Spark-理论笔记-架构设计
一、概述Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 是 UC Berkeley AMP lab(加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行框架。
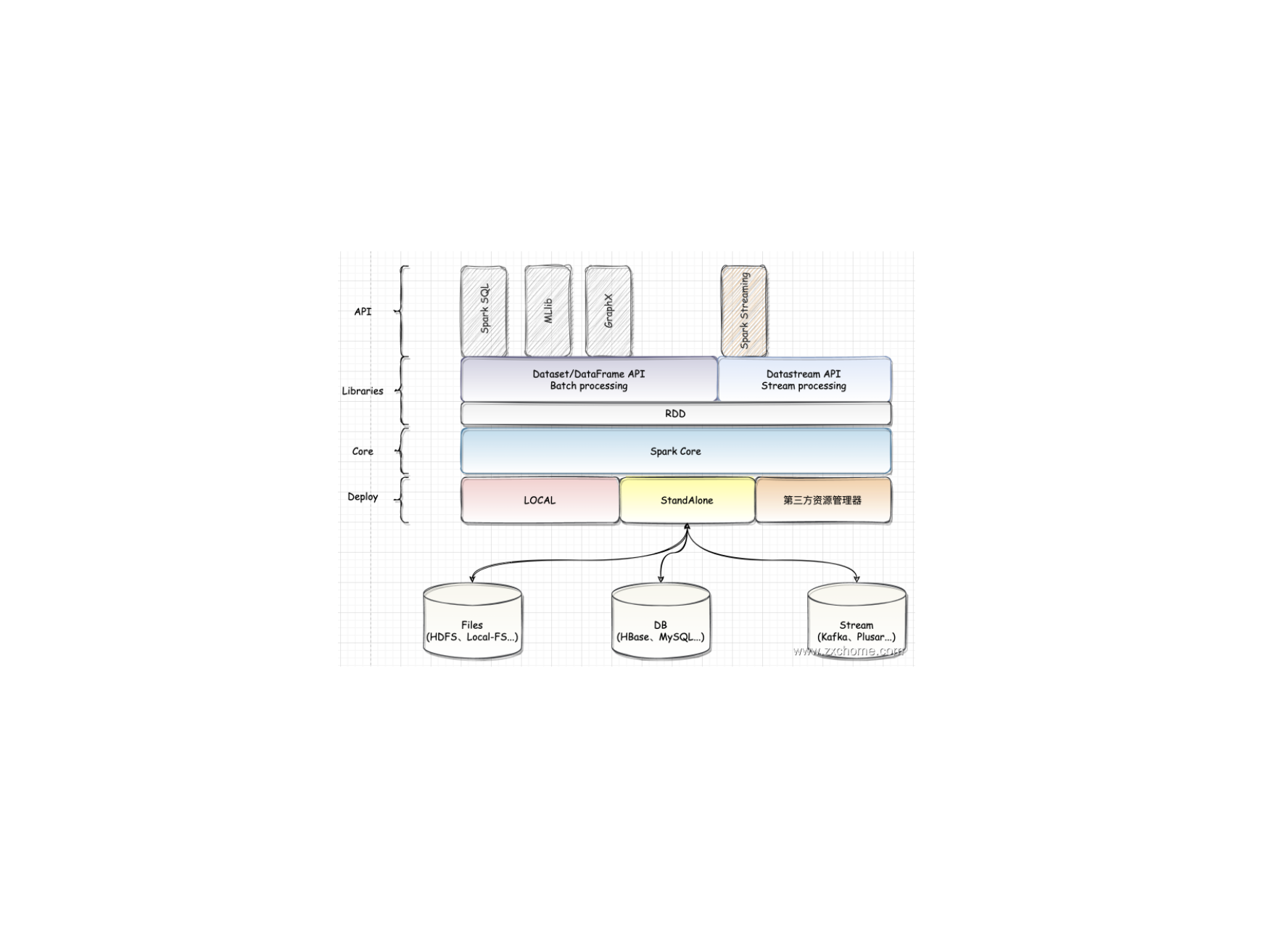
二、模块设计Spark 是一个功能丰富的大数据计算平台,与所有的大型系统一样,Spark 从设计到开发,也根据功能的不同进行模块的拆分。Spark 包含很多子模块,模块按照重要程度可分为核心功能和扩展功能。核心功能是 Spark 设计理念的核心实现,也是 Spark 陆续加入新功能的基础。在核心功能之上,通过不断地将丰富的扩展功能持续集成到 Spark。
2.1. Spark CoreSpark Core 提供了 Spark 最基础与最核心的功能。
2.1.1. 基础服务设施在 Spark 中有很多基础设施,被 Spark 中的各种组件广泛使用。这些基础设施包括 Spark 配置、通信设施、事件总线、度量系统等。
通信服务 RpcEnv
安全服务
对于 Spark 来说,我们需要考虑的三个方面的安全问题
权限管理
保证相应的用户不能做 ...

Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Planner 模块
一、概述物理计划阶段是 Spark SQL 整个查询处理流程的最后一步。不同于逻辑计划(LogicalPlan)的平台无关性,物理计划(PhysicalPlan) 是与底层平台紧密相关的。在此阶段,Spark SQL 会对生成的逻辑算子树进行进一步处理,得到物理算子树,并将 LogicalPlan 节点及其所包含的各种信息映射成 Spark Core 计算模型的元素,如 RDD、 Transformation 和 Action 等,以支持其提交执行。
在 SparkSQL 中,物理计划用 SparkPlan 表示,Spark SQL,最终将 SQL 语句经过逻辑算子树转换成物理算子树。在物理算子树中,叶子类型的 SparkPlan 节点负责 “从无到有” 地创建 RDD,每个非叶子类型的 SparkPlan 节点等价于在 RDD 上进行一次 Transformation,即通过调用 $execute$ 函数转换成新的 RDD,最终执行 $collect$ 操作触发计算,返回结果给用户。
二、架构设计Plan 模块主要经过 3 个阶段:
由 SparkPlanner 将各种物理计划 ...
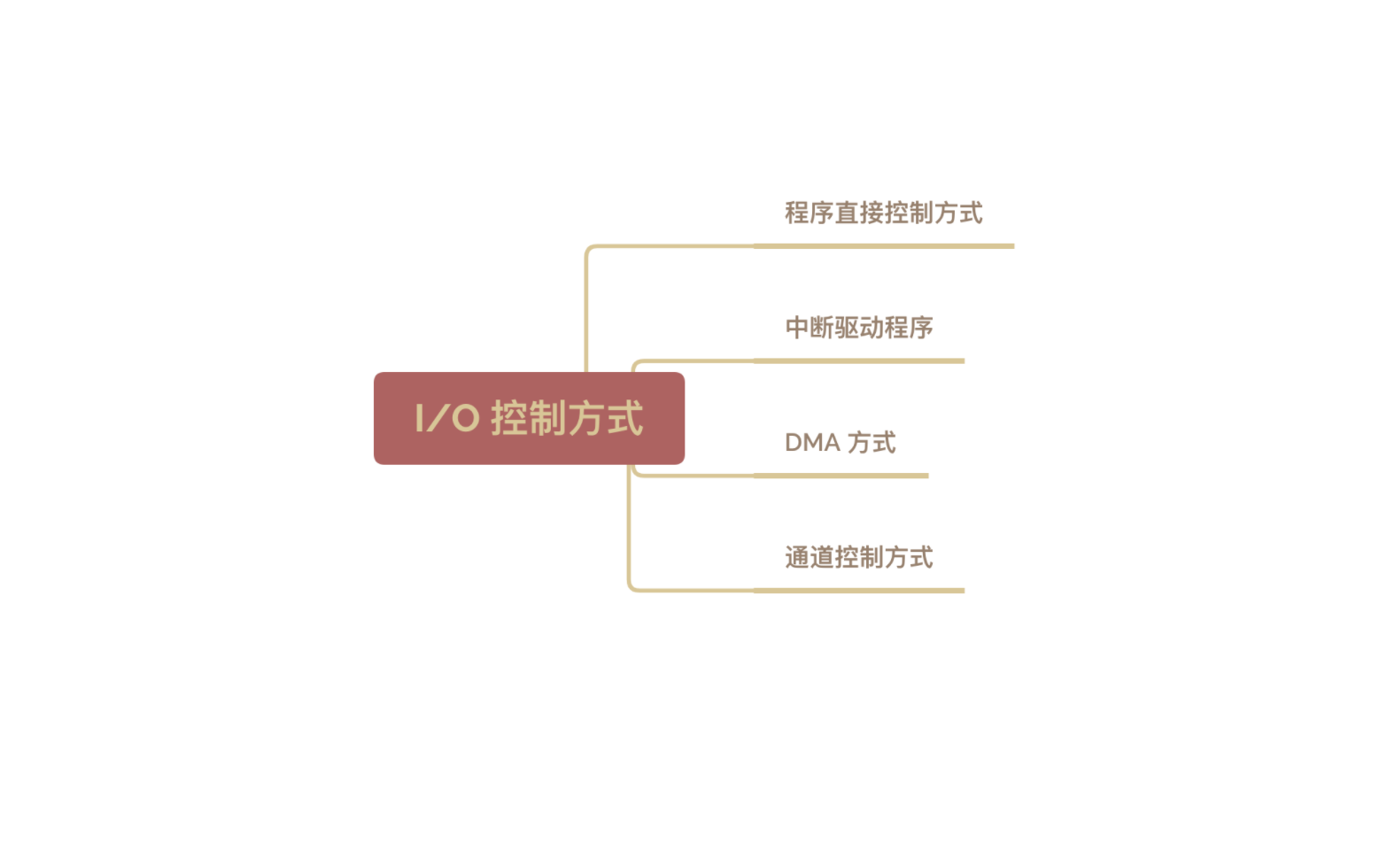
计算机基础-操作系统-IO-控制方式
需要注意的问题:
完成一次读/写操作的流程
CPU 干预的频率
数据传送的单位
数据的流向
主要缺点和优点
1. 程序直接控制
CPU 向控制器发出读指令。于是设备启动,并且状态寄存器设为1(未就绪)
轮询检查控制器的状态(其实就是在不断地执行程序的循环,若状态位一直是1,说明设备还没准备好要输入的数据,于是 CPU会不断地轮询)
输入设备准备好数据后将数据传给控制器,并报告自身状态
控制器将输入的数据放到数据寄存器中,并将状态改为0(已就绪)
CPU 发现设备已就绪,即可将数据寄存器中的内容读入 CPU 的寄存器中,再把 CPU 寄存器中的内容放入内存
1.1. CPU 干预的频率很频繁,I/O 操作开始之前、完成之后需要 CPU 介入,并且在等待 I/O 完成的过程中 CPU 需要不断地轮询检查。
1.2. 数据传送的单位每次读/写一个字
1.3. 数据的流向
读操作(数据输入): I/O设备→CPU(指的是 CPU 寄存器)→内存
写操作(数据输出): 内存→CPU(指的是 CPU 寄存器)→I/O设备
每个字的读/写都需要 CPU 的帮助
1.4. 主要缺点和 ...
