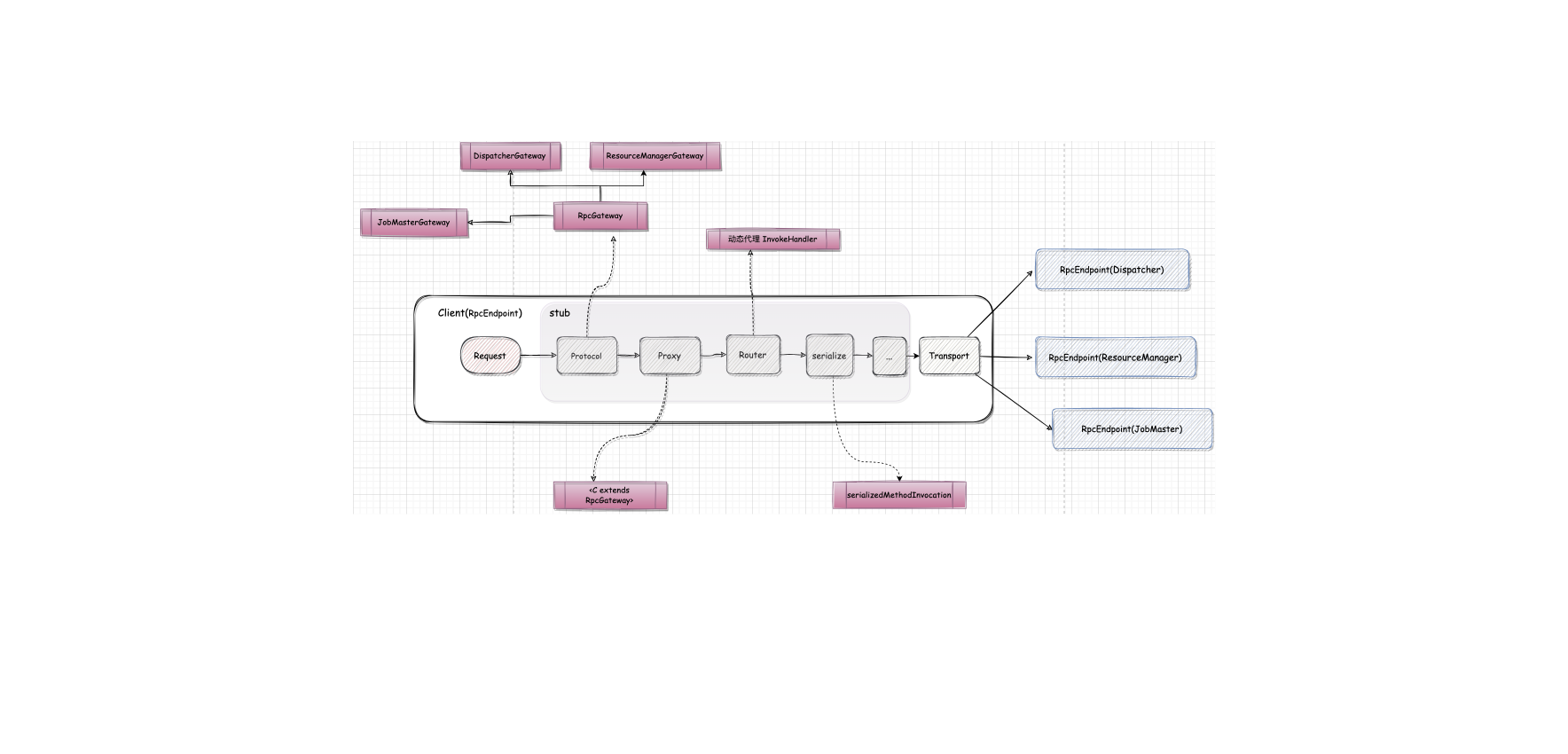
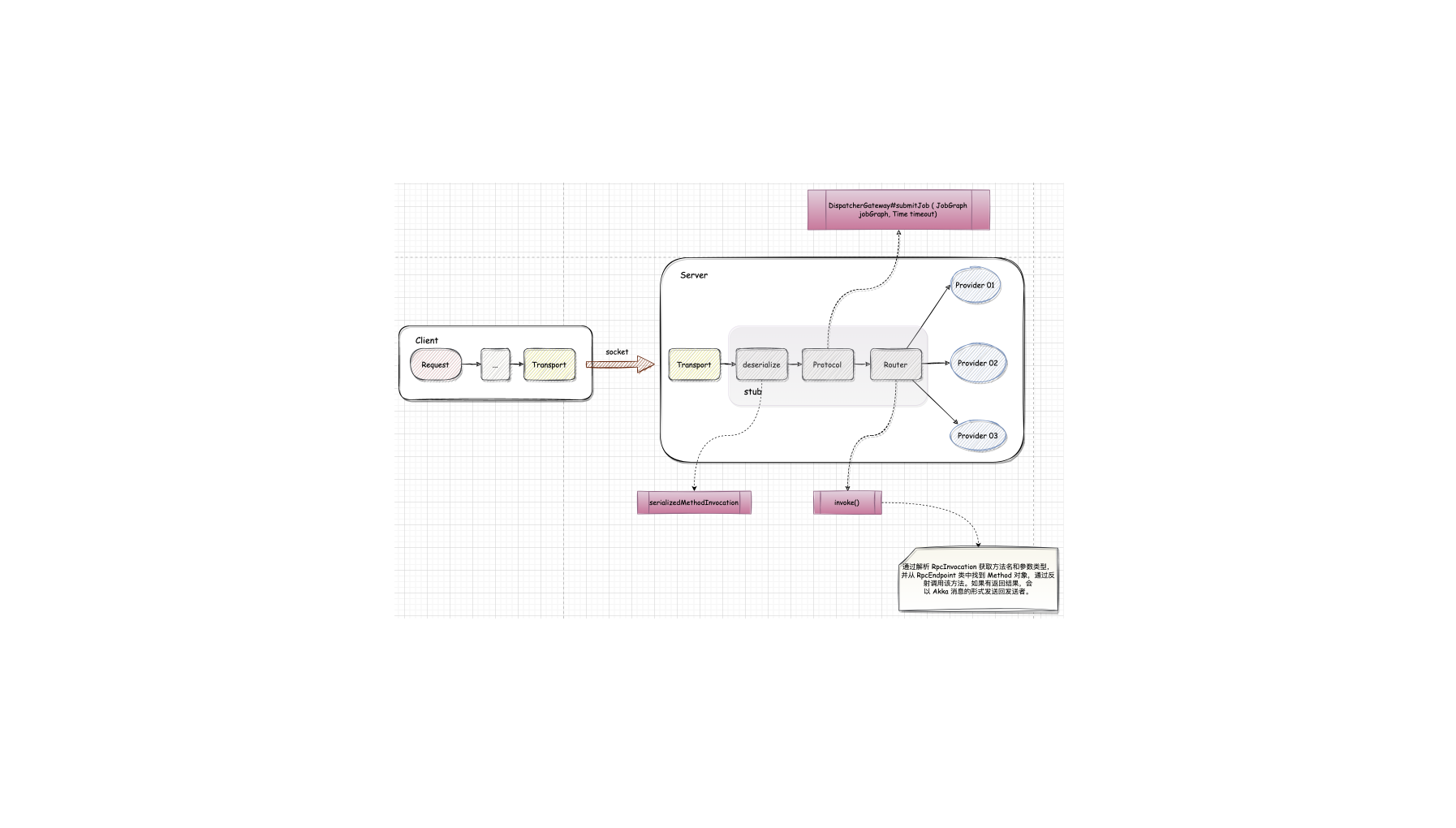
Flink-源码学习-架构设计-部署模式-Session
一、概述
Session 模式会初始化一个 Flink 集群,此后提交的任务共享这个 Flink 集群资源,这个 Flink 集群会常驻,除非手动停止。在 Session 模式下,WebMonitorEndpoint、 Dispatcher、 ResourceManager 在 JobManager 启动时会一起启动,JobMaster 在有任务提交时才会启动。

二、架构设计
在 Flink 1.10 版本中提供了三种会话模式:Standalone、Yarn 会话模式、K8s 会话模式。对应源码,在 Flink 集群运行时启动过程中,会通过 ClusterEntrypoint 集群入口类启动管理节点中的核心组件与服务。集群运行时会根据资源管理器的不同,选择不同的 ClusterEntrypoint 实现类启动集群组件。
在 Session 集群部署模式下 SessionClusterEntrypoint 的实现类主要有 StandaloneSessionClusterEntrypoint、 KubernetesSessionClusterEntrypoint、YarnSessionClusterEntrypoint 以及 MesosSessionClusterEntrypoint 等类型。
2.1. Standalone Session
Standalone 是 Flink 的独立部署模式,不需要使用外部的资源管理器(ResourceManager),对应的集群入口类为
StandaloneSessionClusterEntrypoint,通过在启动脚本中运行 StandaloneSessionClusterEntrypoint 的 main 方法,实现 StandaloneSessionClusterEntrypoint 集群的创建和启动。
Standalone 模式比较特别,Flink 安装在物理机上,不能像在第三方资源集群(Yarn、 Mesos、 Kubernetes)上一样,可以随时启动一个新集群,所有的作业共享 Standalone 集群,本质上就是一种 Session 模式,所以不支持 Per-Job 模式。
2.1.1. 集群启动
使用 bin/start-cluster.sh 提交会话模式的作业如果提交到已经存在的集群,则获取集群信息、应用 ID,并准备提交作业。如果集群不存在,则启动新的 StandalonSession 集群
- 如果没有集群,则创建一个新的 Session 模式的集群。首先上传应用配置(flink-conf.yaml、logback.xml、log4.properties)和相关文件(Flink jar、配置类文件、用户 jar 文件、JobGraph 对象等)
