Flink-源码学习-API-Catalog 体系
一、概述数据处理最关键的方面之一是管理元数据。元数据可以是临时的,如临时表、或者通过 TableEnvironment 注册的 UDF。元数据也可以是持久化的,例如 HiveMetastore 中的元数据。Catalog 提供了一个统一的 API,用于管理元数据,如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息,并使其可以从 Table API 和 SQL 查询语句中来访问。
二、元数据 Catalog API 设计Catalog 在 Flink 中提供了一个统一的 API,用于管理元数据,Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
2.1. 元数据模型Flink 的元数据模型定义了任务的元数据结构,如数据库、表、视图、函数等,Flink 定义了 4 类接口分别对应于 4 种元数据类型,元数据类型之间的层次关系如图,最顶层的 Catalog 是元数据的容器。
2.1.1. 数据库数据库等同于数据库中的库实例,接口定义为 CatalogDatabase,定义数据库实例的元数据,一个数据库实例中包含表、 ...

Flink-源码学习-FlinkSQL&Table-Module 体系
一、概述https://ost.51cto.com/posts/17088
Module 允许 Flink 扩展函数能力。它是可插拔的,Flink 官方本身已经提供了一些 Module,用户也可以编写自己的 Module。
例如,用户可以定义自己的函数,并将其作为加载进入 Flink,以在 Flink SQL 和 Table API 中使用。
再举一个例子,用户可以加载官方已经提供的的 Hive Module,将 Hive 已有的内置函数作为 Flink 的内置函数。
目前 Flink 包含了以下三种 Module:
⭐ CoreModule:CoreModule 是 Flink 内置的 Module,其包含了目前 Flink 内置的所有 UDF,Flink 默认开启的 Module 就是 CoreModule,我们可以直接使用其中的 UDF
⭐ HiveModule:HiveModule 可以将 Hive 内置函数作为 Flink 的系统函数提供给 SQL\Table API 用户进行使用,比如 get_json_object 这类 Hive 内置函数(Flink 默认的 Co ...
Flink-源码学习-FlinkSQL&Table-Planner-Parser 模块-CalciteParser
一、概述对于标准的 SQL 语句, ExtendedParser 不会去解析它。标准 SQL 的解析过程由 CalciteParser 负责。
二、实现
Flink-源码学习-FlinkSQL&Table-Planner-Parser 模块-ExtendedParser
一、概述ExtendedParser 用于在不增加 CalciteParser 复杂性的前提下(不用修改Calcite,增加新的关键字),让 Flink SQL 支持更多专用的语法。
二、实现2.1. 策略https://www.jianshu.com/p/e4956652cfcb
ExtendedParser 包含如下解析策略:
1234567private static final List<ExtendedParseStrategy> PARSE_STRATEGIES = Arrays.asList( ClearOperationParseStrategy.INSTANCE, HelpOperationParseStrategy.INSTANCE, QuitOperationParseStrategy.INSTANCE, ResetOperationParseStrategy.INSTANCE, Se ...
Flink-源码学习-FlinkSQL&Table-Planner-Parser 模块
一、概述二、实现2.1. 架构设计2.2. 解析2.2.1. $ParserImpl#parse$
获取 Calcite 的解析器
1CalciteParser parser = calciteParserSupplier.get();
使用 FlinkPlannerImpl 作为 validator
1FlinkPlannerImpl planner = validatorSupplier.get();
EXTENDED_PARSER
对于一些特殊的写法,例如 SET key=value。CalciteParser 是不支持这种写法的, 为了避免在 Calcite 引入过多的关键字,这里定义了一组 extended parser,专门用于在CalciteParser之前,解析这些特殊的语句
1234Optional<Operation> command = EXTENDED_PARSER.parse(statement);if (command.isPresent()) { return Collections.singletonList(command. ...
