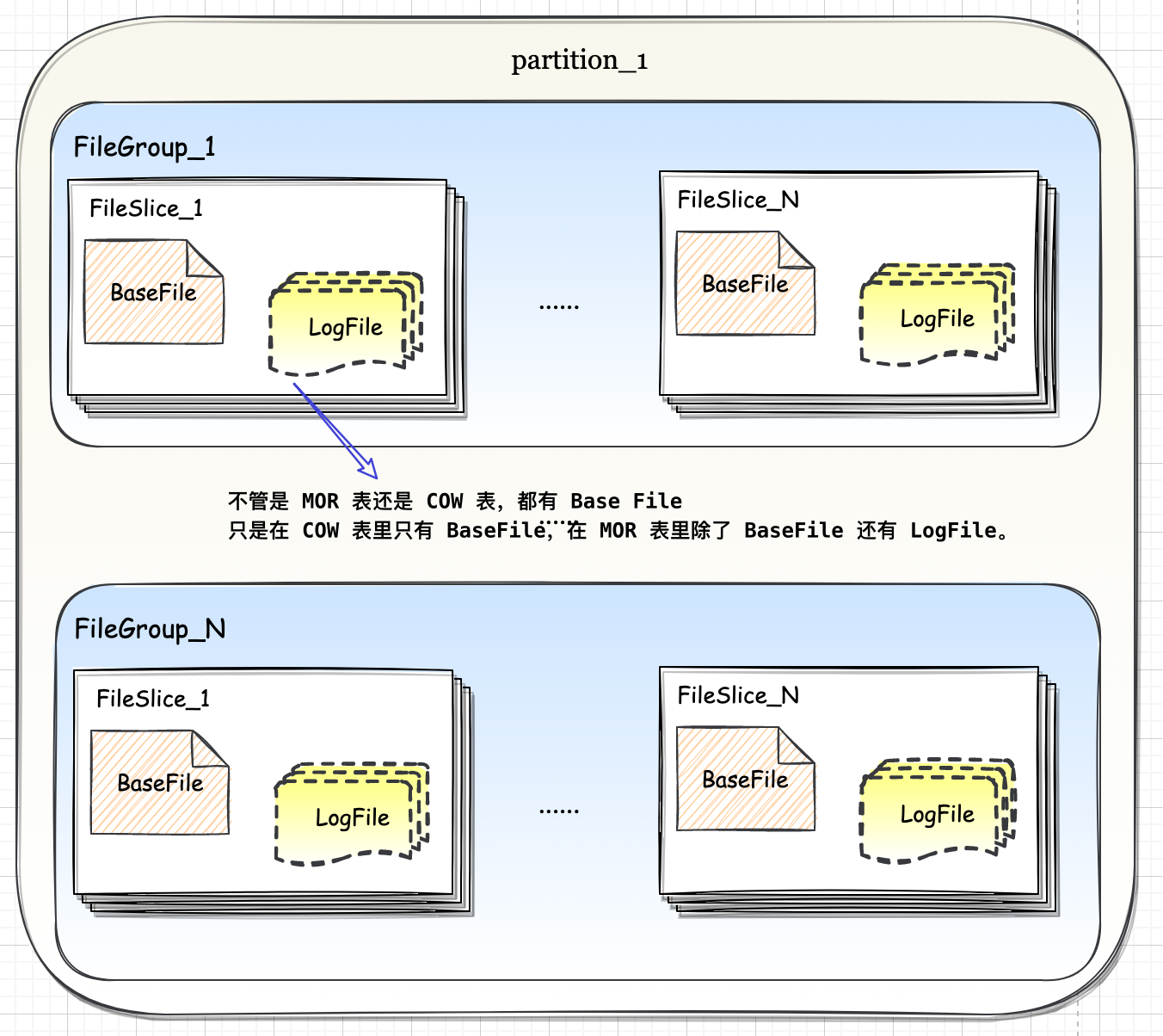
Spark-源码学习-架构设计-DataSource-V2-3.x
一、概述
DataSource API 是 Apache Spark 中非常流行的功能。许多开发人员广泛使用它来将第三方应用程序连接到 Apache Spark。Spark DataSource API 目前有 V1 和 V2 两个版本,V1 在 2.3.x 之前就已经存在了,V2 API 在 Spark 2.3.0 中引入,并在 2.4.0 中进行了修改。在 3.0.0 中,Spark 对 V2 API 进行了重大更改,但是为了向后兼容,V1 被保留不变。
二、设计
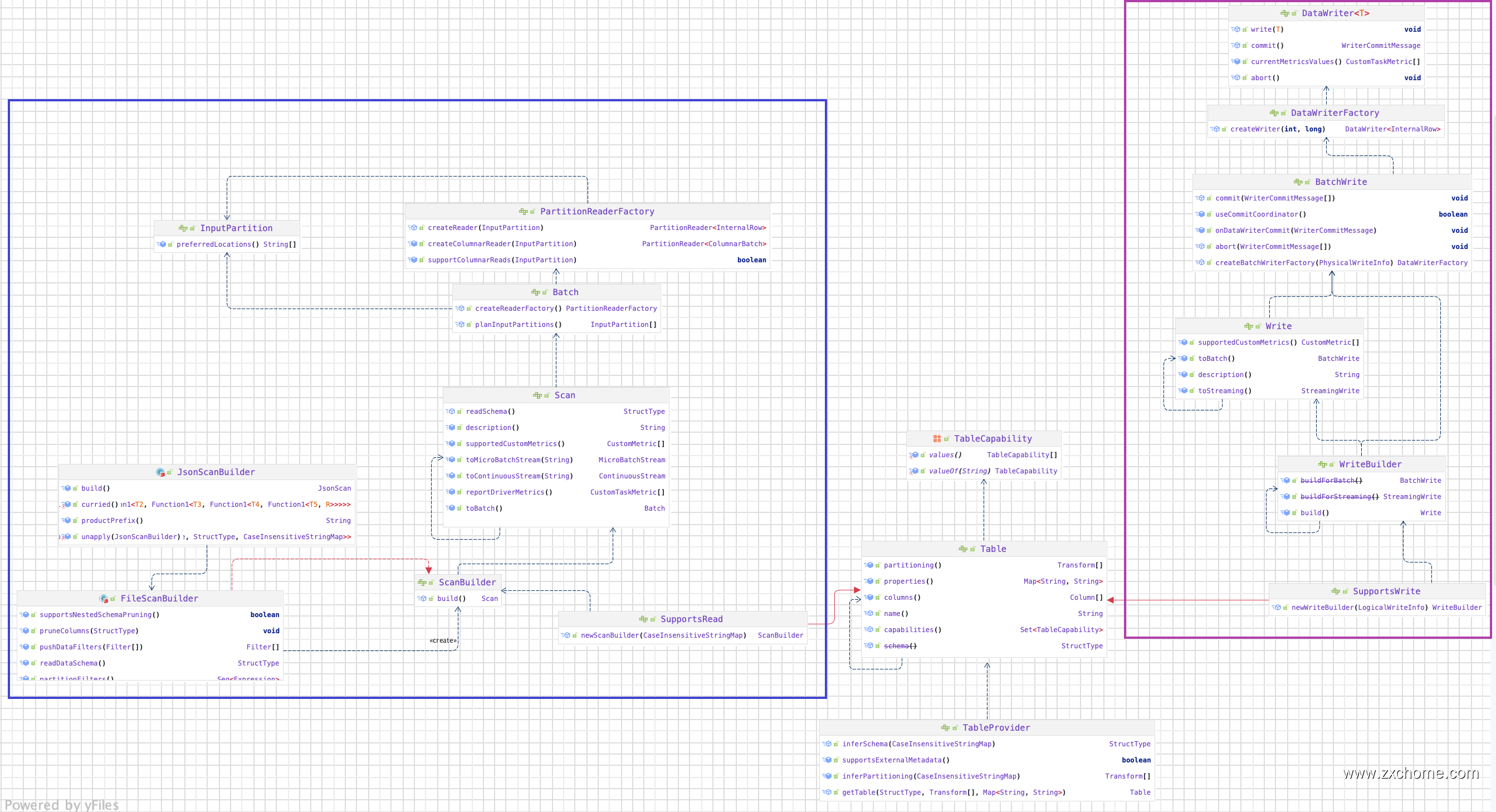
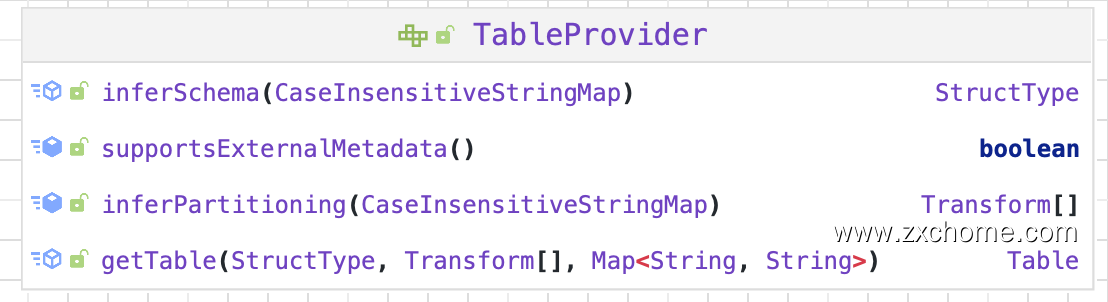
2.1. TableProvider
TableProvider 是一个用于解析表和获取相应元数据的接口。实现此接口将允许用户在 SQL 中使用 Spark 读取自定义数据源。在 Spark 2.4.X 中,数据源 API 中的主要接口是DatasourceV2,所有自定义数据源都需要实现它或其中一个专业化接口,如 ReadSupport 或 WriteSupport。在 3.0.X 中,此接口被删除。引入了一个新的 TableProvider 接口。它是所有不需要支持 DDL 的自定义数据源的基本接口。
2.2. Table
