
Flink-源码学习-FlinkSQL&Table-元数据体系
一、概述
为了使用 SQL,首先需要解决的是元数据管理的问题。包括 Table/UDF/View 元数据的注册、查询以及验证。
二、架构设计
2.1. 元数据注册
FinkSQL 原生支持了 DDL 语法,比如 CREATE 语句,通过 Catalog API 将表/视图/函数 注册到当前或指定的 Catalog 中,默认使用 InMemoryCatalog 将信息临时保存在内存中,有一个唯一的 ID,由三部分组成: 目录 (catalog)、数据库 (database) 名、表名。
在默认情况下,目录名为 defaultcatalog、数据库名为 default database。故直接创建一个 test 表,它的 ID 是:
defaultcatalog.default database.MyTable
同时也提供了 HiveCatalog 与 HiveMetastore 进行集成。
FlinkSQL 目前支持以下 CREATE 语句:
- CREATE TABLE
- CREATE CATALOG
- CREATE DATABASE
- CREATE VIEW
- CREATE FUNCTION
2.2. 元数据查询
已注册的表/视图/函数可以在 SQL 查询中使用,Catalog API 能够支持对数据库、表、函数、甚至于分区等多种抽象的查询。通过 CatalogManager,可以同时在一个会话中挂载多个 Catalog,从而访问到多个不同的外部系统。
2.3. 元数据验证
FlinkSQL 依赖于 Calcite 來完成 SQL 语句的解折和逻辑计划的优化过程,因此需要将 Catalog 和 Calcite 使用的 Schema 桥接起来,这样 Calcite 才可以获取到由 Flink 管理的元数据。
2.3.1. Calcite 接口
Schema
Schema 接口提供了一种统一的接口来访问和管理各种类型的数据源。
1
2
3
4
5public interface Schema {
Table getTable(String name);
Schema getSubSchema (String name);
...
}
2.3.2. FlinkSchema
FlinkSchema 基于 Apache Calcite 提供了一种简单、统一的接口,用于访问和管理 Flink 任务中的表、视图和函数等元数据。FlinkSchema 将 Flink 的元数据映射到 Calcite Schema 中的对象上,同时提供了一组 API,用于查询和管理元数据。使用户可以方便地使用 Table/SQL API 进行数据分析和处理。
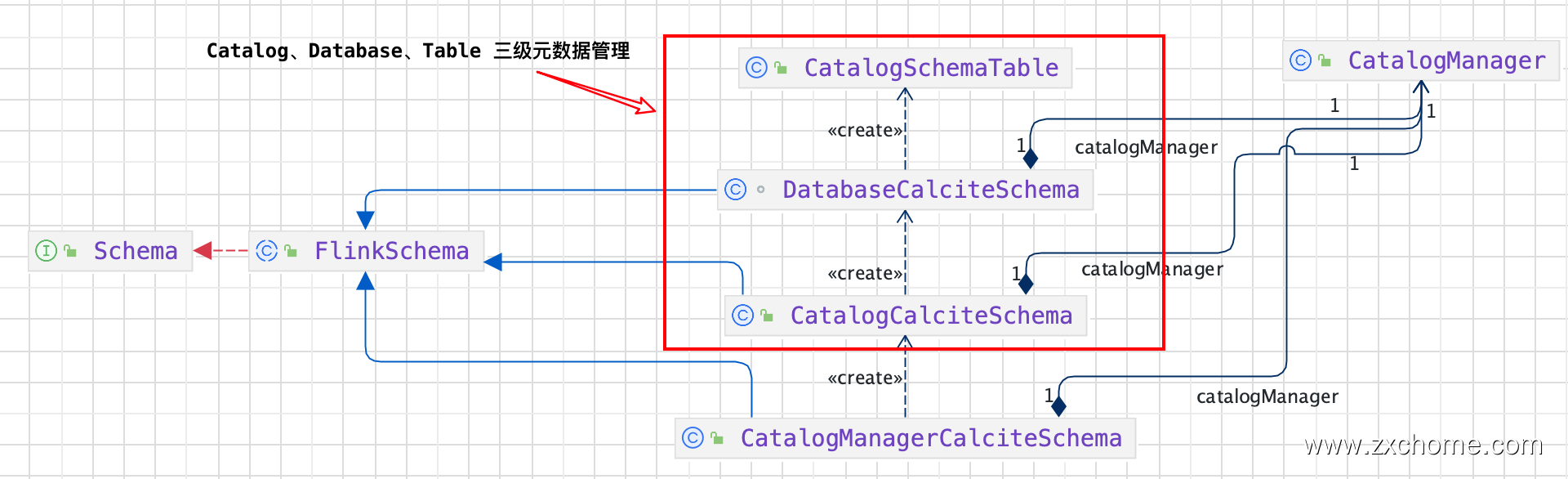
FlinkSchema 包含三个子类分别为: CatalogManagerCalciteSchema、CatalogCalciteSchema 以及 DatabaseCalciteSchema。
在 Calcite 进行 Validate 时,CatalogManagerCalciteSchema 和 CatalogCalciteschema 通过调用重写 $FlinkSchema.getSubSchema()$ 方法依次获取 Catalog、 Database 信息。最终 DatabaseCalciteSchema 从 CatalogManager 中获取对应的 Table 信息,返回 CatalogSchemaTable
所以 Flink SQL 元数据的管理分为三层:Catalog-> Database-> Table。
2.3.3. 验证
FlinkSchema 及其子类:CatalogManagerCalciteSchema, CatalogCalciteSchema 以及 DatabaseCalciteSchema 都是 Flink 用于适配 Apache Calcite 框架元数据的相关实现。
那么这些类具体是在哪里调用的🤔️?
