Spark-源码学习-SparkCore-存储服务-内存组件-Memstore
一、概述
MemoryStore 负责 Spark 内存存储,管理以 MemoryEntry 为父接口的内存对象,实现了一个简单的基于 Block 的内存数据库,用来管理需要写入到内存中的 Block 数据。可以按序列化或非序列化的形式存放块数据,存放这两种块数据的数据结构是不同的,但都必须实现 MemoryEntry 接口~
二、内存结构
2.1. 已使用内存
已经使用的内存,内存里存放 entries 中,该 entries 由不同数据块生成的 MemoryEntry 构成,MemoryStore 通过以 MemoryEntry 对象为元素的 LinkedHashMap 来管理 MemoryEntry 数据。LinkedHashMap 是一个有序的 HashMap,这样可以按插入顺序来对元素进行管理,此时各个节点构成了一个双向链表。
1 | private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true) |
MemoryStore 不仅使用了 LinkedHashMap 的基本特性,还使用了其按访问顺序的特性。MemoryStore 创建 LinkedHashMap 时参数 accessOrder 默认是 true,会按访问元素的先后顺序把访问过的元素放到双向链表的末尾。这其实就形成了一个 LRU 队列。
缓存数据是不可靠的,当内存不够时,会按LRU算法来淘汰内存块。而 LinkedHashMap 就是该算法的底层数据结构支持。
LinkedHashMap 线程不安全的,在进行其元素的读写操作时,必须加锁
2.1.1. MemoryEntry 结构
MemoryStore 负责将 Block 存储到内存, 依赖于 MemoryManager 的服务, Spark 将内存中的 Block 抽象为特质 MemoryEntry,MemoryEntry 是 MemoryStore 中的管理的成员结构。
1 | private sealed trait MemoryEntry[T] { |
MemoryEntry 有两种实现: 一种是 DeserializedMemoryEntry,用来保存非序列化块数据;一种是SerializedMemoryEntry,用来保存序列化块数据。
DeserializedMemoryEntry
非序列化的块数据都通过该类来进行封装,非序列化的块数据只能保存在 JVM 的堆中,只能使用堆内内存。在堆内内存中,DeserializedMemoryEntry 通过一个数组来保存不同类型的块数据。
1
2
3
4
5
6private case class DeserializedMemoryEntry[T](
value: Array[T], // 保存块数据的数组
