数据湖-Hudi-源码学习-Kernel-TableFormat-Index 设计
一、概述
Hudi 借鉴了数据库设计的原理,提供了索引实现,通过索引机制加速数据的更新 ($Upsert、\ Delete、…$ ),将给定的 hoodie key (record key (记录键) + partition path ) 与文件 id(文件组)建立唯一映射。
这种映射关系,数据第一次写入文件后保持不变
- https://zhuanlan.zhihu.com/p/591003559
- https://blog.csdn.net/weixin_45417821/article/details/128612961
- https://bbs.huaweicloud.com/blogs/272531
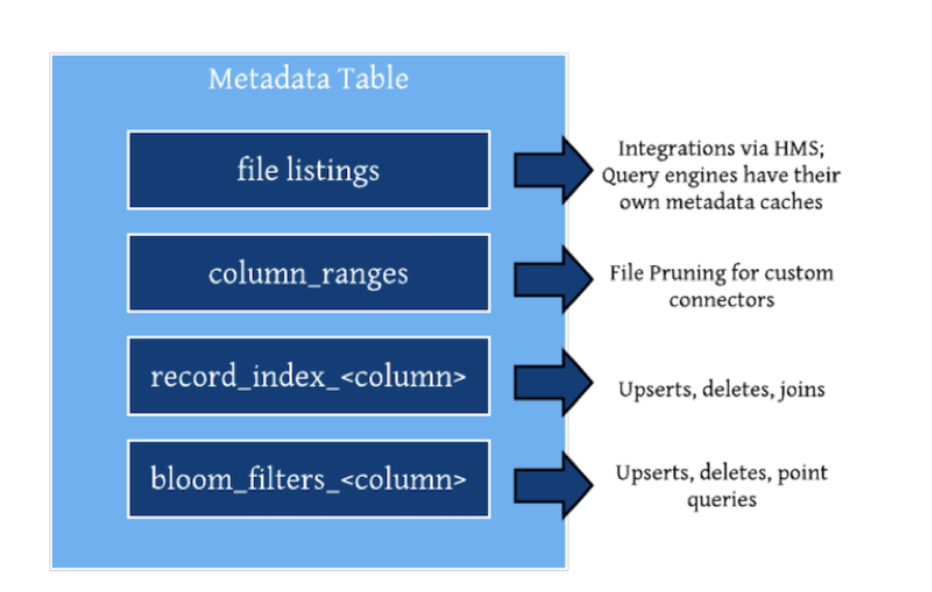
二、设计
Hudi 为了加速数据的更新($Upsert、\ Delete、…$ ),支持多种索引,如分区级别的索引以及全表索引,分区级别的索引可以保证数据在分区内的唯一性,全表索引保证数据在表级的唯一性(开销较大)。

