
Spark-源码学习-架构设计-DataSource 体系-FileFormat-Parquet
一、概述
https://mp.weixin.qq.com/s/TVkuyBwCQmIfSR3VYFrGaQ
https://www.learntospark.com/2020/02/how-to-read-and-write-parquet-in-apache-spark.html
https://www.mianshigee.com/note/detail/221583thf/
https://www.sohu.com/a/507896675_120099884
https://mp.weixin.qq.com/s/HH8s6o7C50uaq2hs4axd0A
1.1. Parquet
二、ParquetFileFormat

2.1. supportBatch()
1 | override def supportBatch(sparkSession: SparkSession, schema: StructType): Boolean = { |
2.2. Schema Merging
似于 Protocol Buffer, Avro 和 Thrift。Parquet 也支持 Schema Evolution。用户能能从一个简单的 Schema 开始,逐渐添加更多的列到 Schema 中。最后,用户可以得到多种不同的复杂的 Parquet 文件,但是它们有着互相兼容的架构。Parquet 可以检测到这种情况,并合并这些 Schema。
https://mp.weixin.qq.com/s/g1xJGBOziIQQxPq1ocl9xQ
2.3. 初始化 reader
https://www.jianshu.com/p/709d88ca4497
三、数据结构
3.1. ColumnarBatch
3.2. ParquetColumnVector
四、文件读取
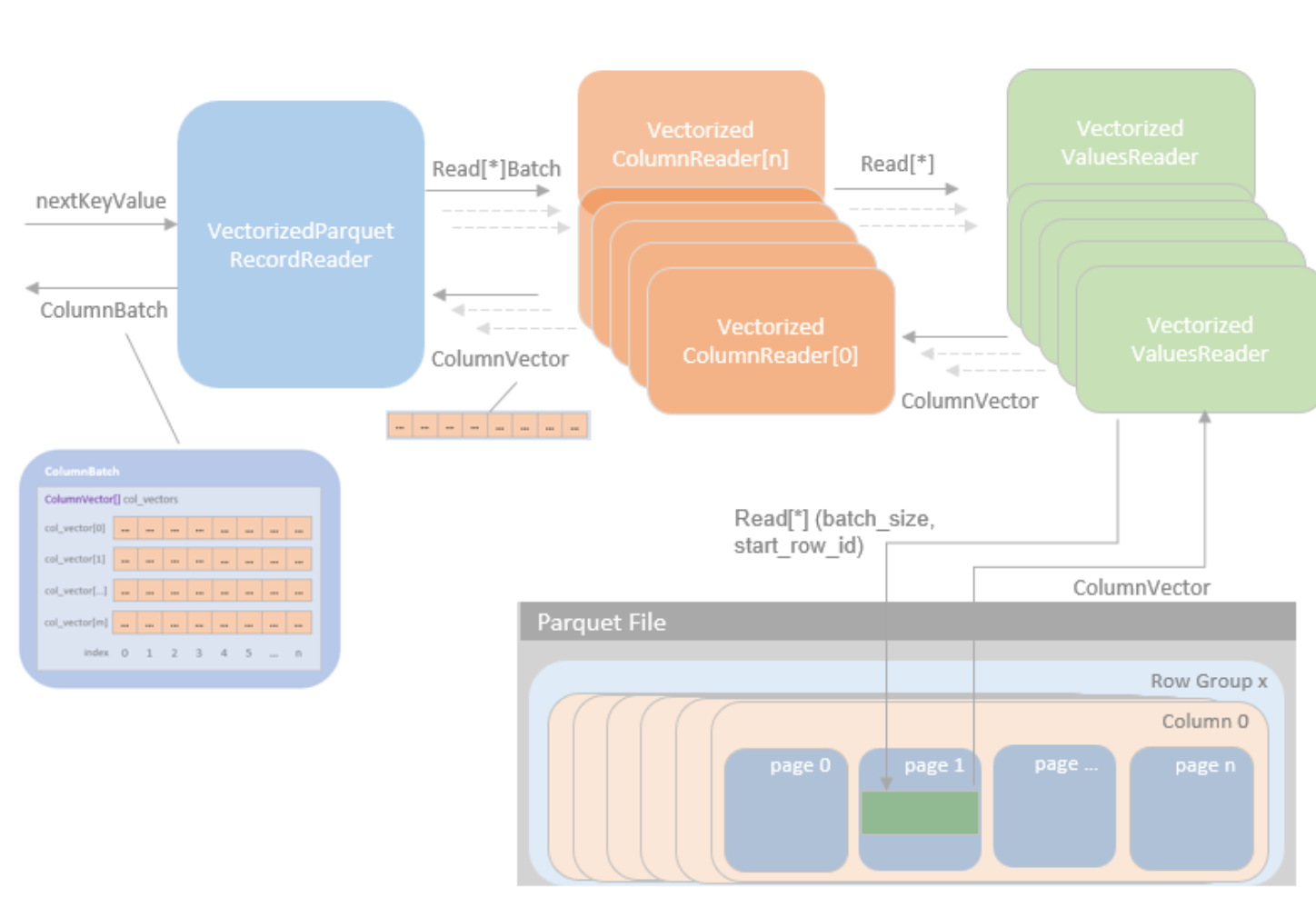
Spark SQL 中读取 Parquet 文件的过程入口点是 DataSourceScanExec,Spark SQL 通过三个主要 Reader 组件实现了矢量化 Parquet 读取: VectorizedParquetRecordReader、VectorizedColumnReader 和 VectorizedValuersReader。