size: Long,
classTag: ClassTag[T]) extends MemoryEntry[T] {
val memoryMode: MemoryMode = MemoryMode.ON_HEAP // 非序列化数据只能使用堆内内存存储
}SerializedMemoryEntry
序列化的块数据其实是一组字节数据的集合,MemoryStore 使用专门的结构: ChunkedByteBuffer 来进行保存。序列化块数据可以保存在堆内和堆外内存中。
1
2
3
4
5
6private case class SerializedMemoryEntry[T](
buffer: ChunkedByteBuffer, // 保存序列化数据
memoryMode: MemoryMode, //内存模式
classTag: ClassTag[T]) extends MemoryEntry[T] {
def size: Long = buffer.size // 块数据大小是 buffer 的大小
}ChunkedByteBuffer 对象本质上是字节流 ByteBuffer 的数组,也就是: Array[ByteBuffer]
2.2. Unroll
MemoryStore 利用 ValuesHolder 对 Iterator 进行展开 Unroll,数据存储到 ValuesHolder 封装的数据结构(Vector 或 OutputStream)中,这些数据在之后封装为 MemoryEntry 的过程中,仅仅通过 $toArray$、$toByteBuffer$ 等操作在数据类型上做了转换,并没有带来额外的内存消耗。
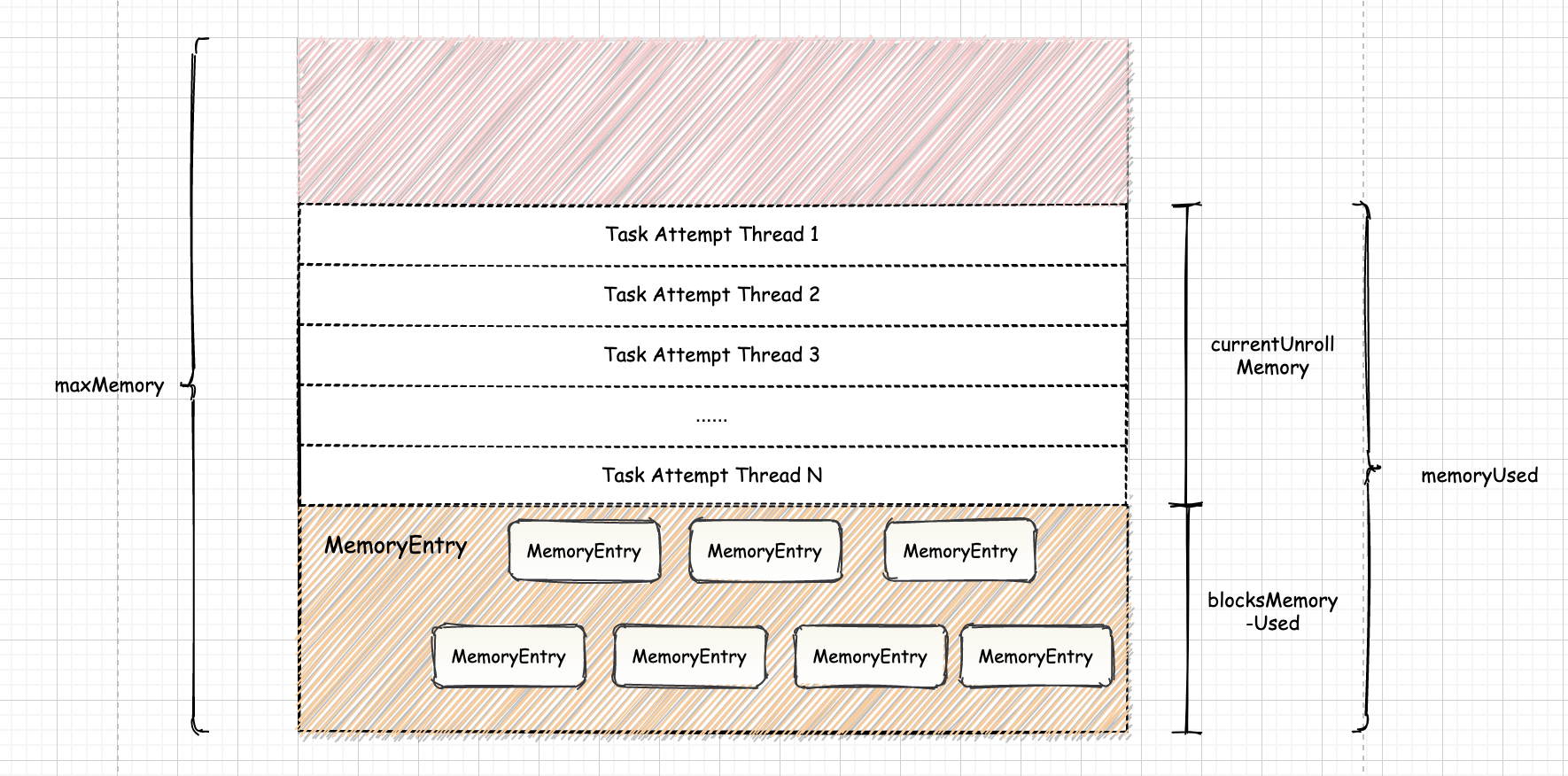
Unroll 类似生活中的”占座”, 可以防上在需要座位的时候,发现已经没有了位置。即可以防止在向内存真正写数据时,内存不足发生溢出。在 Spark 中 blocksMemoryUsed 和 currentUnrollMemory 的空间之和是已经使用的空间, 用
memoryUsed表示。
2.2.1. ValuesHolder

ValuesHolder 特质有两个实现类: DeserializedValuesHolder 和 SerializedValuesHolder,实现了以对象或字节数组的形式存储数据。
三、数据写入内存
MemoryStore 可以以序列化和非序列化的形式来写入数据。而这两种数据形式的存储结构也不相同。MemoryStore 提供了 $putIteratorAsValues()$ 和 $putIteratorAsBytes()$ 来将 RDD 数据分片对应的迭代器分别物化为对象和字节序列。
3.1. 数据写入