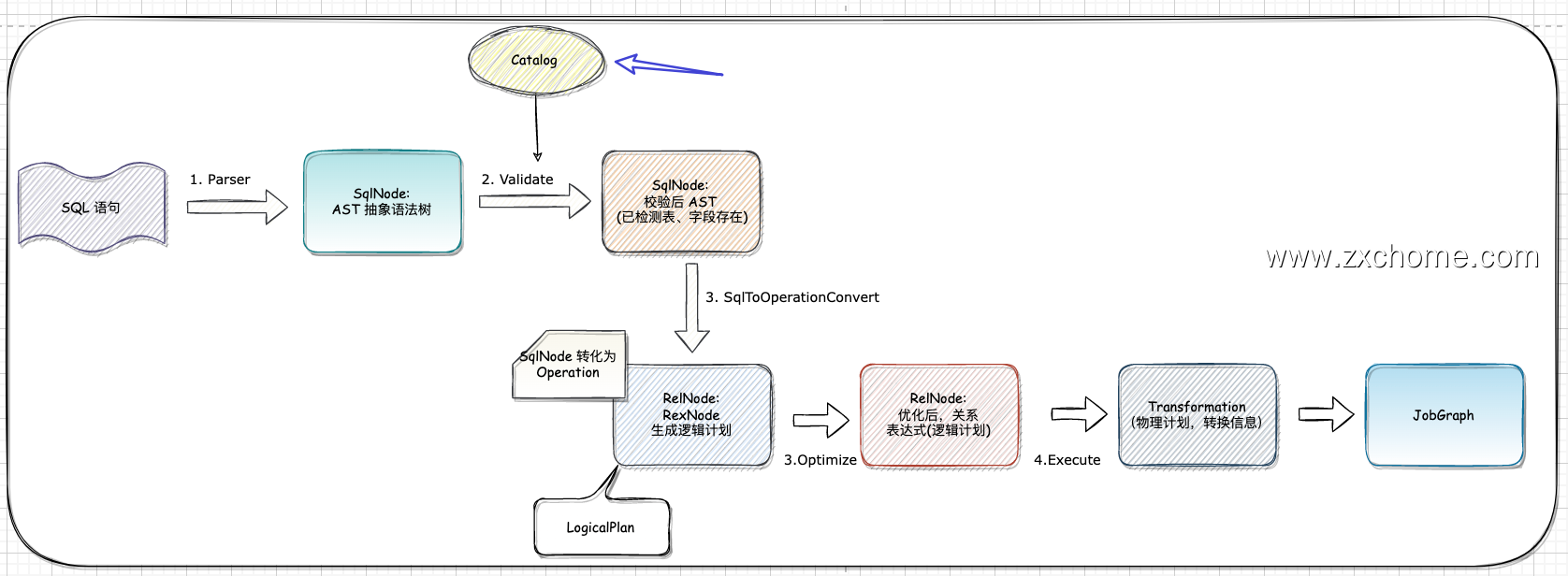
Calcite 中的 Schema 在 Validate 过程中,获得对应 table 的字段信息,对应的 function 的返回值信息,确保 SQL 的字段名,字段类型是正确的。
类的依赖关系为: validator —> SchemaReader —> Schema
三、总结
3.1. Refer
 微信
微信 支付宝
支付宝