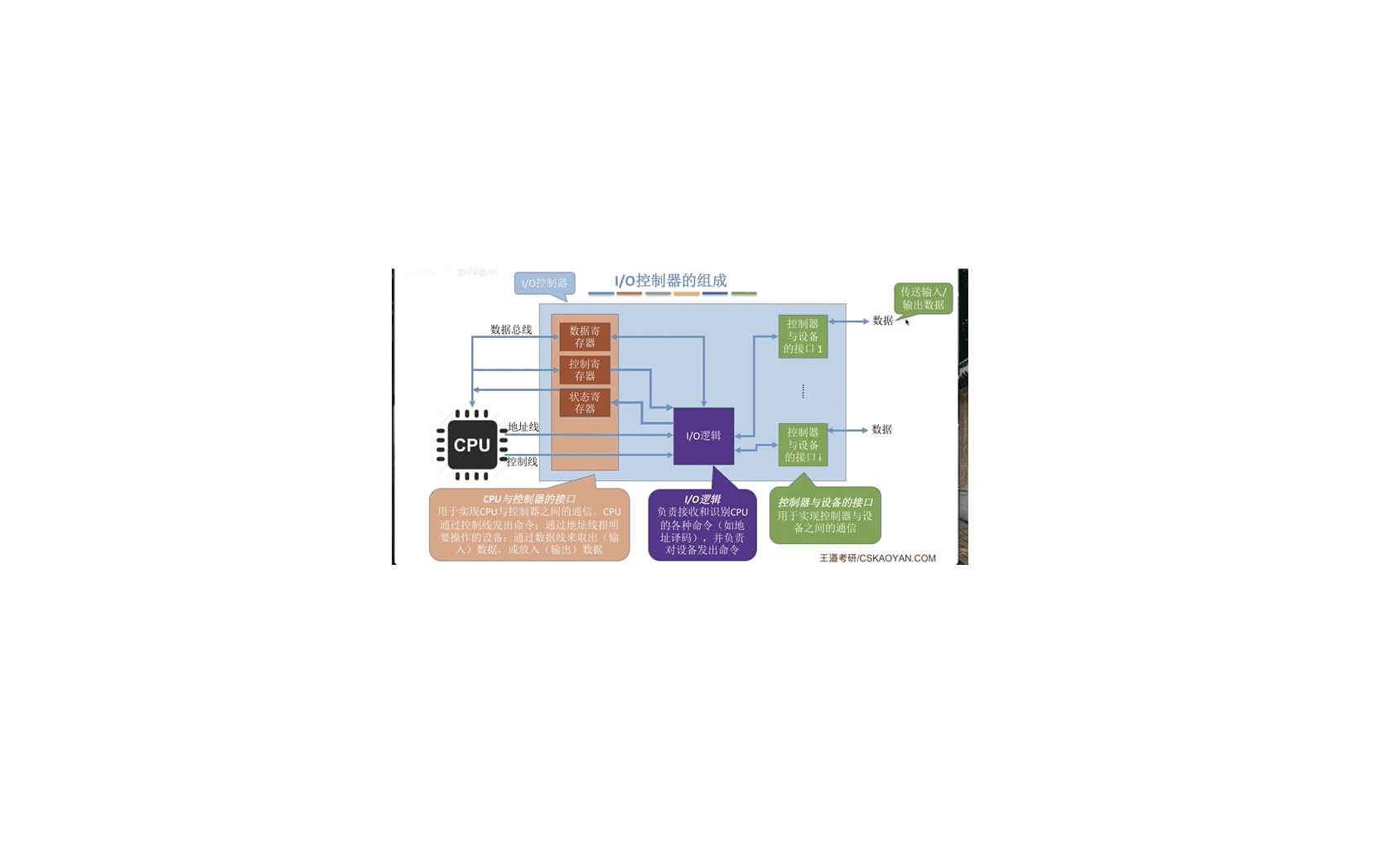
计算机基础-操作系统-IO-控制器
CPU 无法直接控制 IO 设备的机械部件,因此 IO 设备还要有个电子部件作为 CPU 和 IO 设备机械部件之间的”中介”,用于实现 CPU 对设备的控制。这个电子部件就是 IO 控制器,又称为设备控制器。CPU 可控制 IO 控制器,IO 控制器来控制设备的机械部件。
1. IO 控制器功能
接收和识别设备 CPU 指令
CPU 的读写指令和参数存储在控制寄存器中
如 CPU 发来的 read/write 命令,I/O 控制器中会有相应的控制寄存器来存放命令和参数
向 CPU 报告设备的状态
IO 控制器中会有相应的状态寄存器,用于记录 IO 设备的当前状态。(比如 1 代表设备忙碌,0 代表设备就绪)
数据交换
数据寄存器,输出时数据寄存器用来寄存 CPU 发来的数据,之后再由控制器传送设备。输入时,数据寄存器用于暂存设备发来的数据,之后 CPU 从数据寄存器取走数据
地址识别
类似于内存的地址,为了区分设备控制器中的各个寄存器,需要给各个寄存器设置一个特定的地址。IO 控制器通过CPU 提供的地址来判断 CPU 要读写的是哪个寄存器。
2. IO ...

