
数据湖-Hudi-源码学习-Query Engines-Spark
一、概述
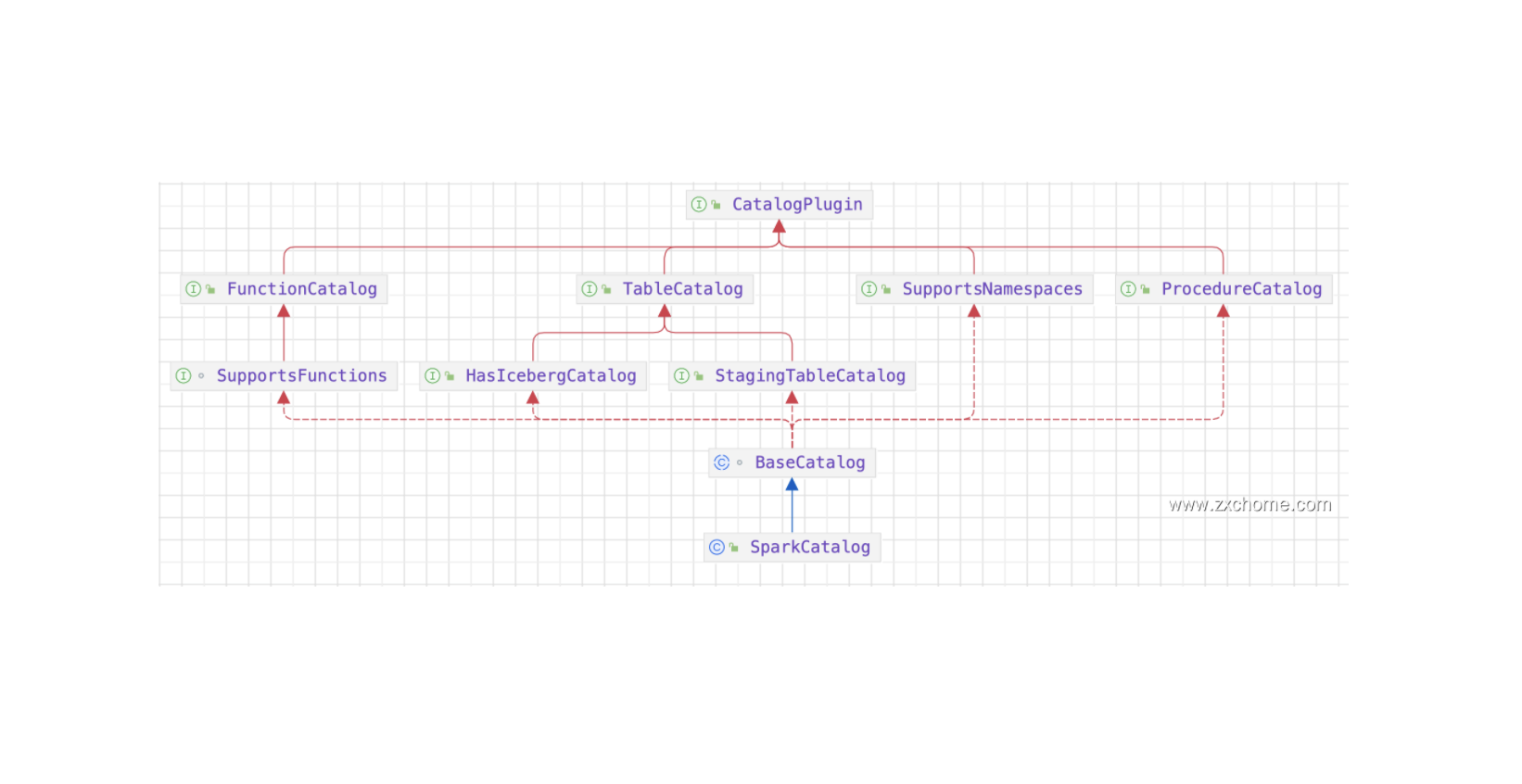
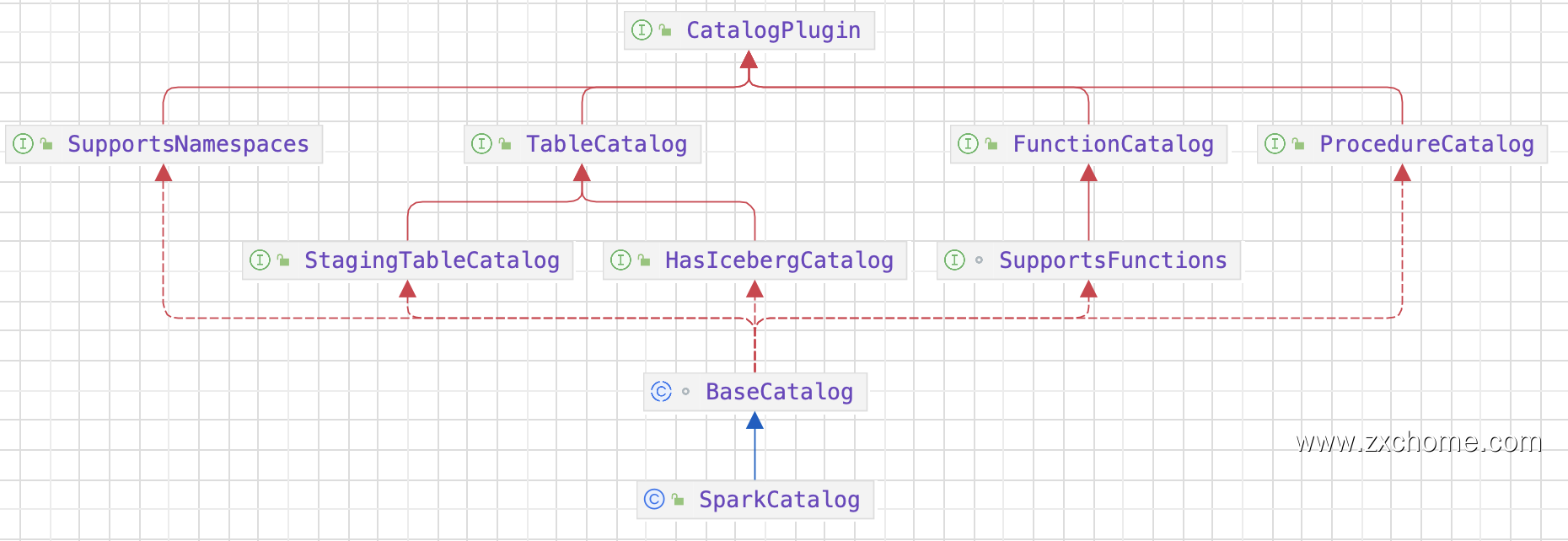
Iceberg 的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。Flink 和 Iceberg 的集成可以提供更好的数据管理和分析功能,可以更好地管理和分析大型数据集,Spark 基于 DataSourcev2 API 实现读写 Iceberg。

二、读数据
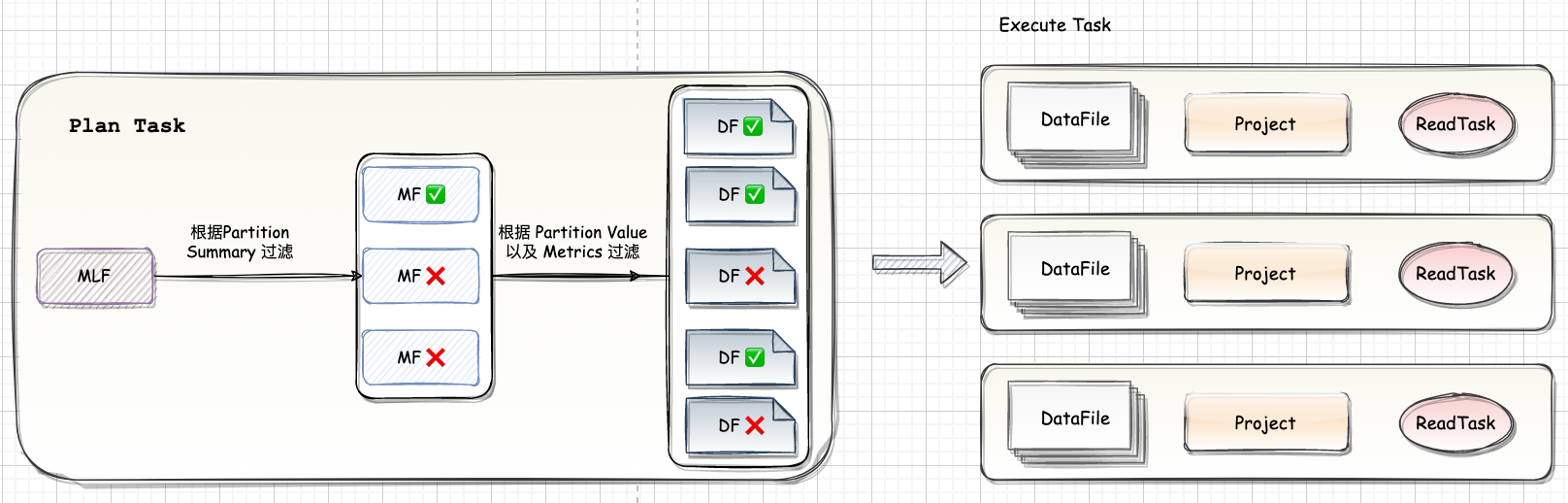
Spark 在读 Iceberg 表时通过读取 Metadata 文件可以实现高效的文件过滤:
首先根据 Partition Summary 进行文件过滤。如图,读取 Snapshot 对应的 ManifestFile List 可以读到三个