$MemoryStore.putIterator()$ 方法主要逻辑就是把数据一条一条往 ValuesHolder 中写,并周期性地检查内存,如果内存不够就通过内存管理器MemoryManager 申请内存,每次申请当前内存量的 1.5 倍。
最后,将 ValuesHolder 中的数据转移到一个数组中(其实数据在 SizeTrackingVector 中也是以数组的形式存储,只不过 SizeTrackingVector 对象内部处理数组还有一些其他的簿记量,更为关键的是我们需要将存储的数据以同一的接口进行包装,以利于 MemoryStor e进行同一管理)。
最后还有关键的一步,就是释放展开内存,重新申请存储内存。
1 | var elementsUnrolled = 0 |
3.1.1. 初始内存申请
进行初始的内存申请,向 MemoryManager 申请内存
1 | keepUnrolling = reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, memoryMode) |
1 | def reserveUnrollMemoryForThisTask(blockId: BlockId, memory: Long, memoryMode: MemoryMode): Boolean = { |
3.1.2. UnRoll
不断迭代读取 Iterator 中的数据, 将数据放入追踪器 ValuesHolder 中,并周期性地检查 ValuesHolder 中所有数据的估算大小 currentsize 是否
已经超过了 memoryThreshold。当发现 currentSize 超过 memoryThreshold, 则为当前任务请求新的保留内存。
内存大小的计算公式为: currentSize*memoryGrowthFactor-memoryThreshold
在堆上成功申请到足够的内存后,需要更新 unrollMemoryUsedByThisBlock 和 memoryThreshold 的大小
1 | while (values.hasNext && keepUnrolling) { |
3.1.3. 申请内存
1 | // keepUnrolling 为 true,说明顺利地将所有数据插入, |
- 获取信息:在数据块展开前,为该展开线程获取初始化内存,该内存大小为unrollMemoryThreshold,获取完毕后返回是否成功的结果keepUnrolling;
- 遍历:如果Iterator[T]存在元素且keepUnrolling为true,则继续向前遍历Iterator[T],内存展开元素的数量elementsUnrolled自增1。如果Iterator[T]到头或者keepUnrolling为false,则调到步骤4;