磁盘管理
I/O 设备就是”输入/输出(Input / Output),I/O 设备就是可以将数据输入到计算机,或者可以接收计算机输出数据的外部设备,属于计算机中的硬件部件。UNIX 系统将外部设备抽象为一种特殊的文件,用户可以使用与文件操作相同的方式对外部设备进行操作。
UNIX 系统将外部设备抽象为一种特殊的文件,用户可以使用与文件操作相同的方式对外部设备进行操作。
1. I/O 设备分类1.1. 使用特性
人机交互类外部设备
人机交互类外设: 鼠标、键盘、打印机等一一用于人机交互
数据传输速率慢
存储设备
存储设备:移动硬盘、光盘等一一用于数据存储
数据传输速率快
网络通信设备
网络通信设备:调制解调器等一一用于网络通信
数据传输速度介于上述二者之间
1.2. 传输速率分类
1.3. 按信息交换的单位分类
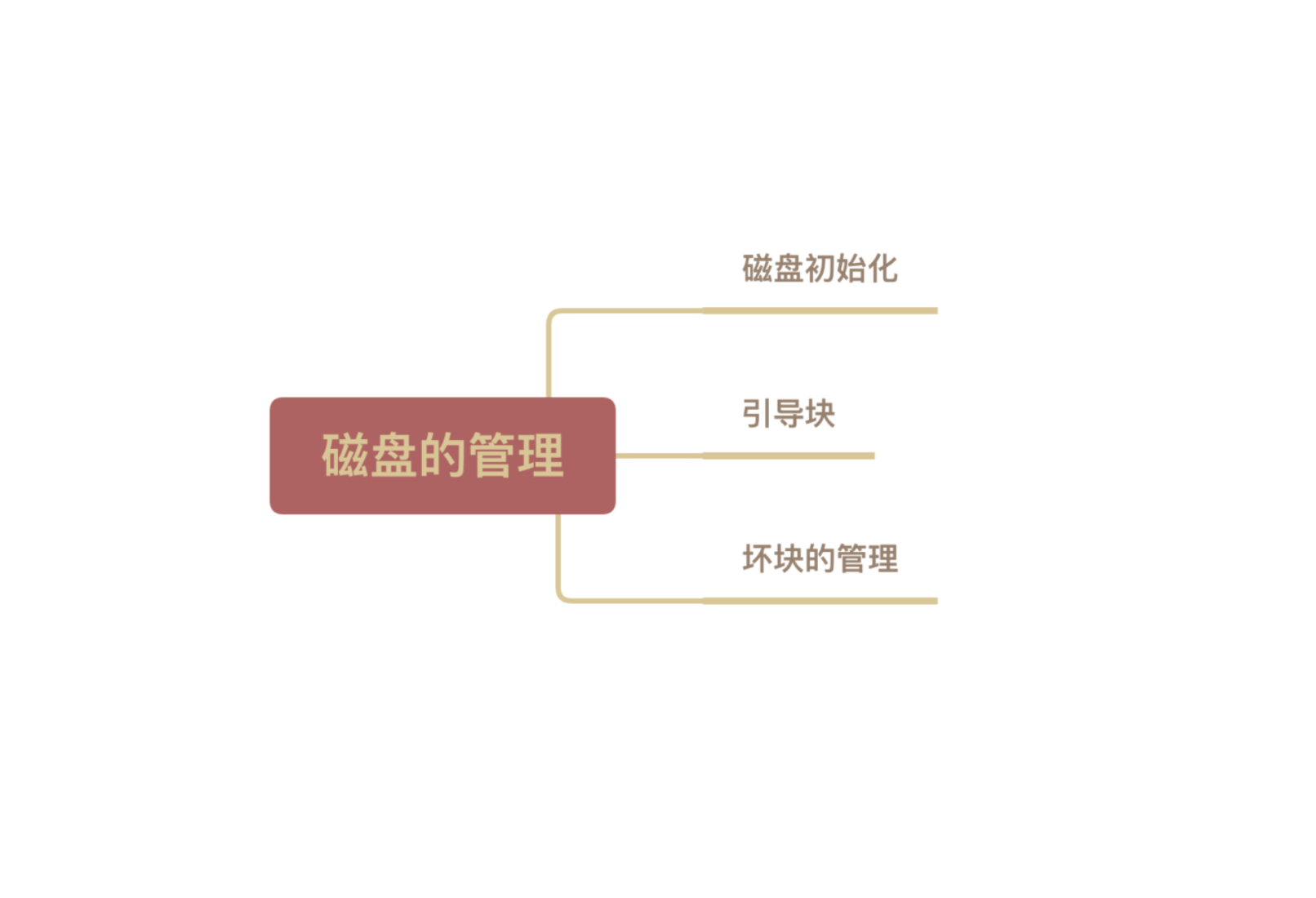
计算机基础-操作系统-磁盘管理
磁盘存储器具有容量大、存取速度快、支持随机存取的特点,因此被广泛应用于计算机系统中。对于操作系统来说,管理好磁盘的三大要求和目标是:
1. 磁盘初始化
进行低级格式化(物理格式化),将磁盘的各个磁道划分为扇区。一个扇区通常可分为头、数据区域(如512B大小)、尾三个部分组成。管理扇区所需要的各种数据结构一般存放在头、尾两个部分,包括扇区校验码(如奇偶校验、CRC循环冗余校验码等,校验码用于校验扇区中的数据是否发生错误)
将磁盘分区,每个分区由若干柱面组成(即分为 C盘、D盘、E盘)
进行逻辑格式化,创建文件系统。包括创建文件系统的根目录、初始化存储空间管理所用的数据结构(如位示图、空闲分区表)
2. 引导块计算机开机时需要进行一系列初始化的工作,这些初始化工作是通过执行初始化程序(自举程序)完成的。初始化程序可以放在 ROM(只读存储器)中。ROM 中的数据在出厂时就写入了,并且以后不能再修改。ROM一般在出厂时就集成到了主板之上。
以前的操作系统
计算机开机时,先读取 ROM 中程序并执行,完成初始化工作
初始化程序程序(自举程序)放在 ROM 中万一需要更新自举程 ...
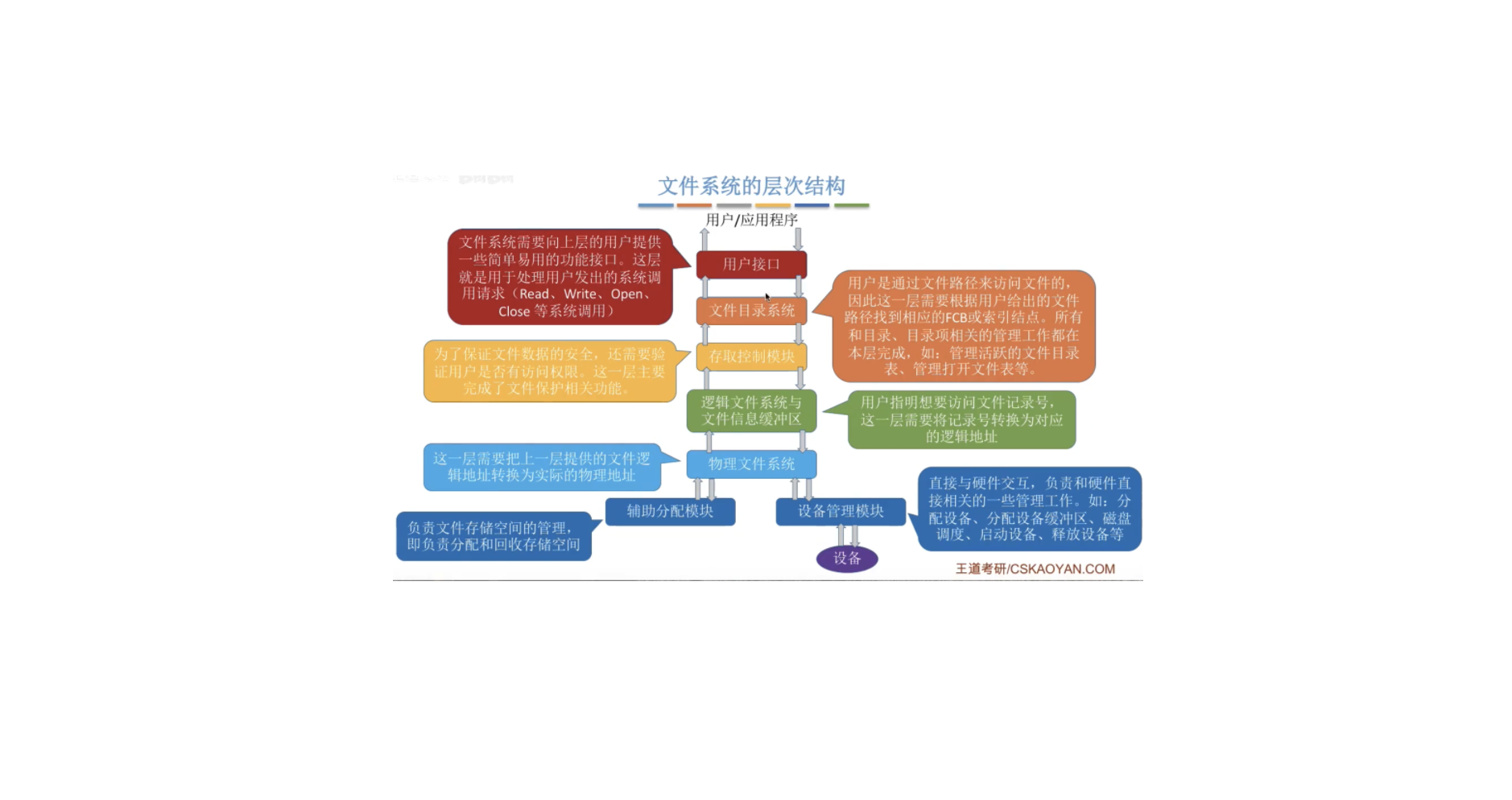
