
数据湖-Hudi-源码学习-Query Engines-Spark-Query
一、概述
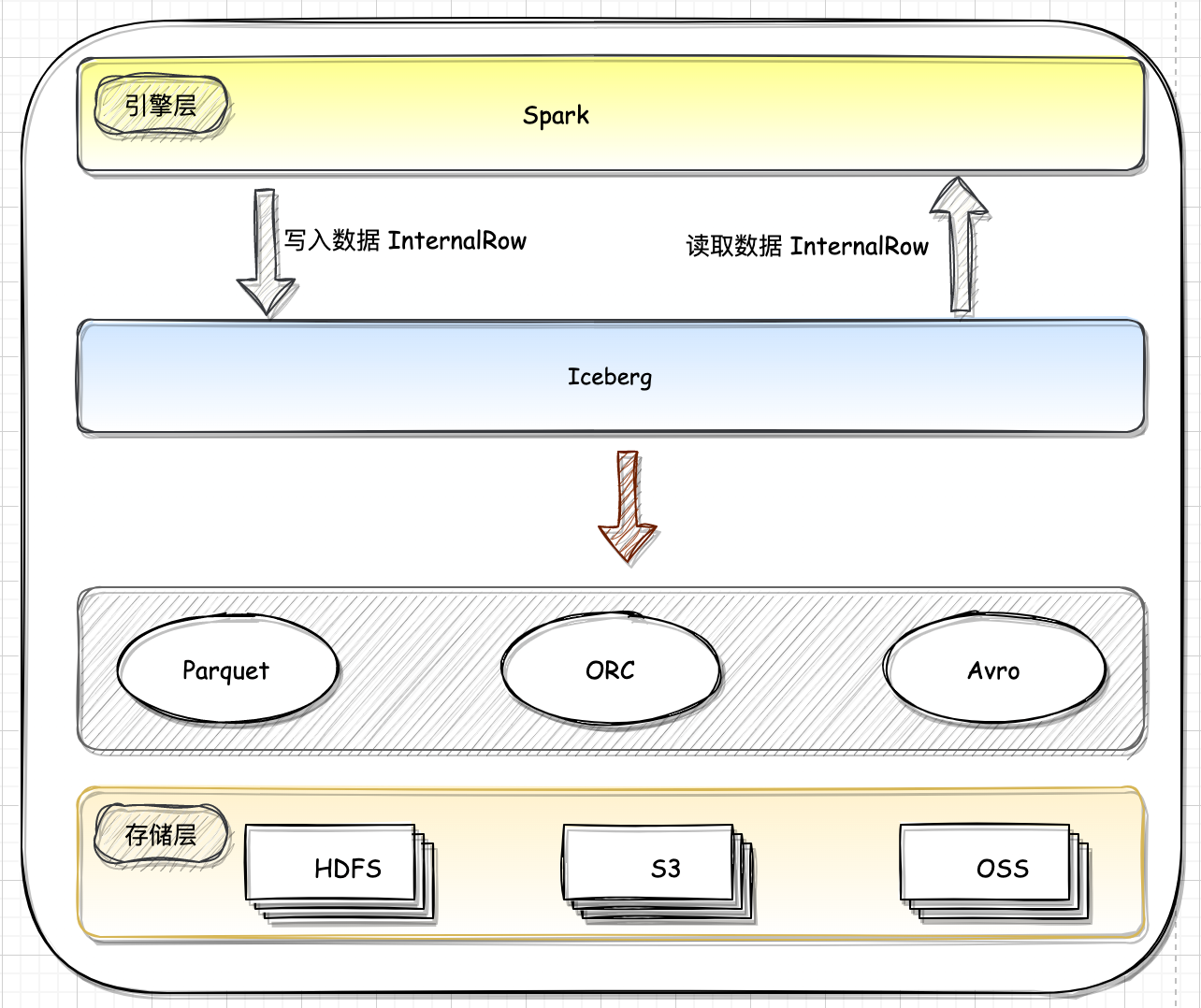
二、Spark 引擎层和 Hudi 对接
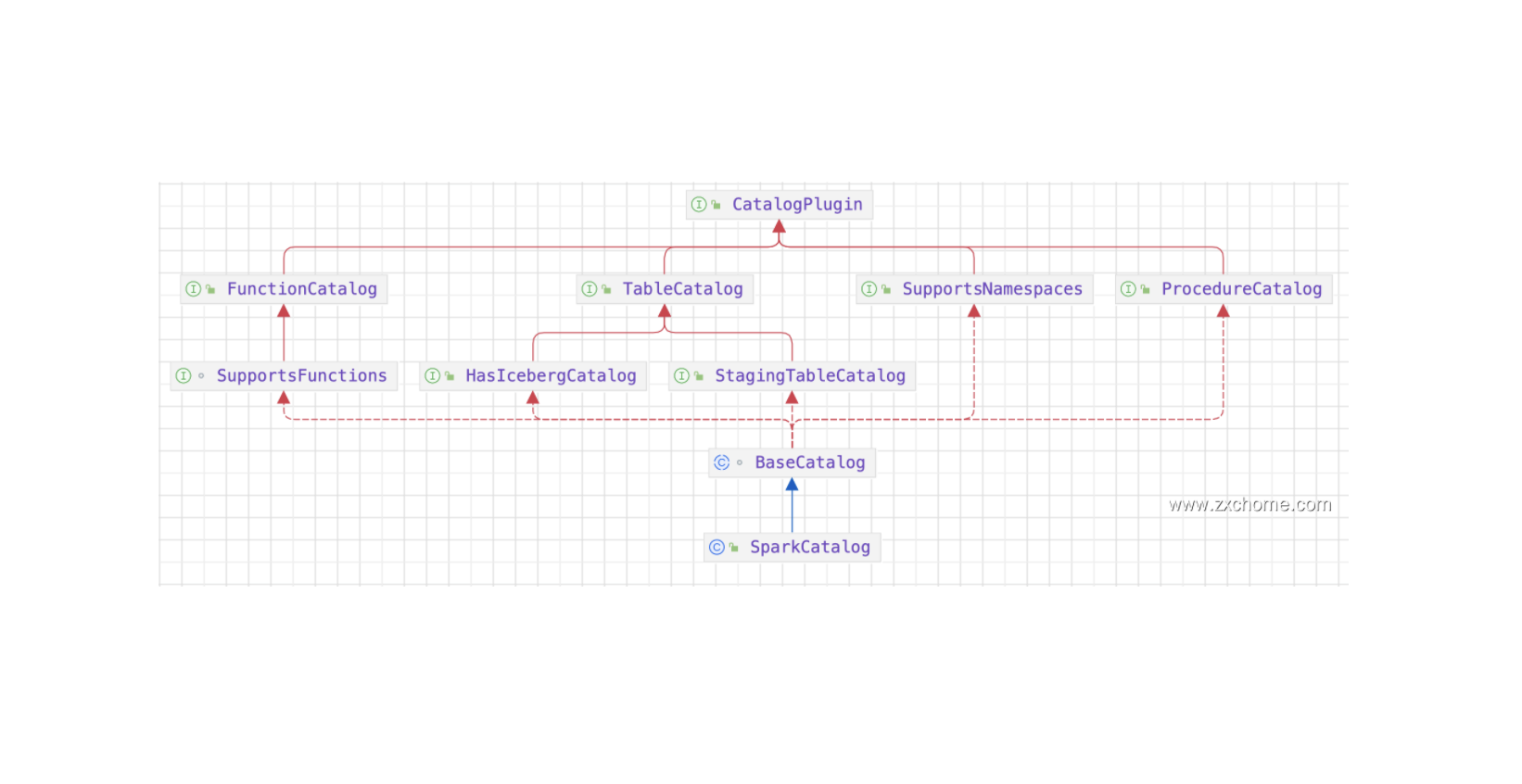
2.1. Catalog
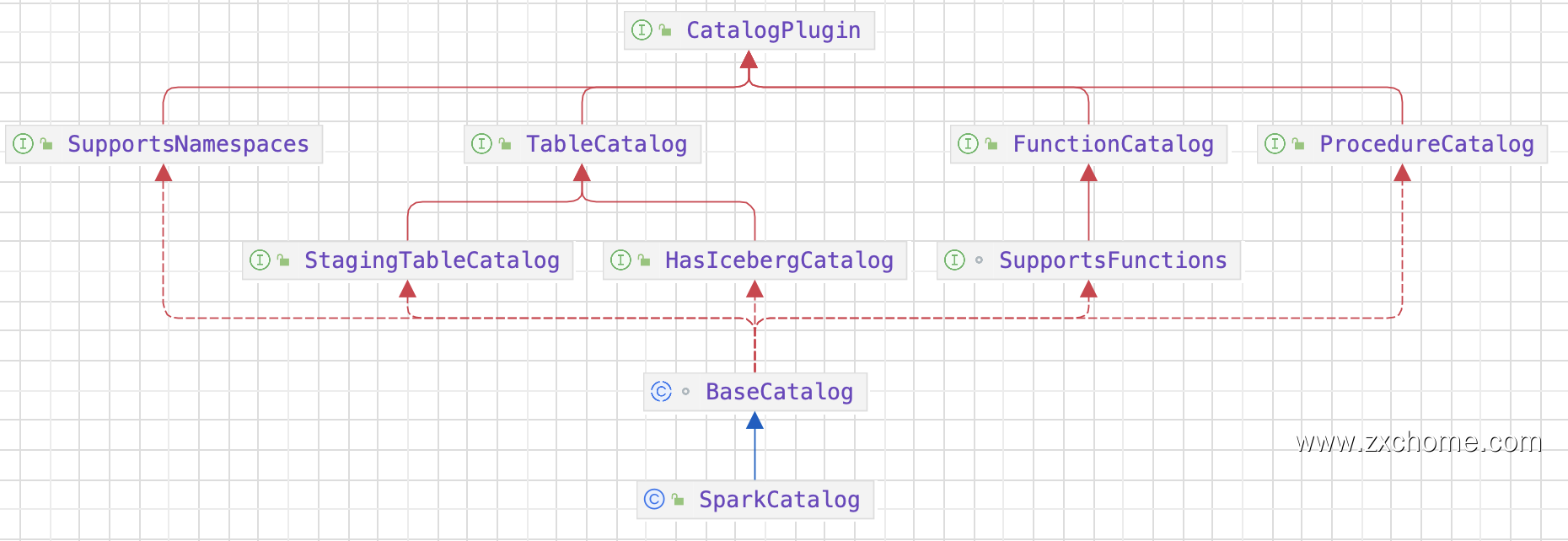
2.1.1. Spark Catalog API
2.1.2. Hudi Catalog API
2.1.3. 集成
2.2. Spark DataSource V2

三、实现
3.1. **快照查询 Snapshot Query **
只能查询到给定 COMMIT 或 COMPACTION 后的最新快照数据。
3.1.1. COW