4.1. DataSourceScanExec
真正读取数据是 DatasourceScanExec
DataSourceV2ScanExec 有 V2 版本,parauet, orc 使用的是 V1版
org.apache.spark.sql.execution.DataSourceScanExec.scala
$inputRDD()$ 方法利用 relation.fileFormat.buildReaderWithPartitionValues 作为 readFile 的方法,创建 BucketedReadRDD 或者 NonBucketedReadRDD。DataSourceStrategy 和 InMemoryScans 策路最后都会生成 RoWDataSourceScanExec, 最终会调用
CatalystScan\PrunedScanl TableScan的 buildScan 方法生成 RDD[Row], 再调用 toCatalystRDD 将 RDD[RoW] 转换为 RDDInterna[Row]。
$FileSourceScanExec.inputRDD$
1 | lazy val inputRDD: RDD[InternalRow] = { |
4.1.1. 获取 PartitionedFile
4.1.2. readRDD
在 $ParquetFileFormat.buildReaderWithPartitionValues()$ 实现中, 会使用 split 来初始化 reader, 并且根据配置可以把 reader 分为否是 vectorized 的
4.2. Parquet Reader
例如对于 Parquet 文件,Spark 使用 PartquetRecordReader 或 VectorizedParquetRecordReader 类来读取 Parquet 文件,分别对应非向量化读和向量化的读取。
4.2.1. Vectorized Reader
VectorizedParquetRecordReader
在初始化 VectorizedParquetRecordReader 并执行 $initBatch()$ 方法创建 ColumnBatch 实例和相关 ColumnVector 实例后,就可以通过 $nextKeyValue()$ 方法逐批读取 parquet 文件。
VectorizedColumnReader
