Spark-源码学习-SparkSQL 系列
一、执行环境Spark2.0 中引入了 SparkSession 的概念,为用户提供了一个统一的切入点来使用 Spark 的各项功能。
在 Spark 的早期版本,SparkContext 是进入 Spark 的切入点。RDD 的创建和操作得使用 SparkContext 提供的API; 对于 RDD 之外的其他东西,需要使用其他的 Context。
比如流处理使用 StreamingContext; 对于 SQL 得使用 SQLContext; 而对于 Hive 得使用 HiveContext。然而当 Dataset 和 DataFrame 提供的 API 逐渐成为新的标准 API,Spark 需要一个切入点来构建它们,在 Spark 2.0 中引入一个新的切入点: SparkSession。
引用本站文章
Spark-源码学习-SparkSession 设计
Joker
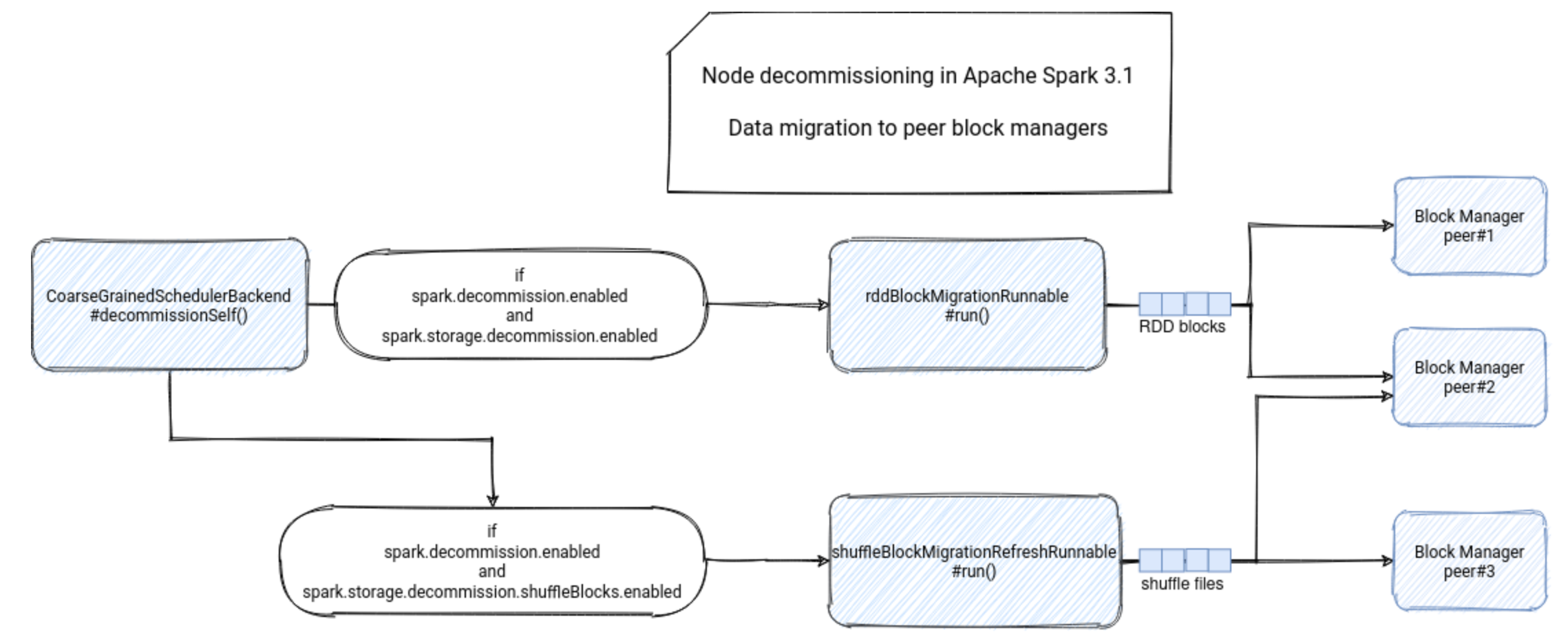
...
Spark-源码学习-SparkSQL-HelloAQE
一、概述在 Spark 3.0 引入了自适应查询执行(Adaptive Query Execution,AQE) 框架,AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
首先,AQE 赖以优化的统计信息与 CBO 不同,这些统计信息并不是关于某张表或是哪个列,而是 Shuffle Map 阶段输出的中间文件,每个 Map Task 都会输出以 data 为后缀的数据文件,还有以 index 为结尾的索引文件,这些文件统称为中间文件。每个 data 文件的大小、空文件数量与占比、每个 Reduce Task 对应的分区大小,所有这些基于中间文件的统计值构成了 AQE 进行优化的信息来源。
其次,AQE 从运行时获取统计信息,在条件允许的情况下,优化决策会分别作用到逻辑计划和物理计划。
Spark AQE,总体思想是动态优化和修改 stage 的物理执行计划。利用执行结束的上游 stage 的统计信息 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。

通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.