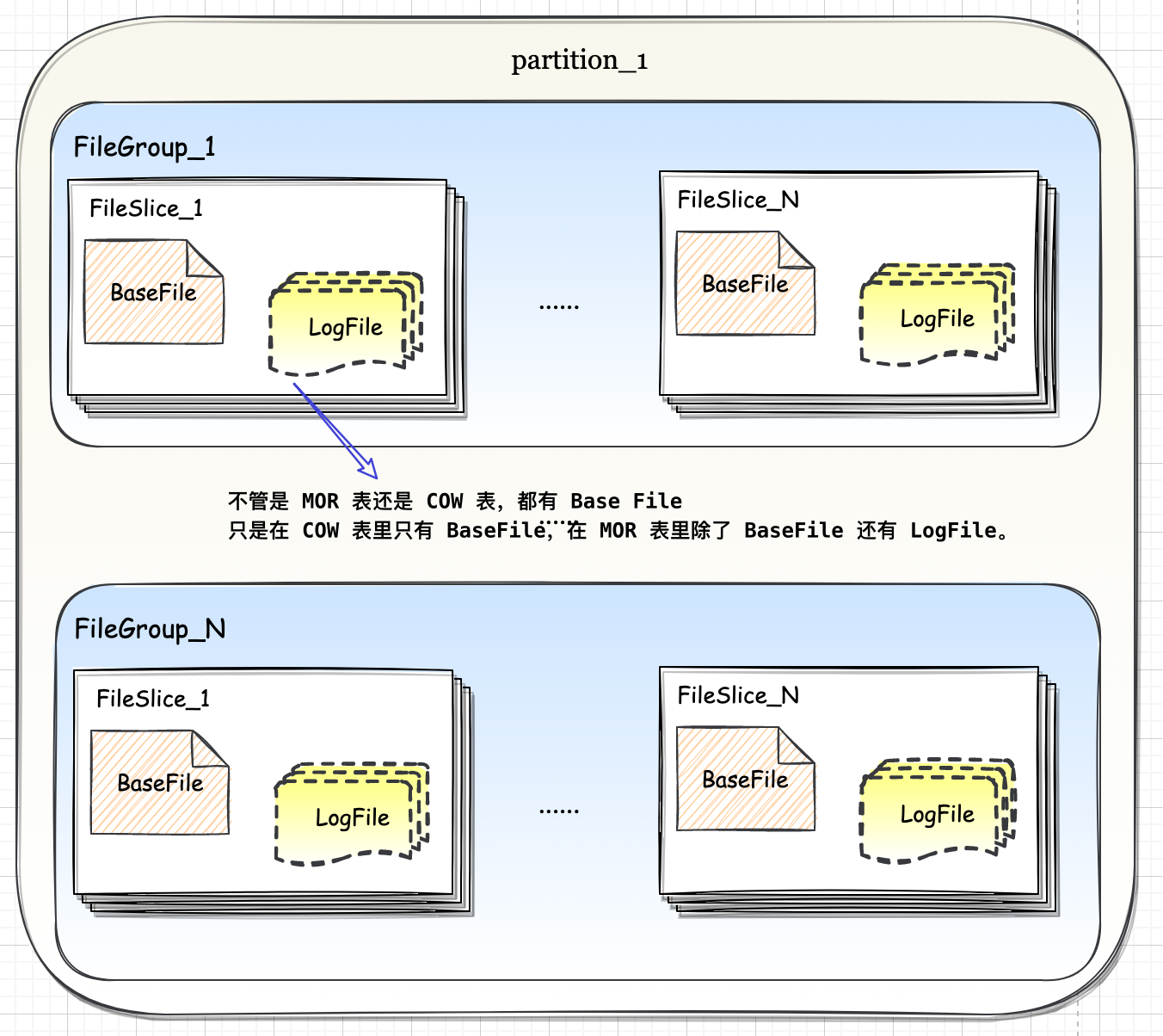
Spark-源码学习-SparkSQL-架构设计-DataSource 体系
一、概述
Spark Datasource API 是一套连接外部数据源和 Spark 引擎的框架,提供一种快速读取外界数据的能力,它可以方便地把不同的数据格式通过 DataSource API 注册成 Spark 的表,然后通过 Spark SQL 直接读取。它可以充分利用 Spark 分布式的优点进行并发读取,通过 SparkSQL Catayst 优化引擎,能够加快任务的执行。
Spark Datasource API 同时提供了一套优化机制,如将列剪枝和过滤操作下推至数据源侧,减少数据读取数量,提高数据处理效率。
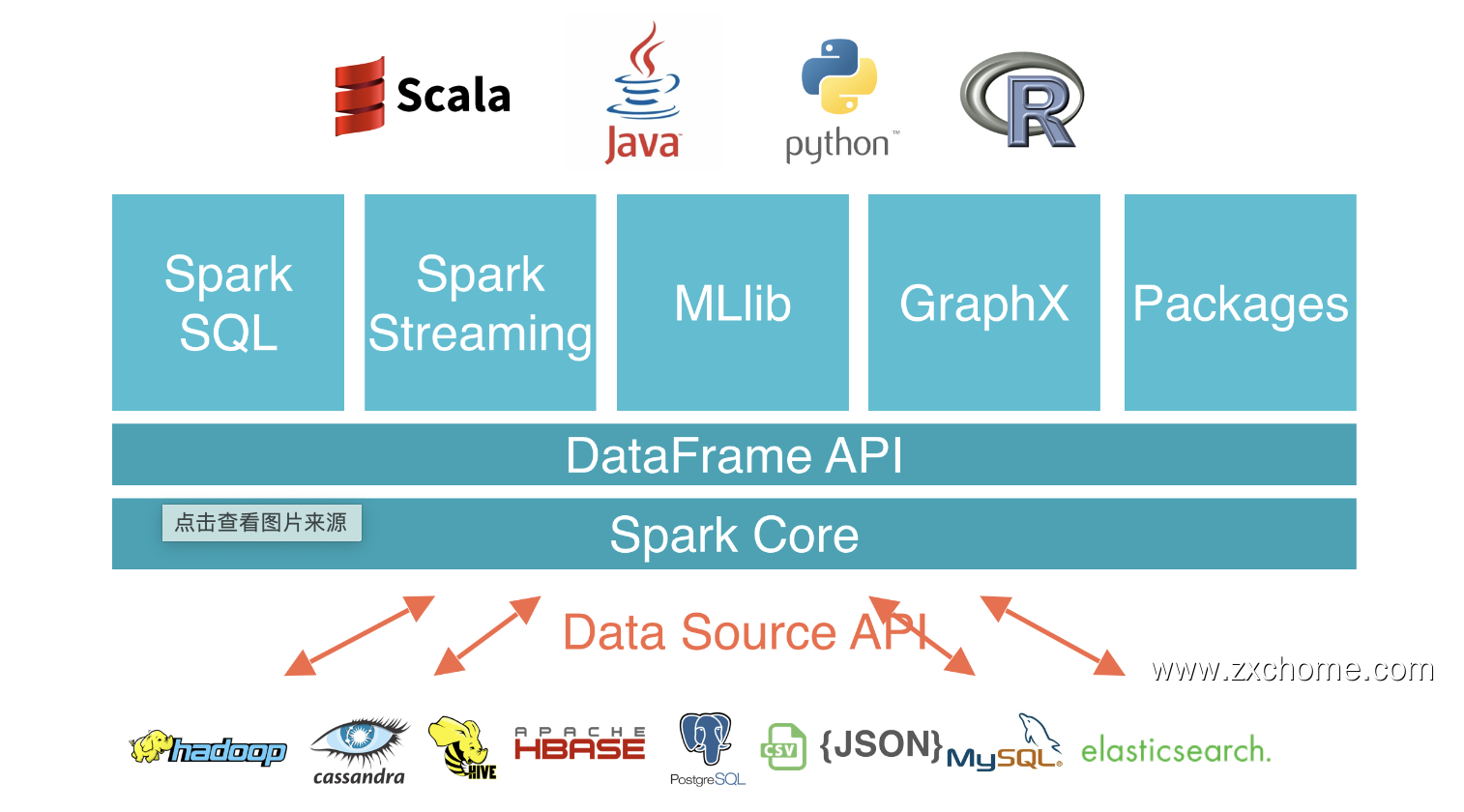
二、设计
DataSource API 是 Apache Spark 中非常流行的功能。许多开发人员广泛使用它来将第三方应用程序连接到 Apache Spark。Spark DataSource API 目前有 V1 和 V2 两个版本,V1 在 2.3.x 之前就已经存在了,V2 API 在 Spark 2.3.0 中引入,并在 2.4.0 中进行了修改。在 3.0.0 中,Spark 对 V2 API 进行了重大更改,但是为了向后兼容,V1 被保留不变。
2.1. V1
2.1.1. 设计
V1 数据源包括以下接口:
数据源
BaseRelation: 代表一个抽象的数据源。
InsertableRelation: 用于插入数据的 BaseRelation
DataSourceRegister: 注册数据源的简称,在使用数据源时不用写数据源的全限定类名,而只需要写自定义的 shortName 即可
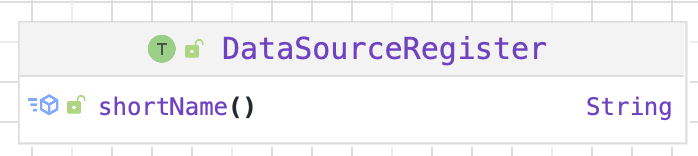
RelationProvider 接口
RelationProvider: 从指定数据源中生成自定义的 relation, $createRelation$ 方法会基于给定的参数生成新的 relation

SchemaRelationProvider: 基于给定的参数和给定的 Schema 信息生成新的 relation