- 检测内存:每当memoryCheckPeriod继16次展开之后,就进行一次内存检测,检测展开的内存大小是否超过当前分配的内存。如果没有超过,则继续展开;如果内存不足,则根据增长因子计算需要增加的内存大小。如果申请成功,则将申请得到的内存加入到CurrentUnrollMemory,而展开线程获取的内存大小为:当前展开大小*内存增长因子;
- 展开内存:判断数据块是否展开成功,如果失败,则记录为内存不足,并退出;如果成功,则继续下一步;

3.2. 序列化数据写入
$MemoryStore.putBytes()$
序列化数据的写入是通过函数 $MemoryStore.putBytes()$ 来实现的。并需要使用内存管理模块来确保内存大小,若内存不够还需要通过内存管理模块来释放内存。

- 判断 blockId 对应的内存块是否已经在 MemoryStore 中存在,若存在,则中断执行并抛出异常。
1
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
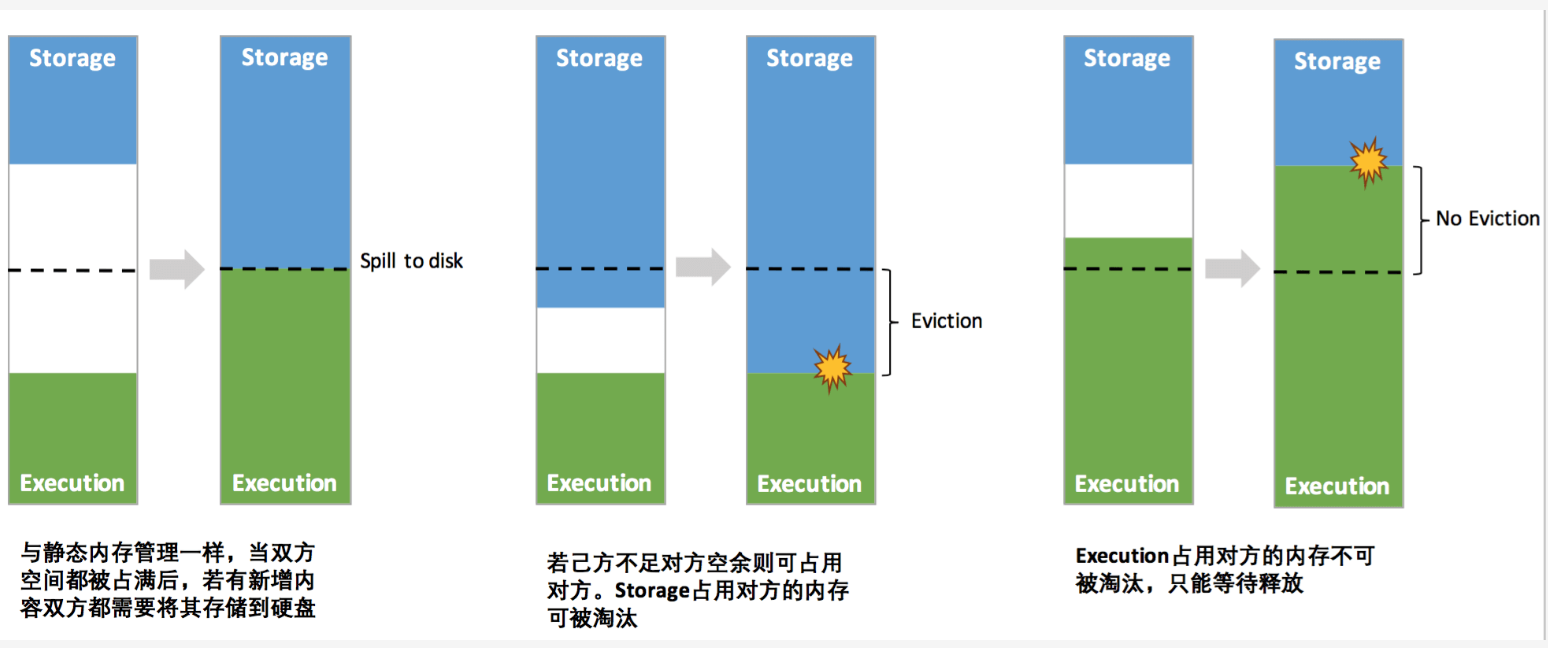
调用 $memoryManager.acquireStorageMemory()$ 来判断在给定的 memoryMode 模式下内存是否足够,若不够则需要通过统一内存管理模块来从执行池中借用一部分内存,若执行内存池空闲内存不够,则需要把存储池中一部分内存进行持久化,并释放这部分内存
引用本站文章Spark-源码学习-SparkCore-存储服务-内存组件-内存管理器 UnifiedMemoryManagerJoker创建一个 ChunkedByteBuffer 对象,需要根据参数给定的匿名函数进行创建
1
val bytes = _bytes()
创建一个 SerializedMemoryEntry 对象,并把 bytes 作为参数传入
1
val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]])
在 LinkedHashMap 对象 entries上 加锁,并调用: $entries.put()$ 把数据写入 LinkedHashMap 中
1
2
3entries.synchronized {
entries.put(blockId, entry)
}
$MemoryStore.putIteratorAsBytes()$
$putIteratorAsBytes()$ 方法相对 $putBytes()$ 用 Iterator[T] 形式表示块数据,增加了 “展开 Unroll” 操作,避免单个 Block 对应的数据可能过大,不能一次性存入内存。为了避免造成 OOM,就可以一边遍历迭代器,一边周期性地写内存,并检查内存是否够用,就像翻书一样,类似方法还有 $putIteratorAsValues()$
