
Spark-理论笔记-任务调度
一、概述
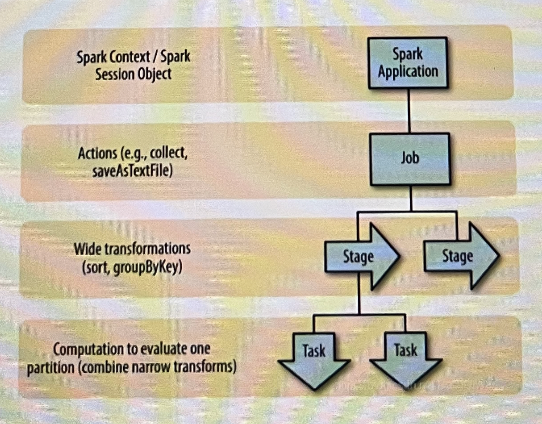
一个 Spark Application 包括 Job、 Stage 以及 Task 三个概念:
Job
由于 Spark 的懒执行,在 driver 调用一个action 之前,spark application 不会做任何事情。针对每个 action,Spark调度
器就创建一个执行图(execution.graph) 并且启动一个 Spark Job。stage
每个 job有多个 stage组成,这些stage就是实现最终的RDD所需的数据转换的步骤,以 RDD 宽依赖为界,遇到宽依赖即划分 stage,
task
每个stage由多个tasks组成,这些tasks就表示每个并行计算并且会在多个执行器上执行
在 Spark 中,调度执行一个Job 总体分两路进行:Stage 级的调度和 Task 级的调度~
二、Job 触发
三、Stage 级调度
https://blog.csdn.net/swg321321/article/details/125646366
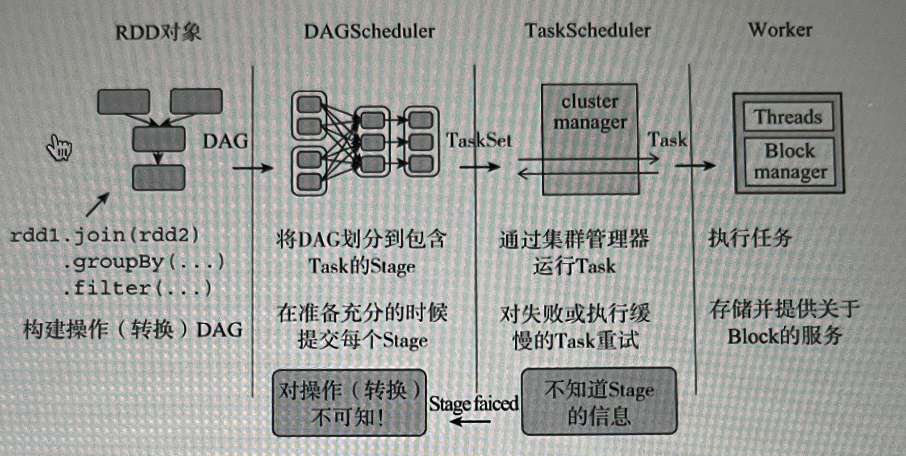
Spark 中 DAGScheduler 实现了面向 stage 的调度
3.1. stage 划分
DAGScheduler 会将 Job 的 RDD 划分到不同的 Stage,并构建这些 Stage 的依赖关系。这样可以使得没有依赖关系的 Stage 并行执行,并保证有依赖关系的 Stage 顺序执行。 并行执行能够有效利用集群资源,提升运行效率,而串行执行则适用于那些在时间和数据资源上存在强制依赖的场景。
3.1.1.划分策略
DAGScheduler 具体划分策略是,由最终的 RDD 不断通过依赖回湖判断父依赖是否是宽依赖,窄依赖的 RDD 被划分到同一个 Stage 中, 划分的 Stages 分两类, 需要处理 Shuffle 的 ShuffleMapStage 和最下游的 ResultStage, 上游 Stage 先于下游 Stage 执行, ResultStage 是最后执行的 Stage。
ResultStage
可以使用指定的函数对 RDD 中的分区进行计算并得出最终结果。ResultStage 是最后执行的 Stage,此阶段主要进行作业的收尾工作例如,对各个分区的数据收拢、打印到控制台或写入到 HDFS
ShuffleMapStage
ShuffleMapStage 是 DAG 调度流程的中间 Stage, 包括一到多个 ShuffleMapTask, ShuffleMapStage 一般是 ResultStage 或者其他 ShuffleMapStage 的前置 Stage
3.1.2. 划分分析
3.2. stage 提交
一个 Stage 是否被提交,需要判断盛的之 Stage 是否执行,只有在公 Stage 执行完毕才能提交当前 Stage,如果一个 Stage 没有父 Stage,那么从该 Stage 开始提交。Stage提交时会将Task 信息[分区信息以及方法等]序列化并被打包成 TaskSet 交给 TaskScheduler, 一个 Partition 对应一 Task。
DAGScheduler 划分 Stage,通过调用 submitStage() 来提交一个 Stage 对应的 tasks, submitStage 通过调用
getPreferrdeLocations() 得到 task 的优先位置,根据每个 task 的优先位置, 确定 task 的 Locality 级别,Locality一共有五种,优
先级由高到低顺序
3.3. stage 调度器
四、Task 级调度
任务调度器 TaskScheduler 定义了对任务进行调度的接四规范,允许向Spark调度系统插入不同的TaskScheduler实现,但目前只
有 TaskSchedulerImpl 这一个具体实现。
4.1. TaskSetManager
4.2. Task 调度器
5. 总结
 微信
微信 支付宝
支付宝