CreatableRelationProvider: 用于将 DataFrame 落地存储
StreamSourceProvider: 产生一个流式的数据源
StreamSinkProvider: 产生一个流式的落地sink
数据扫描接回
- TableScan: 全表数据扫描
- PrunedScan: 返回指定列数据,其他的列数据源不用返回
- PrunedFilteredScan: 指定列的同时,附加一些过滤条件,只返回满足过滤条件的数据
通过实现 RelationProvider 接口,表明该类是一种新定义的数据源,可以供 Spark SQL 取数所用。传入 $createRelation()$ 方法的参数可以用来做初始化,如文件路径、权限信息等。BaseRelation 抽象类则用来定义数据源的表结构,它的来源可以是数据库、Parquet 文件等外部系统,也可以直接由用户指定。该类还必须实现某个
Scan 接口,Spark 会调用 $buildScan()$ 方法来获取数据源的 RDD。
2.1.2. 不足
其输入参数包括 DataFrame/SQLContext,因此 DataSource API 兼容性取决于这些上层的 API。
$createRelation()$ 接收 SQLContext 作为参数; $buildScan()$ 方法返回的是
RDD[Row]类型;而在实现写操作时,$insert()$ 方法会直接接收DataFrame类型的参数。1
2
3trait InsertableRelation {
def insert (data: DataFrame, overwrite: Boolean): Unit
}这些类型都属于较为上层的 Spark API,其中某些类已经发生了变化,如
SQLContext已被SparkSession取代,而DataFrame也改为了Dataset[Row]类型的一个别称。这些改变不应该体现到底层的数据源 API 中。以看到高层次的 API 随着时间的推移而发展。较低层次的数据源 API 依赖于高层次的 API 不是一个好主意
可扩展性不好,并且算子的下推能力受限。
