Spark-源码学习-架构设计-DataSource 体系-FileFormat-Parquet-reader-VectorizedValuesReader
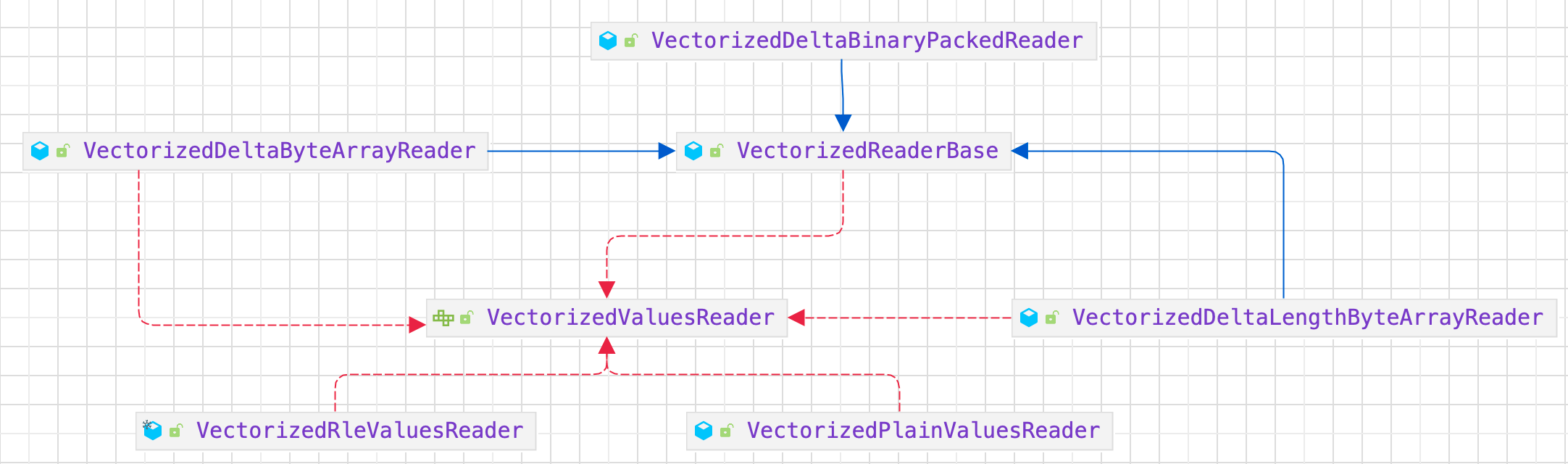
根据数据编码方法,VectorizedColumnReader 会创建相应的 VectorizedValuesReader 实现实例来读取和解码数据。
目前,VectorizedValuesReader 有两个版本: VectorizedRleValuesReader(用于 RLE/Bit-PackingHybrid 编码) 和 VectorizedPlainValuesReader(用于普通编码)。
目录解码逻辑封装在 VectorizedColumnReader 的 $decodeDictionaryIds()$ 方法中,页面数据的读取和解码以指定的批次大小批量进行。批次中读取和解码的列数据将写入 ColumnVector 并返回 VectorizedParquetRecordReader,然后由上游调用者与 ColumnBatch 中的其他 ColumnVector 一起使用。
https://dataninjago.com/category/deep-dive-parquet-for-spark/
https://www.waitingforcode.com/apache-spark-sql/vectorized-operations-apache-spark-sql/read
https://mp.weixin.qq.com/s/GIIgdmupbbFV89kB2Gv3nQ
https://developer.aliyun.com/article/992713
Spark SQL 中读取 Parquet 文件的过程入口点是 DataSourceScanExec,然后是 ParquetFileFormat,最后是 VectorizedParquetReactorReader。VectorizedParquetReactorReader 是读取 Parquet 文件非常重要的类,VectorizedParquetReactorReader 可以通过把算子下推转换成 ParquetFilters 来过滤掉一些无用的 Row Group。
同时,VectorizedParquetReactorReader 为每个目标列构建 VectorizedColumnReader,而这些 VectorizedColumnReader 是一起以批量的形式读取数据的。
比如想读取三列的数据,VectorizedParquetReactorReader 会构造三个 VectorizedColumnReader。
 微信
微信 支付宝
支付宝