计算机基础-操作系统-文件系统的层次结构
现代操作系统有多种文件系统类型(如FAT32、NTFS、 ext2、ext3、ext4等),因此文件系统的层次结构也不尽相同
用户调用接口
文件系统为用户提供与文件及目录有关的调用,如新建、打开、读写、关闭、删除文件,建立、删除目录等。此层由若干程序模块组成,每一模块对应一条系统调用,用户发出系统调用时,控制即转入相应的模块。
文件目录系统
文件目录系统的主要功能是管理文件目录,其任务有管理活跃文件目录表、管理读写状态信息表、管理用户进程的打开文件表、管理与组织在存储设备上的文件目录结构、调用下一级存取控制模块。
存取控制验证
实现文件保护主要由该级软件完成,它把用户的访问要求与FCB中指示的访问控制权限进行比较,以确认访问的合法性。
逻辑文件系统与文件信息缓冲区
逻辑文件系统与文件信息缓冲区的主要功能是根据文件的逻辑结构将用户要读写的逻辑记录转换成文件逻辑结构内的相应块号。
物理文件系统
物理文件系统的主要功能是把逻辑记录所在的相对块号转换成实际的物理地址。
分配模块
分配模块的主要功能是管理辅存空间,即负责分配辅存空闲空间和回收辅存空间。
设备管理程序模块
设 ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Optimizer 模块-Rule-V2ScanRelationPushDown
一、概述二、实现1234567891011121314def apply(plan: LogicalPlan): LogicalPlan = { val pushdownRules = Seq[LogicalPlan => LogicalPlan] ( createScanBuilder, pushDownSample, pushDownFilters, pushDownAggregates, pushDownLimitAndOffset, buildScanWithPushedAggregate, pruneColumns) pushdownRules.foldLeft(plan) { (newPlan, pushDownRule) => pushDownRule(newPlan) }}
