
数据湖-Hudi-源码学习-Query Engines-Spark-Upsert
一、概述
二、Spark 引擎层和 Hudi 对接
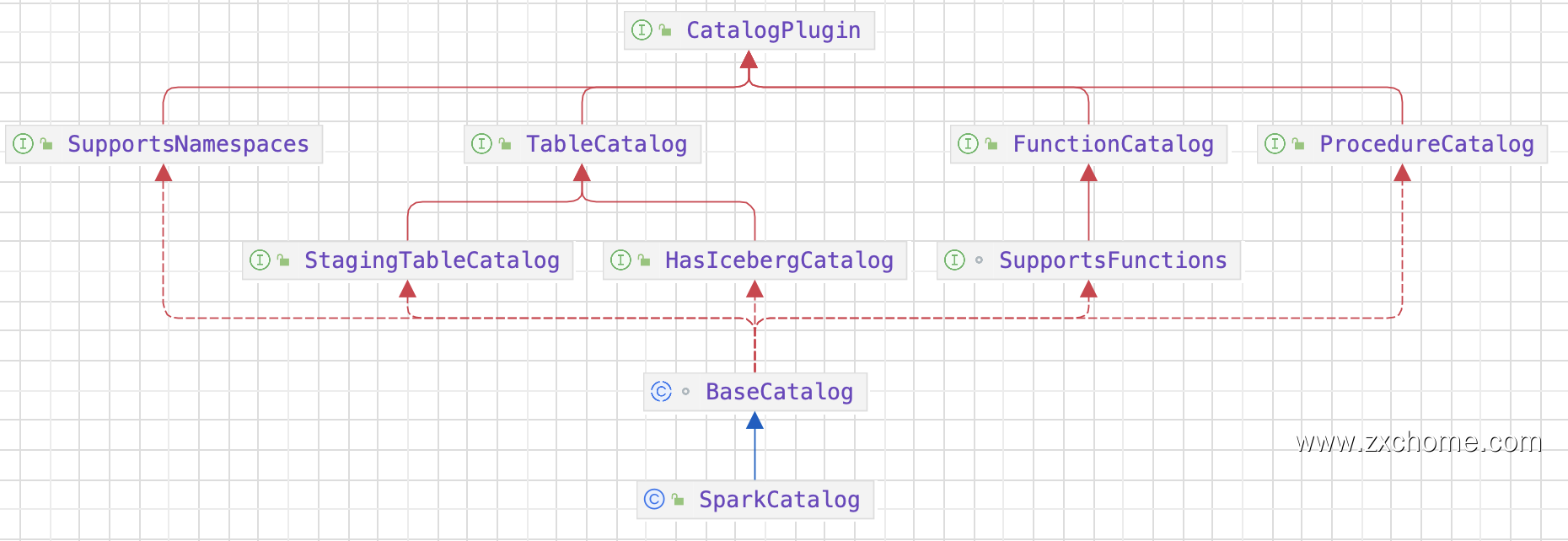
2.1. Catalog
2.1.1. Spark Catalog API
2.1.2. Hudi Catalog API
2.1.3. 集成
2.2. Spark DataSource V2
三、提交数据
在构造好 spark 的rdd 后调用 df.write.format("hudi") 方法执行数据的写入,实际会调用 Hudi 源码中的 $SparkRDDWriteClient.upsert$ 方法实现。

1 | public JavaRDD<WriteStatus> upsert(JavaRDD<HoodieRecord<T>> records, String instantTime) { |
三、构造 HoodieTable

在执行任务前 Hudi 会创建 HoodieTable 对象
1 | HoodieTable<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>> table = |

3.1. 构造 HoodieTableMetaClient

3.2. 构造 SparkUpgradeDowngrade
3.3. validateTableProperties
3.4. getTableAndInitCtx
四、验证 Schema

五、preWrite()

六、构造 HoodieWriteMetadata
在执行任务前 Hudi 会创建 HoodieWriteClient 对象,并构造 HoodieTableMetaClient 调用 $startCommitWithTime$ 方法开始一次事务。在开始提交前会获取 .hoodie 目录下的元数据信息,判断上一次写入操作是否成功,判断的标准是上次任务的快照元数据有xxx.commit后缀的元数据文件。如果不存在那么Hudi 会触发回滚机制,回滚是将不完整的事务元数据文件删除,并新建xxx.rollback元数据文件。如果有数据写入到快照parquet 文件中也会一起删除。
1 |
|
七、postWrite()

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Joker!
 微信
微信 支付宝
支付宝
相关推荐
评论
ValineTwikoo