- 通过 Client 向 ResourceManager 提交 Flink 创建集群的申请,ResourceManager 分配资源
- 启动 JobManager
初始化并启动 Flink JobManager 进程,在 JobManager 进程中运行 StandaloneSessionClusterEntrypoint 作为集群启动的入口,初始 化Dispatcher、ResourceManager,启动相关的 RPC 服务,等待 Client 通过 Rest 接口提交作业。 - 启动 TaskManager
2.1.2. 作业提交
Yarn 集群准备好后,开始作业提交。
- Flink Client 通过 Rest 向 Dispatcher 提交 JobGraph。
- Dispatcher 是 Rest 接口,不负责实际的调度、执行方面的工作,当收到 JobGraph 后,为作业创建一个 JobMaster,将工作交给JobMaster (负责作业调度、管理作业和 Task 的生命周期),构建 ExecutionGraph(JobGraph的并行化版本,调度层最核心的数据结构)。这两个步骤结束后,作业进入调度执行阶段。
2.1.3. 作业调度
JobMaster 向 ResourceManager 申请资源,开始调度 ExecutionGraph 执行。
ResourceManager 收到 JobMaster 的资源请求,ResourceManager 选择空闲 slot 后,通知 TaskManager,然后 TaskExecutor 进行相应的记录后,会向 JobMaster 进行注册。JobMaster 收到 TaskExecutor 注册的 slot 后,可以实际提交 Task
TaskManager 向 JobMaster 提供 Slot, JobMaster 调度 Task 到 TaskManager 的此 Slot 上执行。
Standalone 部署时,因为 TaskManager 是单独启动的(所以 Standalone 只有Session 模式),所以 ResourceManager 只能分
发可用 TaskManager 的任务槽,不能单独启动新 TaskManager。
2.2. Yarn Session
基于 Hadoop Yarn 资源管理器创建 Flink Session 集群,对应的集群入口类为 YarnSessionClusterEntrypoint,最终通过在启动脚本中运行
YarnSessionClusterEntrypoint 的 main 方法,实现 YarnSessionCluster 集群的创建和启动。
2.2.1. 启动集群
使用 bin/yarn-session.sh 提交 Session 模式的作业,如果提交到已经存在的集群,则获取 Yarn 集群信息、应用ID,并准备提交作业。如果集群不存在,则启动新的 Yarn Session 集群