3.3. 非序列化数据的写入
$putIteratorAsValues()$ 方法主要是用于存储级别是非序列化的情况,即直接以 Java 对象的形式将数据存放在 JVM 堆内存上。
在 JVM 堆内存上存放大量的对象能引起频繁的 GC,但是省去了序列化和反序列化耗时,而且直接从堆内存取数据比其他方式(磁盘和直接内存)都要快很多,所以对于内存充足且要缓存的数据量本省不是很大的情况,这种方式是一种不错的选择~
$putIteratorAsValues()$ 方法主要逻辑是对实际存储方法 $putIterator()$ 的返回结果做处理,如果失败,封装 PartiallyUnrolledIterator 返回给外部调用这个,调用这个一般需要将这个写入一半的迭代器关闭。
1 | private[storage] def putIteratorAsValues[T]( |
四、读取内存数据
MemoryStore 提供 $getValues()$ 和 $getBytes()$ 方法,根据 BlockId 分别访问对象值与字节序列,两种方法首先通过 BlockId 获取到对应的 DeserializedMemoryEntry 或 SerializedMemoryEntry,然后在通过访问各自封装的 Array[T] 和 ByteBuffer 来读取数据内容。
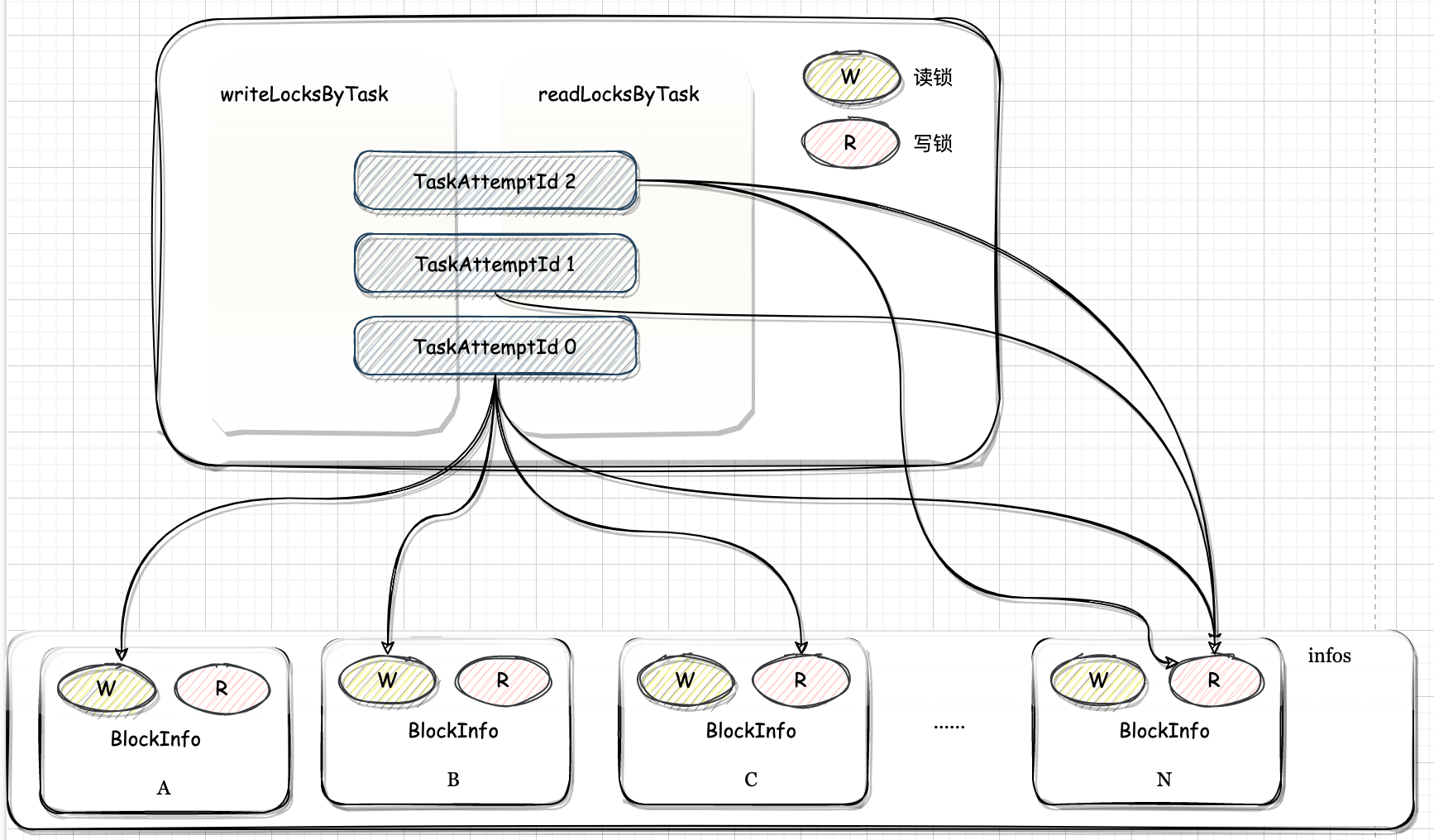
在读取内存数据块时,需要加锁。
五、淘汰内存数据
当执行任务或缓存数据空闲内存不足时,可能会释放一部分存储内存,若对应的 rdd 的存储级别设置了 useDisk,则会把内存中的数据持久化到磁盘上。完成以上操作的函数是: $MemoryStore.evictBlocksToFreeSpace()$ 函数。
其中的 blockId 是数据块的id,每个 id 都对应一个内存块。释放内存块的逻辑如下:
遍历内存块的队列 LinkedHashMap: entries
entries 最后一次被访问的内存块节点会放到链表的后面,这样最近没有被访问的内存块就在队列的头部。需要淘汰内存块时,只需要从头部选择一个进行删除即可。这就是 LRU 内存数据淘汰机制。
检查内存块是否可以被释放。释放内存块需要满足以下条件:
1
2
3def blockIsEvictable(blockId: BlockId, entry: MemoryEntry[_]): Boolean = {
entry.memoryMode == memoryMode && (rddToAdd.isEmpty || rddToAdd != getRddId(blockId))
}- 内存块的模式必须和参数中 memoryMode 的值相等
- 该 blockId 对应的内存块没有被其他 RDD 占用,或则不是要替换相同 RDD 的不同数据块。