除了 TableScan 接口,V1 API 还提供了 PrunedScan 接口,用来裁剪不需要的字段; PrunedFilteredScan 接口则可以将过滤条件下推到数据源中。如果想添加新的优化算子:如 LIMIT 子句,就需要引入一系列的 Scan 接口组合:
1
2
3
4
5
6
7
8
9trait LimitedScan {
def buildScan(limit: Int): RDD [Row]
}
trait PrunedLimitedScan {
def buildScan(requiredColumns: Array [String], Limit: Int):RDD [Row]
}
trait PrunedFilteredLimitedScan {
def buildScan(requiredColumns: Array [String], filters: Array [Filter], limit: Int): RDD[Row]
}缺乏对列式存储读取的支持
Spark V1 版本的 Data Source API 仅支持以行式的形式读取数据。即使 Spark 内部引擎支持列式数据表示,它也不会暴露给数据源。然而使用列式数据进行分析会提升性能,Spark 没必要读取列式数据的时候把其转换成行式,然后再在 Spark 内部引擎里面转换成列式进行分析~
缺乏分区和排序信息
对于支持数据分区的数据源,如 HDFS、Kafka 等,V1 API 没有提供原生的支持,因而也不能利用数据局部性(Data Locality)
写操作不支持事务
Spark 任务是有可能失败的,使用 V1 API 时就会留下部分写入的数据。对于 HDFS 可以用
_SUCCESS来标记该次写操作是否执行成功。但这一逻辑需要最终用户来实现,而 V2 API 则提供了明确的接口来支持事务性的写操作。不支持流处理
越来越多的场景需要流式处理,但是 DataSource API V1 不支持这个功能,导致像 Kafka 这样的数据源必须调用一些专用的内部 API 或者独自实现。
2.1.3. 自定义
2.2. V2