Copy-On-Write 表,Snapshot Query 能够查询到: 已经存在的列式格式文件(Parquet 文件)
3.1.2. MOR
Merge-On-Read 表,Snapshot Query 能够查询到: 通过合并已存在的 Base 文件和增量日志文件得到的数据(Parquet 文件 + Avro 文件)。
3.2. 读取优化查询 Read Optimized Query
3.2.1. COW
Copy-On-Write 表,和快照查询一样。
3.2.2. MOR
Merge-On-Read 表,只能查询到给定的 COMMIT/COMPACTION 之前所限定范围的最新数据。即只能读到列式格式中的最新数据。这种方式不需要合并行和列数据(通俗地说就是上面的快照查询去掉了“行”的部分,只返回“列”的部分),所以拥有比快照查询更好的性能,但是实时性方面会打折扣,因为少读了未合并的数据。

3.3. 增量查询 Incremental Query
只能查询到最新写入 Hudi 表的数据,也就是给定的 COMMIT/COMPACTION 之后的最新数据。
3.3.1. COW
Copy-On-Write 表:在给定的开始,结束即时时间范围内,对最新的基本文件执行查询(称为增量查询窗口),同时仅使用 Hudi 指定的列提取在此窗口中写入的记录。
3.3.2. MOR
Merge-On-Read 表,查询是在增量查询窗口中对最新的文件片执行的,具体取决于窗口本身,读取基本块或日志块中读取记录的组合。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Joker!
 微信
微信 支付宝
支付宝
相关推荐
评论
ValineTwikoo