- 如果没有集群,则创建一个新的 Session 模式的集群。首先将应用配置(flink-conf.yaml、 logback.xml、 log4j.properties) 和
相关文件(Flink jar、配置类文件、用户 jar 文件、JobGraph 对象等)上传至分布式存储(如HDFS)的应用暂存目录。 - 通过 Yarn Client 向 Yarn ResourceManager 提交 Flink 创建集群的申请,Yarn 分配资源,在申请的 Yarn Container 中初始化并启动 Flink JobManager 进程,在 JobManager 进程中运行 YarnSessionClusterEntrypoint 作为集群启动的入口,初始化Dispatcher、ResourceManager,启动相关的 RPC 服务,等待 Client 通过 Rest 接口提交作业。
2.2.2. 作业提交
Yarn 集群准备好后,开始作业提交。
- Flink Client 通过 Rest 向 Dispatcher 提交 JobGraph。
- Dispatcher 是 Rest 接口,不负责实际的调度、执行方面的工作,当收到 JobGraph 后,为作业创建一个 JobMaster,将工作交给JobMaster(负责作业调度、管理作业和 Task 的生命周期),构建 ExecutionGraph(JobGraph的并行化版本,调度层最核心的数据结构)。这两个步骤结束后,作业进入调度执行阶段。
2.2.3. 作业调度
- JobMaster 向 YarnResourceManager 申请资源,开始调度 ExecutionGraph 执行,初次提交作业集群中尚没有TaskManager,此时资源不足,开始申请资源。
- YarnResourceManager 收到 JobMaster 的资源请求,如果当前有空闲 Slot 则将 Slot 分配给JobMaster,否则 YarnResourceManager 将向 Yarn Master 请求创建 TaskManager。
- YarnResourceManager 将资源请求加入等待请求队列,并通过心跳向 YARN ResourceManager 申请新的 Container 资源来启动 TaskManager 进程;Yarn 分配新的 Container 给 TaskManager。
- YarnResourceManager 启动,然后从 HDFS 加载 jar 文件等所需的相关资源,在容器中启动 TaskManager。
- TaskManager 启动之后,向 ResourceManager 注册,并把自己的 Slot 资源情况汇报给 ResourceManager
- ResourceManager 从等待队列中取出 Slot 请求,向 TaskManager 确认资源可用情况,并告知 TaskManager 将 Slot 分配给了哪个 JobMaster。