若满足以上两个条件,就会释放该内存块。释放内存块的过程如下:
1
2
3
4if (blockInfoManager.lockForWriting(blockId, blocking = false).isDefined) {
selectedBlocks += blockId
freedMemory += entry.size
}- 确认内存块的写锁已经锁上了
- 通过 blockId 的信息检查存储级别是否包含 useDisk,若包含则把内存的数据写入到磁盘上。写入磁盘的过程是通过 DiskStore 对象来完成的。
从 MemoryStore 的中删除、释放 blockId 对应的内存块,并减少 MemoryStore 的内存数量。
BlockManager 实现了特质 BlockEvictionHandler,并重写了 $dropFromMemory()$ 方法,BlockManager 在构造 MemoryStore 时,将自身的引用作为 blockEvictionHandler 参数传递给 MemoryStore 的构造器,因而 BlockEvictionHandler 就是 BlockManager。所以删除内存块的操作是在 $BlockManager.dropFromMemory()$ 中完成,因为,内存块删除后可能会把数据写入到磁盘上,此时此数据块的存储级别就发生了改变,需要通过BlockManager 来把数据的最新状态同步给 driver 端的 BlockManagerMaster。
1
2
3
4
5
6
7
8
9
10
11
12
13def dropBlock[T](blockId: BlockId, entry: MemoryEntry[T]): Unit = {
val data = entry match {
case DeserializedMemoryEntry(values, _, _, _) => Left(values)
case SerializedMemoryEntry(buffer, _, _) => Right(buffer)
}
val newEffectiveStorageLevel =
blockEvictionHandler.dropFromMemory(blockId, () => data)(entry.classTag)
if (newEffectiveStorageLevel.isValid) {
blockInfoManager.unlock(blockId)
} else {
blockInfoManager.removeBlock(blockId)
}
}
到此,内存数据块就从 MemoryStore 中淘汰了,若对应 rdd 的存储级别包含了 useDisk,则数据可能被保存到磁盘上,否则数据就从内存中丢失了
 微信
微信 支付宝
支付宝