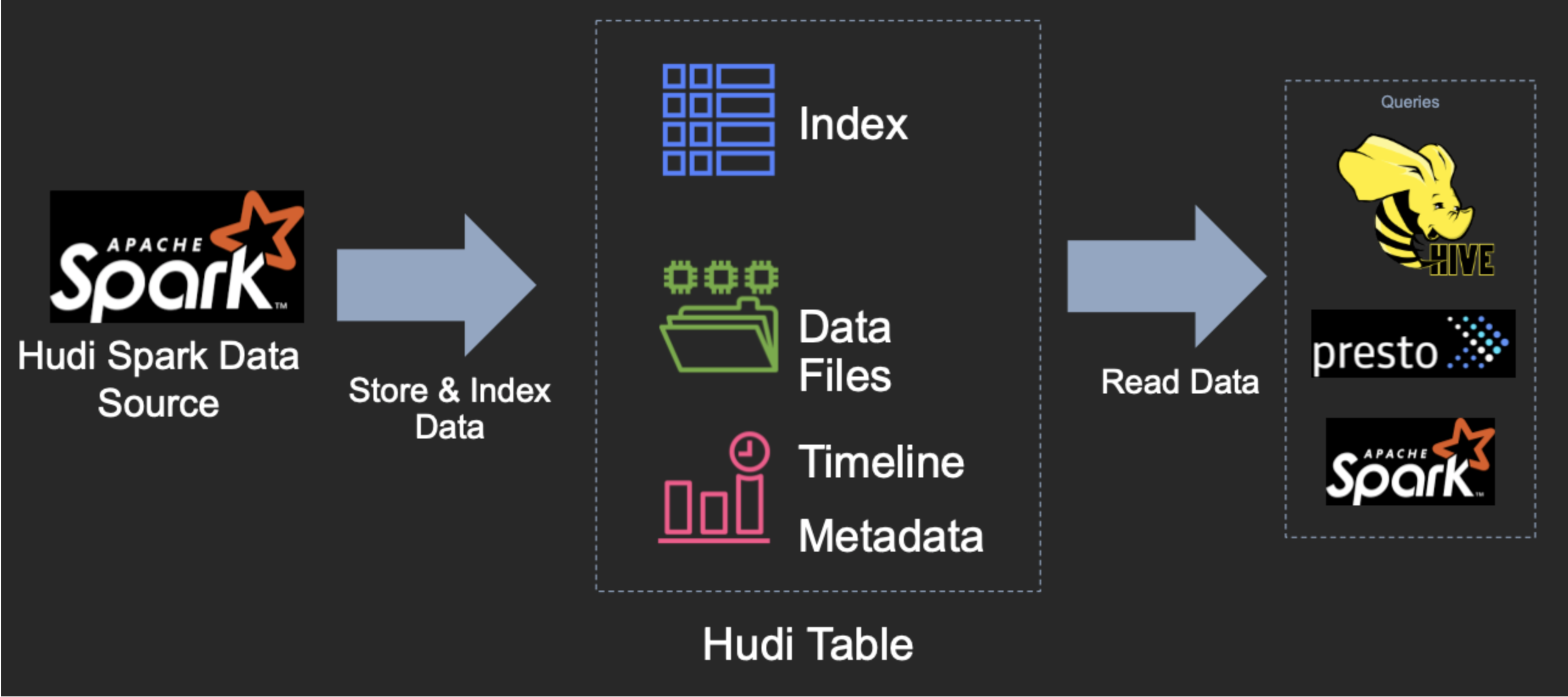
在有了索引之后,更新的数据可以快速被定位到对应的 FileGroup。上图为例,白色是基本文件,黄色是更新数据,有了索引机制,可以做到: 避免读取不需要的文件、避免更新不必要的文件、无需将更新数据与历史数据做分布式关联,只需要在 FileGroup 内做合并。
2.1. 全局索引 Global Index
全局索引在全表的所有分区范国下强制要求键的唯一性,也就是确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,但是随着表增大,$Upsert/Delete$ 操作损失的性能越高,因此更适用于小表。
2.2. 非全局索引 Non-global Index
默认的索引实现,只能保证数据在分区的唯一性。Non-global Index 依靠写入器为同一个记录的 $Upsert/Delete$ 提供一致的分区路径,同时大幅提高了效率,更适用于大表。从 index 的维护成本和写入性能的角度考虑,维护一个 global index 的难度更大,对写入性能的影响也更大,所以需要 non-global index。
三、实现
Hudi 支持了多种类型的索引实现,典型的如 BLOOM、BUCKET 索引,以及自定义索引等方式。

HBase 索引本质上是一个全局索引,Bloom 和 Simple index 都有全局选项:
- hoodie.index.type=GLOBAL_BLOOM
- hoodie.index.type=GLOBAL_SIMPLE
3.1. HoodieIndex 接口

Hudi 默认采用 HoodieBloomIndex 索引,其依赖布隆过滤器来判断记录存在与否,当记录存在时,会读取实际文件进行二次判断,以便修正布隆过滤器带来的误差。同时还在每个文件元数据中添加了该文件保存的最大和最小的 recordkey,借助该值可过滤出无需对比的文件。
https://maimai.cn/article/detail?fid=1713886874&efid=O68ocTG_4EW10eAoS4UL6g
SparkHoodieHBaseIndex
引用本站文章数据湖-Hudi-源码学习-Kernel-TableFormat-Index 实现-Spark-SparkHoodieHBaseIndexJoker
FlinkInMemoryStateIndex
引用本站文章数据湖-Hudi-源码学习-Kernel-TableFormat-Index 实现-Flink-FlinkInMemoryStateIndexJoker
 微信
微信 支付宝
支付宝