file
2.1.1. BaseFile
Base File 是存储 Hudi 数据集的主体文件, 以 Parquet 等列式格式存储。
2.1.2. LogFile
Log File 是在 MOR 表中用于存储变化数据的文件,也常被称作 Delta Log, Log File 不会独立存在,一定会从属于某个 Parquet 格式的 Base File,一个 Base File 和它从属的若干 Log File 所构成的就是一个 File Slice。
不管是 MOR 表还是 COW 表,都有 Base File,只是在 COW 表里只有 BaseFile,在 MOR 表里除了 BaseFile 还有 Log File。
2.2. File Slice
2.2.1. 设计
在MOR 表里,由一个 BaseFile 和若干从属于它的 LogFile 组成的文件集合被称为一个 File Slice。
File Slice 应该说是针对 MOR 表的特定概念,对于 COW 表来说,由于不生成 Log File,所以 File Silce 只包含 BaseFile。 或者说每一个 BaseFile 就是一个独立的 File Sice,为了概念对齐,统一约定 Hudi 文件布局的三层架构。
2.3. File Group
Hudi 的文件布局以 File Goup 为粒度组织,每次会顺序追加写入目标 File Group, 每个 File Group 内部是一个类似 LSM Tree 的结构,Delta 数据在内存中攒批,后以行存 Avro 格式顺序刷到磁盘冲,所以拥有非常好的写入性能。其次类似于 size tired 的 compaction 始终维护一个 base 文件,最大程度提升整个 tree 的查询性能。
2.3.1. 设计
fileId 相同的文件属于同一个 File Group。同一 File Group 下往往有多个不同版本 (instantTime) 的 BaseFile(针对 COW表)或 BaseFile + LogFile 的组合(针对 MOR 表),当 File Group 内最新的 Base File 迭代到足够大时,Hudi 就不会在当前 File Group 上继续追加数据了,而是去创建新的 File Group。
2.3.2. 实现
 微信
微信 支付宝
支付宝