
数据湖-Hudi-源码学习-Kernel-Table 设计
一、概述
Hudi 提供了 Table 的概念,Table 支持 CRUD 数据操作,可以利用现有的大数据集群: 如 HDFS 做数据文件存储,然后使用 SparkSQL 或 Flink 等分析引擎进行数据分析查询。
二、数据操作
HUDI 通过 TableFileSystemView 抽象来管理 table 对应的文件,比如找到所有最新版本 FileSlice 中的 base file (Copy On Write Snapshot 读)或者 base+log files (Merge On Read 读)。通过 Timeline 和 TableFileSystemView 抽象,HUDI 实现了非常便捷和高效的表文件查找。
2.1.数据写入
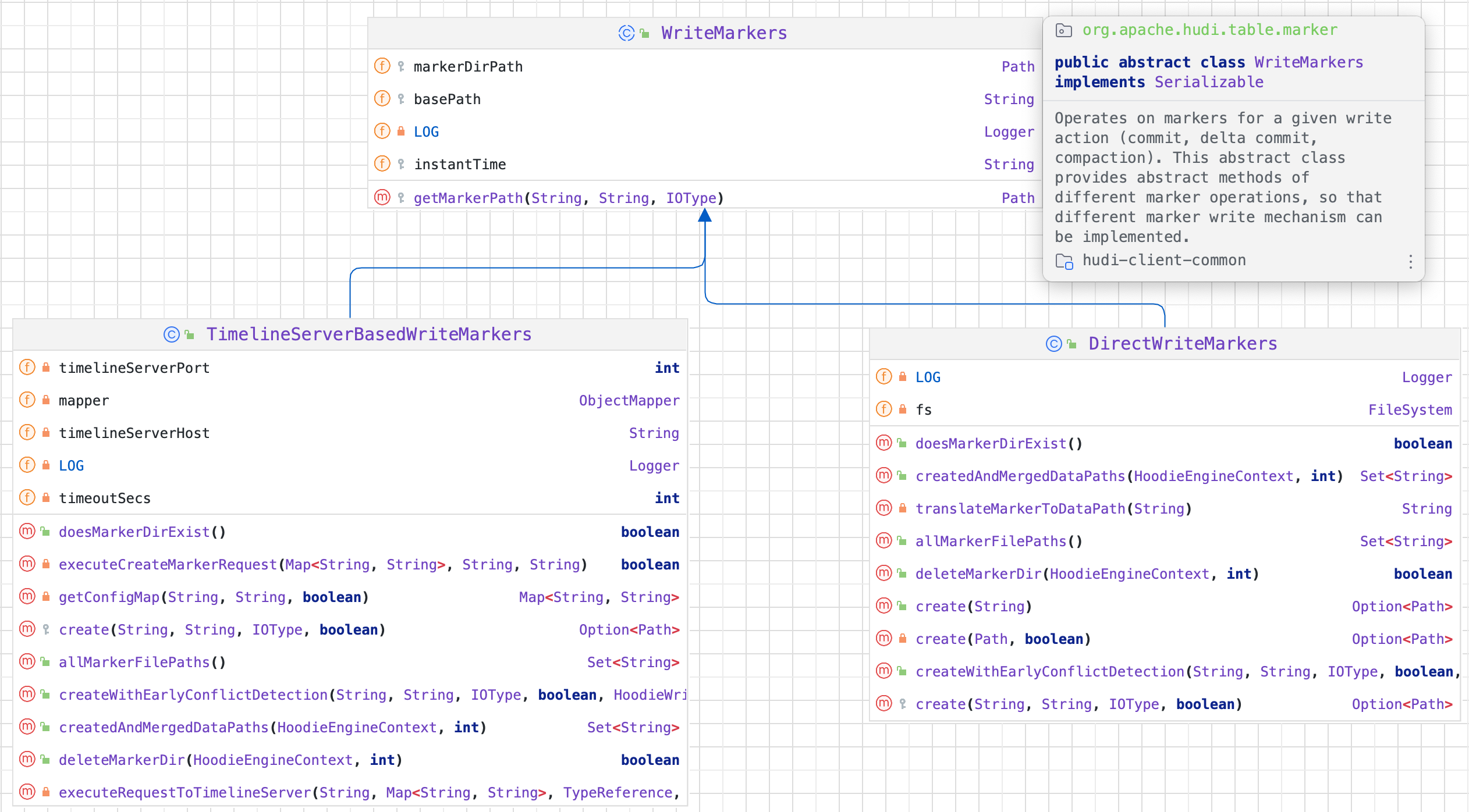
2.1.1. Marker 机制
Hudi 支持在写入时自动清理未成功提交的数据。 Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件。
引用本站文章
数据湖-Hudi-源码学习-Kernel-Table-marker 机制
Joker
2.2.数据查询
2.2.1. Query
2.2.2. 时间旅行
引用本站文章
数据湖-Hudi-源码学习-Kernel-Table-元数据变更
Joker
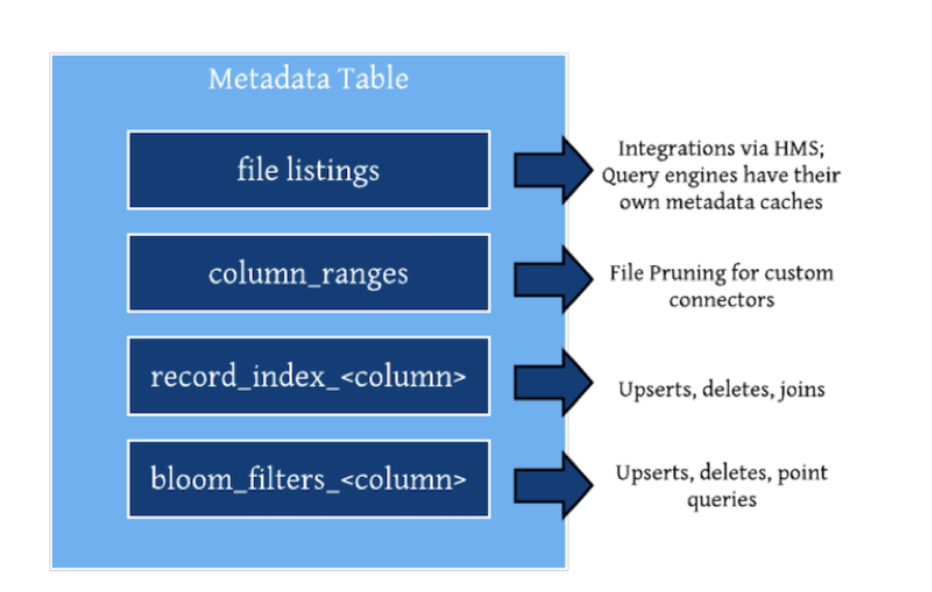
三、元数据操作
3.1. 查询
HoodieTableMetaClient
3.2. 变更
四、事务
Hudi 提供了强大的 ACID 能力。高效的回滚机制能够保证数据一致性和避免“孤儿文件”或中间状态数据文件残留和产生。
引用本站文章
数据湖-Hudi-源码学习-Kernel-Table-事务
Joker
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Joker!
 微信
微信 支付宝
支付宝
相关推荐


评论
ValineTwikoo