ManifestFile然后根据 where 条件加上 Partition Summary 的 min-max 信息可以过滤掉两个 ManifestFile。
根据每个 DataFile 的 Partition Value 和 metrics 信息做进一步的过滤,最后只有三个文件需要进行真正的读取。
执行时 Spark 会将大的文件拆分成多个 task,小的文件合并成一个 task,每个 task 对应一到多个 DataFile。因为 Iceberg 支持 Schema Evolution,要读取的 DataFile 的 schema 和当前表的 schema 可能不匹配,因此需要做一个 Projection 来保证返回的数据的 Schema 和当前表的 Schema 相匹配。

引用本站文章
数据湖-Iceberg-源码学习-Query Engines-Spark-读数据
Joker
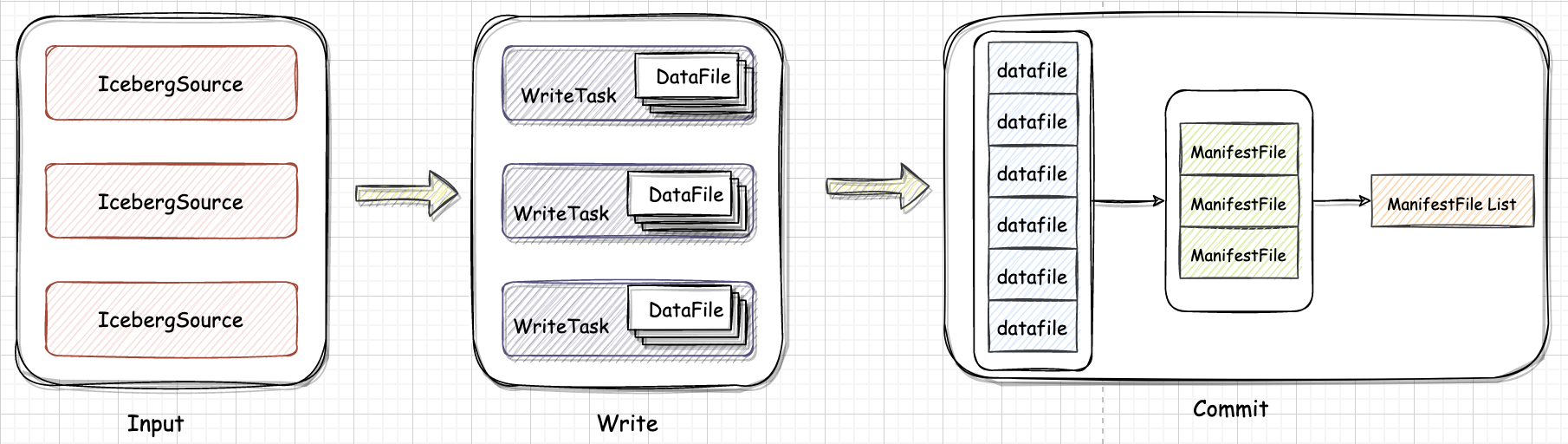
三、写数据
Spark 数据读入会根据 task plan 生成多个 WriteTask,每个 WriteTask 会写成一到多个 DataFile。

引用本站文章
数据湖-Iceberg-源码学习-Query Engines-Spark-写数据
Joker
四、删除数据
引用本站文章
数据湖-Iceberg-源码学习-Query Engines-Spark-删除数据
Joker
五、修改数据
引用本站文章
数据湖-Iceberg-源码学习-Query Engines-Spark-修改数据
Joker
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Joker!
 微信
微信 支付宝
支付宝
相关推荐
评论
ValineTwikoo