Flink-源码学习-FlinkSQL&Table-Planner-Validator 模块
一、概述二、实现2.1. 架构设计
2.2. 验证2.2.1. $SqlValidatorImpl#validate$
Flink-源码学习-FlinkSQL&Table-Table 体系-Connector-TableSource
一、概述Flink SQL 可以将多种数据源或数据落地端映射为 table
二、实现2.1. 架构设计Flink 使用 SPI 机制加载Factory(DynamicTableSourceFactory 和 DynamicTableSinkFactory同属 Factory)。在 flink-table-api-java-bridge 项目的 resources/META-INF/services 目录可以找到org.apache.flink.table.factories.Factory 文件,内容为:
123org.apache.flink.table.factories.DataGenTableSourceFactoryorg.apache.flink.table.factories.BlackHoleTableSinkFactoryorg.apache.flink.table.factories.PrintTableSinkFactory
以 DataGenTableSourceFactory 为例:
2.1.1. DynamicTableSourceFactory2. ...
Flink-源码学习-FlinkSQL&Table-一条简单 SQL 的执行~
一、概述123456789101112131415161718192021222324252627282930private val AVG_TEMPLATE_SINK_TABLE_SQL: String = """ |CREATE TABLE avg_template_sink_table ( | `avg_temp_val` DOUBLE, | `address` STRING, | `ts` TIMESTAMP(3) |) WITH ( | 'connector' = 'print' |) |""".stripMargin def main(args: Array[String]): Unit = { val settings: EnvironmentSettings = EnvironmentSettings.newInstance().inStreamingMode ...
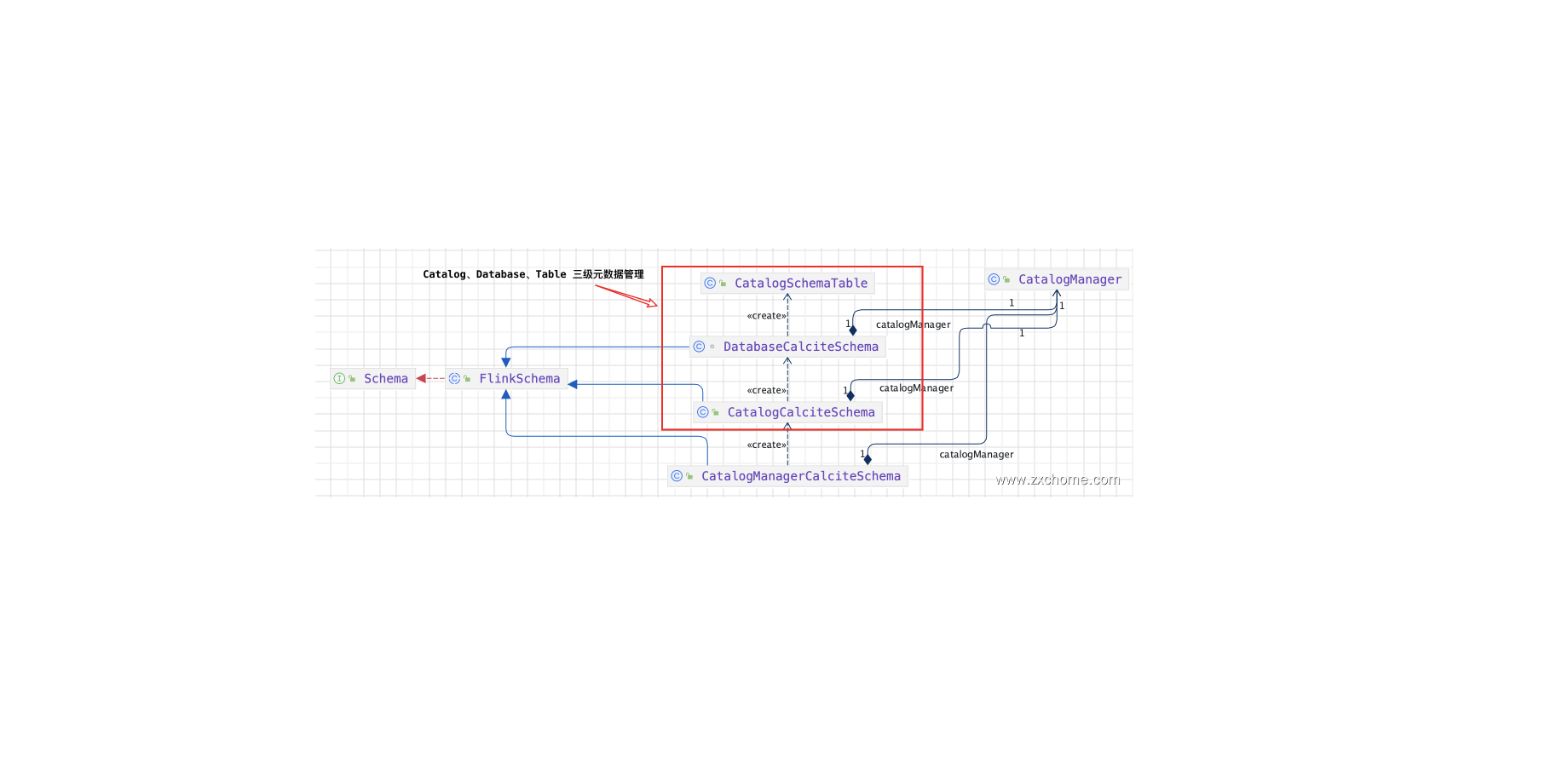