- TaskManager 向 JobMaster 提供 Slot,JobMaster 调度 Task 到 TaskManager 的此 Slot 上执行。
2.3. Kubernetes Session
作为目前最流行的容器编排工具,大部分应用框架都逐步迁移至 Kubernetes 上运行,Flink 也不例外。得益于 Kubernetes 精确的资源管理以及灵活自主的服务发现和动态伸缩等特性,让 Flink 能够在资源隔离和管理层面得到非常高的提升。
和 Yarn 资源管理器实现的 Session 集群相同,KubernetesSessionClusterEntrypoint 作为基于 Kubernetes 资源管理器实现的 Session 集群入口类,定义了 Kubernetes Flink Session 集群的启动和初始化逻辑。
2.3.1. 启动集群
使用 bin/kubernetes-session.sh 提交会话模式的作业如果提交到已经存在的集群,则获取 Kubernetes 集群信息、应用 ID,并准备提交作业。如果集群不存在,则启动新的 Kubernetes Session 集群
Flink 客户端连接到 Kubernetes API Server,提交 Flink 集群的资源描述文件,其中包括 ConfigMap、JobManager service、 JobManager deployment 等资源描述。
Kubernetes 管理节点会根据这些资源描述文件创建对应的 Kubernetes 实体。
以 JobManager deployment 为例,Kubernetes 集群中的某个节点收到请求后,Kubelet 进程会从中央仓库下载 Flink 安装镜像,然后准备和挂载数据卷,并执行 JobManager 启动命令。当 JobManager 的 Pod 启动后,Dispacher 和 KubernetesResourceManager 等组件随之全部启动。
- Flink Session 集群管理节点启动完毕后,会接收客户端提交的任务请求,用户可以通过命令行将任务提交至 Session 集群。
2.3.2. 作业提交
Kubernetes 集群准备好后,开始作业提交。
- Flink Client 通过 Rest 向 Dispatcher 提交 JobGraph。
- Dispatcher 是 Rest 接口,不负责实际的调度、执行方面的工作,当收到 JobGraph 后,为作业创建一个 JobMaster,将工作交给JobMaster(负责作业调度、管理作业和 Task 的生命周期),构建 ExecutionGraph(JobGraph的并行化版本,调度层最核心的数据结构)。这两个步骤结束后,JobMaster 服务启动后会向 KubernetesResourceManager 请求作业需要的 Slot 计算资源,作业进入调度执行阶段。