Data Source V2 API 最早在 Spark 2.3 提出,V2 API 使用了一个标记性的 DataSourceV2 接口,实现接口的类还必须实现 ReadSupport 或 WriteSupport,用来表示自身支持读或写操作。ReadSupport 接口中的方法会被用来创建 DataSourceReader 类,同时接收到初始化参数;该类继而创建 DataReaderFactory 和 DataReader 类,后者负责真正的读操作,接口中定义的方法和迭代器类似。此外,DataSourceFeader 还可以实现各类 Support 接口,我明自己支持某些优化下推操作,如裁剪字段、过滤条件等。WriteSupport API 的层级结构与之类似。这些接口都是用 Java 语言编写,以获得更好的交互支持。
2.2.1. 设计
2.2.2. 自定义
2.3. V2 Improvement
Data Source V2 API 是 Spark3 引入的一个重要特性,最早在 Spark 2.3 提出,在 Spark 3.0 被重新设计,具有非常良好的扩展性,使得 API 可以一直进化,每个版本都新增了大量的 API。
下图用多种颜色标记不同的 Spark 版本提供的 Data Source V2 API:

2.2.1. 设计
DataSource API V2 版本旨在提供一个高性能的,易于维护的,易于扩展的外部数据源接口。
在 Spark 2.4.x 中,数据源 API 中的主要接口是 DatasourceV2,所有自定义数据源都需要实现它或其中一个专业化接口,如 ReadSupport 或 WriteSupport。在 3.0.x 中,此接口被删除。引入了一个新的 TableProvider 接口。它是所有不需要支持 DDL 的自定义数据源的基本接口。
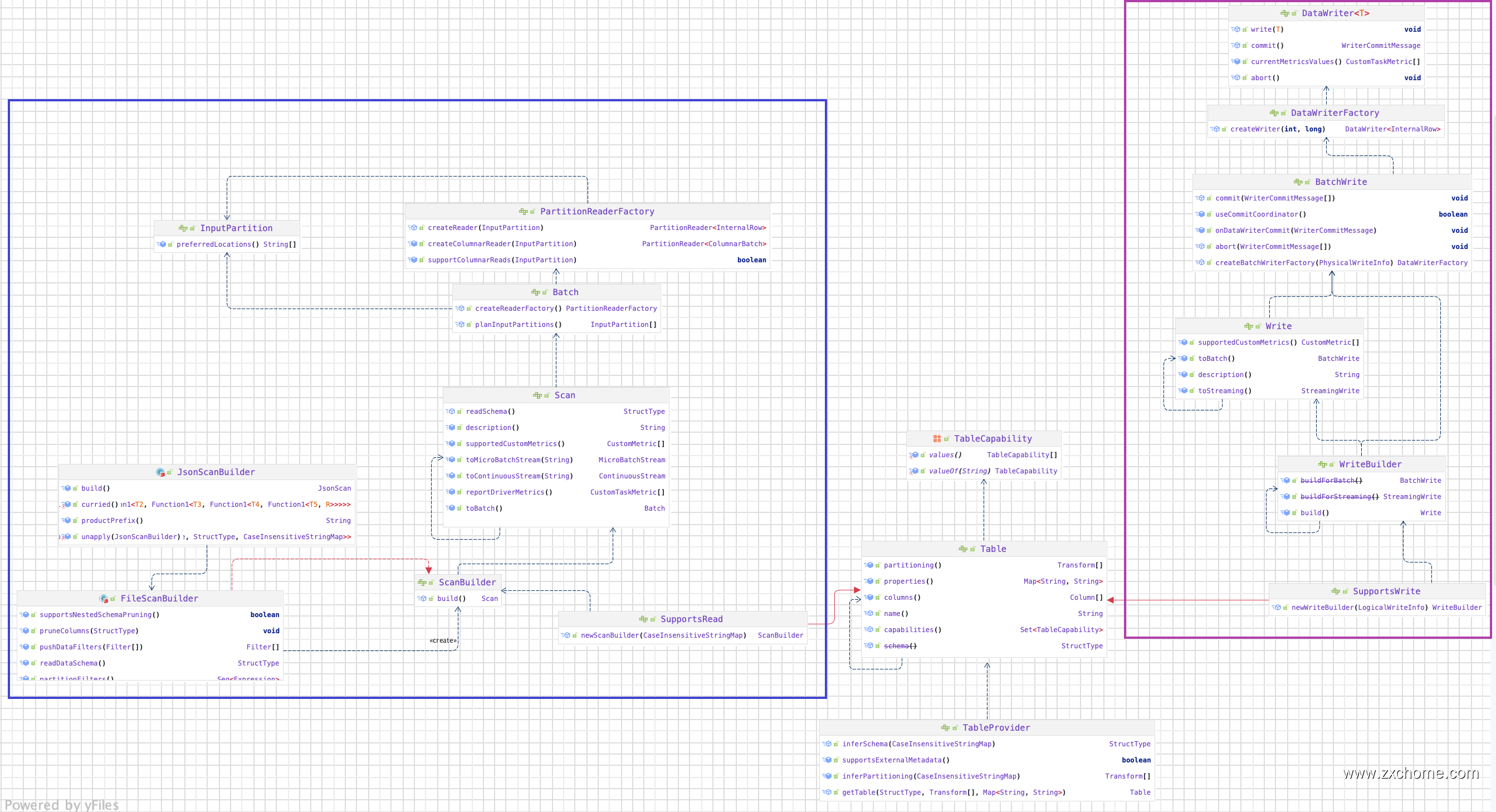
2.2.2. 工作流程
2.2.3. 自定义
三、工作流程
3.1. 读取数据
$format()$ 方法传入 source 字符串
1
spark.write.format("hudi")
根据 source 字符串 查找数据源
$DataSource.lookupDataSource()$ 找到 source 对应的 DataSource 类(一般包括 FileFormat 和 RelationProvider 两类)