Flink-源码学习-FlinkSQL&Table-元数据体系
一、概述为了使用 SQL,首先需要解决的是元数据管理的问题。包括 Table/UDF/View 元数据的注册、查询以及验证。
二、架构设计2.1. 元数据注册FinkSQL 原生支持了 DDL 语法,比如 CREATE 语句,通过 Catalog API 将表/视图/函数 注册到当前或指定的 Catalog 中,默认使用 InMemoryCatalog 将信息临时保存在内存中,有一个唯一的 ID,由三部分组成: 目录 (catalog)、数据库 (database) 名、表名。
在默认情况下,目录名为 defaultcatalog、数据库名为 default database。故直接创建一个 test 表,它的 ID 是: defaultcatalog.default database.MyTable
同时也提供了 HiveCatalog 与 HiveMetastore 进行集成。FlinkSQL 目前支持以下 CREATE 语句:
CREATE TABLE
CREATE CATALOG
CREATE DATABASE
CREATE VIEW
CREATE FUNCTION
...
Flink-源码学习-FlinkSQL&Table-规则体系 Rules-logical
一、概述SQL 的执行流程一般分为四个主要的阶段,Flink 主要依赖于 Calicte 来完成这一流程:
Parse:语法解析,把 SQL 语句转换成为一个抽象语法树(AST),在 Calcite 中用 SqlNode 来表示;
Validate:语法校验,根据元数据信息进行验证,例如查询的表、使用的函数是否存在等,校验之后仍然是 SqlNode 构成的语法树;
Optimize:查询计划优化,这里其实包含了两部分,1)首先将 SqlNode 语法树转换成关系表达式 RelNode 构成的逻辑树,2)然后使用优化器基于规则进行等价变换,例如我们比较熟悉的谓词下推、列裁剪等,经过优化器优化后得到最优的查询计划;
Execute:将逻辑查询计划翻译成物理执行计划,生成对应的可执行代码,提交运行。
Flink SQL 的处理也大体遵循上述处理流程。Calcite 自身的概念较为庞杂,尤其是其内部使用的 HepPlanner 和 VolcanoPlanner 优化器更是非常复杂,但好在 Calcite 的可扩展性很强,优化器的优化规则也可以很容易地进行扩展,因此如果只是了解 Flin ...
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.