
Spark-源码学习-架构设计-DataSource 体系-FileFormat-Parquet-reader-VectorizedParquetRecordReader
一、概述
https://mp.weixin.qq.com/s/TVkuyBwCQmIfSR3VYFrGaQ
https://www.learntospark.com/2020/02/how-to-read-and-write-parquet-in-apache-spark.html
https://www.mianshigee.com/note/detail/221583thf/
https://www.sohu.com/a/507896675_120099884
https://mp.weixin.qq.com/s/HH8s6o7C50uaq2hs4axd0A
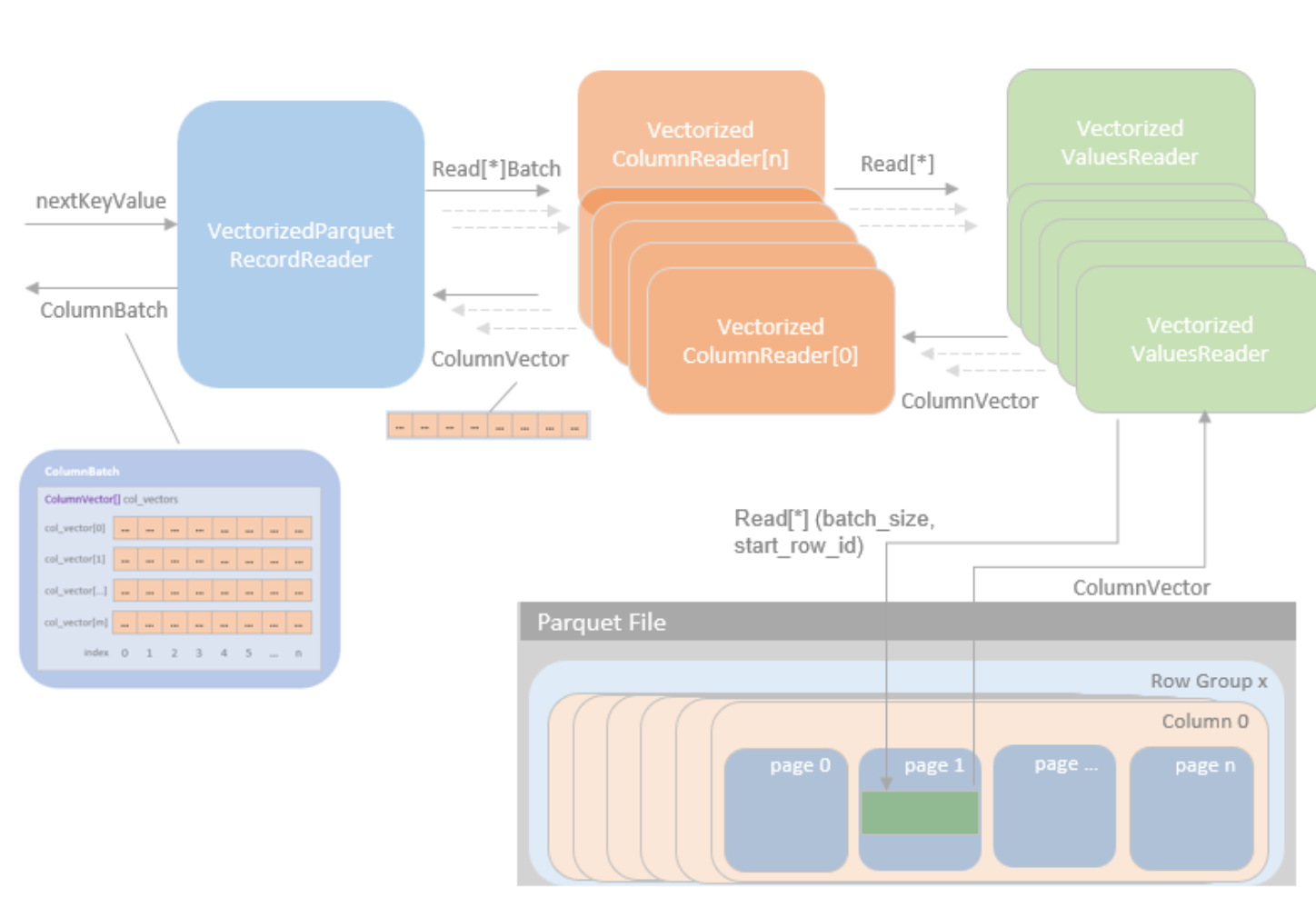
在初始化 VectorizedParquetRecordReader 并执行 $initBatch()$ 方法创建 ColumnBatch 实例和相关 ColumnVector 实例后,就可以通过 $nextKeyValue()$ 方法逐批读取 parquet 文件。
在 SparkSQL 优化中,会把查询的过滤条件,下推到靠近存储层,这样可以减少从存储层读取的数据量。其次在真正读取过滤数据时,Spark并不自己实现谓词下推,而是交给文件格式的 reader 来解决。
例如对于parquet文件,Spark使用PartquetRecordReader 或VectorizedParquetRecordReader 类来读取parquet文件,分别对应非向量化读和向量化的读取。
在构造reader类时需要提供filter的参数,即过滤的条件。过滤逻辑稍后由RowGroupFilter调用,根据文件中块的统计信息或存储列的元数据验证是否应该删除读取块(Spark在3.1 支持avro, json, csv的谓词下推)。

方法
$nextBatch()$
在 $nextBatch()$ 函数中,如果尚未读取所有行,则调用 $checkEndOfRowGroup()$ 函数。然后,$checkEndOfRowGroup()$ 函数读取一个 rowGroup,然后为 requestedSchema 中的每个请求列分配一个 VectorizedColumnReader 对象。VectorizedColumnReader 构造函数接受一个 ColumnDescriptor(可以在 schema 中找到) 和一个 PageReader (可以从 rowGroup 中找到,一个 Parquet API 调用)。
missingColumns 是确实列的一个 bitmap(可能是缺失的列或 Spark 不打算读取的列)。然后,在 $nextBatch()$ 中调用readBatch(num, columnarBatch.column(i)),会在之前 $checkEndOfRowGroup()$ 函数分配的所有 VectorizedColumnReader 对象上调用。
因此,ColumnarBatch 和 ColumnVector 只是 VectorizedColumnReader 使用的原始内存
所以在 $readBatch()$ 中,传递了行数和 ColumnVector(存储在 ColumnarBatch 中)。
什么是 ColumnVector🤔️? 可以将其视为一个类型数组,由 rowId 索引。
 微信
微信 支付宝
支付宝