2.1. createScanBuilder()$createScanBuilder()$ 方法对 DataSourceV2Relation 类型转换为 ScanBuilderHolder ...
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Optimizer 模块
一、概述经过 Analyzer 的处理,Unresolved LogicalPlan 解析为 Analyzed LogicalPlan,在实际应用中,很多低效的写法会带来执行效率的问题,需要进一步对 Analyzed LogicalPlan 进行优化处理,得到优化后的逻辑算子树。
二、实现2.1. RuleExecutorOptimizer 继承自 RuleExecutor 类,本身没有重载 RuleExecutor 中的 $execute()$ 方法,因此其执行过程仍然是调用其父类 RuleExecutor 中实现的 execute 方法。在 QueryExecution 中,Optimizer 会对传入的 Analyzed LogicalPlan 执行 $execute()$ 方法,启动优化过程。
引用本站文章
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Rule 体系
Joker
...
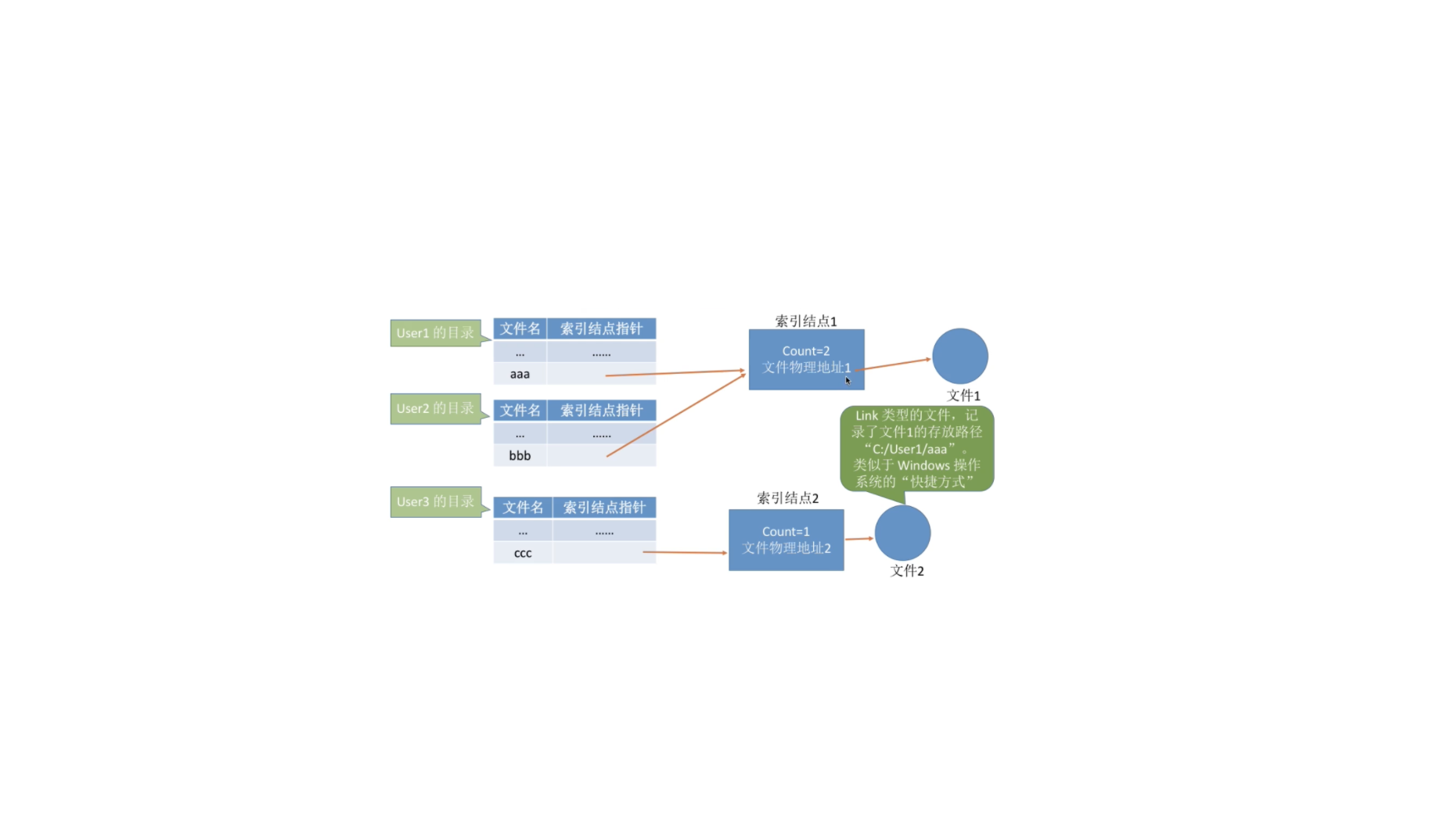
计算机基础-操作系统-文件共享
文件共享可以提高文件的利用率,避免存储空间的浪费,并能实现用户用自己的文件名去访问共享文件。实现文件共享通常有以下5种方法。
操作系统为用户提供文件共享功能,可以让多个用户共享地使用同一个文件
多个用户共享同一个文件,意味着系统中只有“一份〞文件数据。并且只要某个用户修改了该文件的数据,其他用户也可以看到文件数据的变化。如果是多个用户都“复制”了同一个文件,那么系统中会有“好几份”文件数据。其中一个用户修改了自己的那份文件数据,对其他用户的文件数据并没有影啊。