引用本站文章Spark-源码学习-架构设计-DataSource 体系-加载数据Joker$DataSource.resolveRelation()$ 会根据 DataSource 类型创建 BaseRelation(一般包括 HadoopFsRelation 和继承 BaseRelation 且实现以下接口的类: TableScan、PrunedScan、PrunedFilteredScan、InsertableRelation、CatalystScan )。
$SparkSession.baseRelationToDataFrame()$ 将 BaseRelation 传入创建 LogicalRelation 逻辑计划,并利用 LogicalRelation 创建 DataSet。
FileSourceStrategy、DataSourceStrategy、DataSourceV2Strategy、InMemoryScans 将 LogicalRelation 逻辑计划转换为物理计划,生成具体的 DataSourceRDD
DataSourceStrategy
引用本站文章Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-DataSourceStrategyJokerDataSourceV2Strategy
对 DataSourceV2 的相关 LogicalPlan 进行转换处理
引用本站文章Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块-Strategy-DataSourceV2StrategyJokerInMemoryScans
将 InMemoryRelation 的逻辑计划转换为 InMemoryTableScanExec 的物理计划
FileSourceStrategy
与 DataSourceV2Strategy 类似,不过是处理的来自文件的数据源,这里主要是处理 Filter 的下推处理:
- partition keys ,减少需要读取的目录
- bucket keys only, 减少需要读取的文件
- keys store in the data, 跳过文件中不需要读取的数据
$compute()$ 函数实现真正的读取逻辑。
3.2. 写入数据
 微信
微信 支付宝
支付宝