对于每个行组,都会创建一个新的 VectorizedColumnReader 数组,每个请求的列都有一个 VectorizedColumnReader 实例。VectorizedParquetRecordReader 中的 $nextBatch()$ 方法会在 VectorizedColumnReader 数组中循环,将批次数据逐列读入相应的 ColumnVectors 中。
VectorizedValuesReader
根据数据编码方法,VectorizedColumnReader 会创建相应的 VectorizedValuesReader 实现实例来读取和解码数据。
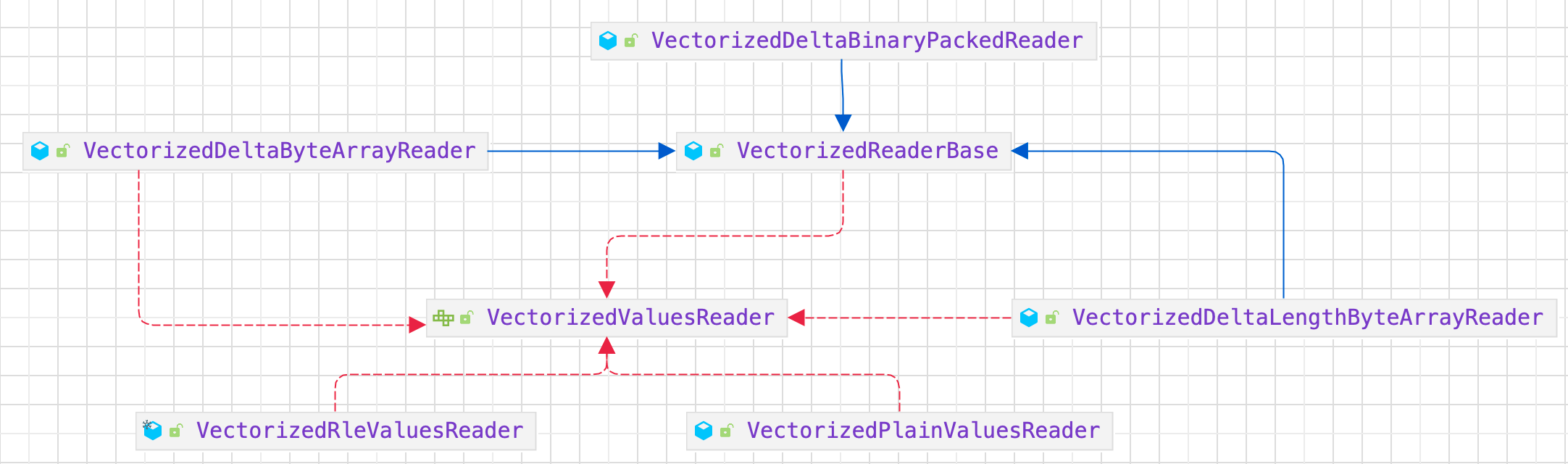
4.2.2. PartquetRecordReader
五、文件写入

5.1. Parquet Writer
https://blog.csdn.net/orisonchan/article/details/86603701
https://blog.csdn.net/weixin_33885676/article/details/89622568
https://blog.csdn.net/u013494310/article/details/44832857/
https://zhuanlan.zhihu.com/p/147887693?utm_source=wechat_session
5.1.1. Spark
ParquetWriteSupport
ParquetRecordWriter 其 overwrite 的写方法,就是调用 InternalParquetRecordWriter 的写方法,然后 InternalParquetRecordWriter 的写方法又调用 writeSupport 的写方法,在 Spark 的 ParquetWriteSupport 对象中,会发现最后调用的是 recordConsumer 的 addX 方法(如addBoolean(),addInteger()),而 recordConsumer 实际对象是 MessageColumnIORecordConsumer
ParquetOutputWriter
FileFormatDataWriter
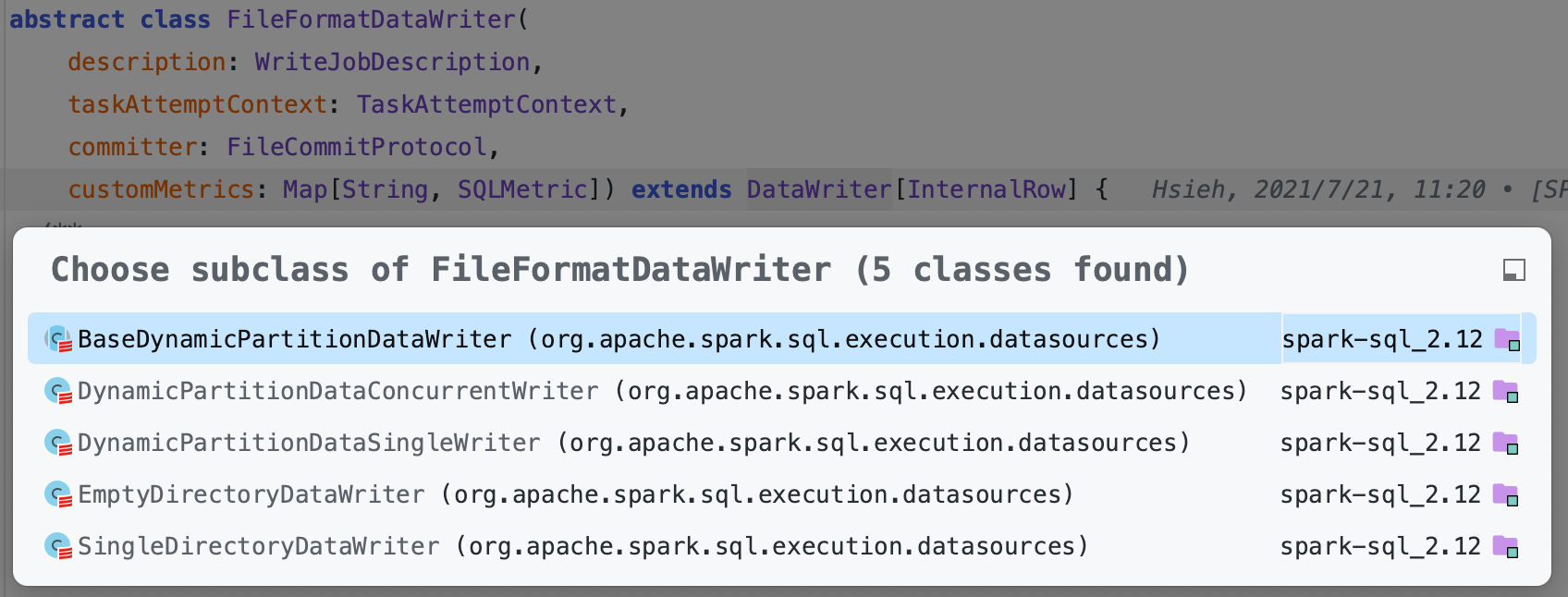
5.1.2. Hadoop
- ParquetRecordWriter
六、总结
 微信
微信 支付宝
支付宝