利用符号链实现文件共享当 User3 访问 “ccc” 时,操作系统判断文件 “ccc” 属于 Link 类型文件,于是会根据其中记录的路径层层查找目录,最终找到 User1 的目录表中的 “aaa” 表项,于是就找到了文件 1 的索引结点。
Windows 中快捷方式:
基于索引结点的共享方式索引结点是一种文件目录瘦身策路。由于检索文件时只需用到文件名,因此可以将除了文件名之外的其他信息放到索引结点中。这样目录项就只需要包含文件名、索引结点指针。
索引结点中设置一个链接计数变量 count,用于表示链接 ...
公告
喜欢本博客的话可以扫描下方二维码加我 QQ, 有福利哦😯~。
通讯录
书籍 5

Hadoop 2.X 源码剖析
以Hadoop 2.6.0源码为基础, 深入剖析了HDFS 2.X中各个模块的实现细节。

Spark SQL 内核剖析
2018年08月电子工业出版社出版的图书。

高性能 MySQL 第3版
MySQL 领域的经典之作

深入理解 Kafka_核心设计与实践原理
我喜欢的一本有关 Kafka 的书籍之一~

Apache-Kafka 源码剖析
本书以 Kafka 0.10.0 版本源码为基础, 针对 Kafka 的架构设计到实现细节进行详细阐述~

开源项目~ 7

Flink
Stateful Computations over Data Streams

Hadoop
Open-source software for reliable, scalable, distributed computing.

Spark
Unified engine for large-scale data analytics

Iceberg
Iceberg is a high-performance format for huge analytic tables

Hudi
Apache Hudi is a transactional data lake platform

Kubernetes
Production-Grade Container Orchestration

Paimon
Streaming data lake platform.