Table 接口定义了一个表示结构化数据的单一逻辑实体。它可以是基于文件系统的数据源的文件/文件夹,Kafka 的 Topic 或 JDBC 数据源的表。它可以与 SupportsRead 和SupportsWrite 混合以添加读取和写入功能。
2.2.1. SupportsRead
2.2.2. SupportsWrite
2.3. Scan
SupportsRead 接口有一个新的 $newScanBuilder()$ API,返回 Scan。Scan 表示数据源扫描的逻辑计划,可以是 Batch、MicroBatchStream 或 ContinuousStream。
2.4. Batch
Batch 接口代表一个物理计划。在运行时,逻辑表扫描会被转换为物理扫描。这是规划数据源分区的接口。它定义了一个工厂,将被发送到执行器以为每个 InputPartition 创建一个PartitionReader。
2.5. InputPartition 和 PartitionReader
在使用所有配置选项、应用运行时优化(如推送下来的过滤器、列剪枝等)后,物理计划即被创建,即Batch。这涉及到创建InputPartition和PartitionReaderFactory。它们会被部署到执行器上。对于每个分区,在每个执行器上都会使用PartitionReaderFactory创建一个PartitionReader实例。PartitionReader的工作是从数据存储中读取数据,使用给定的模式将其转换为 InternalRow。
三、refer
https://mp.weixin.qq.com/s/n6IUb_sDqQM2O98eyo0L7w
 微信
微信 支付宝
支付宝