2.3.3. 作业调度
- KubernetesResourceManager 会从 Kubernetes 中申请和启动 TaskManager 所需的容器资源。KubernetesResourceManager 为 TaskManager 生成一份新的配置文件,包括 Flink Master 服务名等信息。
- Kubernetes 集群会为 TaskManager 分配一个新的 Pod,并启动 TaskManager 实例所在的 Pod。
- TaskManager 启动后会主动注册到 ResourceManager 的 SlotManager 中。
- SlotManager 向 TaskManager 请求 Slot 计算资源,并分配给 JobMaster 服务。
- TaskManager 提供 Slot 计算资源给 JobMaster,JobMaster 将任务分配到对应的 Slot 计算资源上运行。
2.3.4. Native 模式
为什么叫 Native 方式 🤔️~
Flink 的 Client 内置了一个 K8s Client, 可以借助 K8s Client 去创建 JobManager,当 Job 提交之后,如果对资源有需求,
JobManager 会向 Flink 自己的 ResourceManager 去申请资源。这个时候 Flink 的 ResourceManager 会直接跟 K8s 的 API
Server 通信,将这些请求资源直接下发给 K8s Cluster,告诉它需要多少个 TaskManger,每个 TaskManager 多大。当任务运行
完之后,它也会告诉 K8s Cluster 释放没有使用的资源。
Native 是相对于 Flink 而言的,借助 Flink 的命令就可以达到自治的一个状态,不需要引入外部工具就可以通过 Flink 完成任务在
K8s 上的运行。
2.3.5. refer
2.4. Mesos
三、总结
3.1. 集群生命周期
Session 模式会有一个预先启动的 Flink 集群,接受多个 Job 的提交,集群需要手动停止。集群的生命周期独立于其中运行的 Job。
3.2. 资源隔离
一个集群可以同时运行多个作业不用反复申请资源。但是作业之间共用资源,就会有资源的竞争。资源隔离的粒度是 TaskManager slot。
如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都会失败,那么重启所有作业又会带来如并发访问文件系统导致其对其他服务不可用的问题: JobManager 挂掉,会影响集群中正在运行的所有作业。
3.3. main 执行位置
客户端
3.4. 适用场景
预先启动的 Flink 集群使得作业不需要反复申请资源,这种模式适合启动延迟敏感的短期作业(如交互式查询)。但是单集群运行多个 Job,意味着JobManager 有更大的负载。
 微信
微信 支付宝
支付宝