
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-Rule 体系
一、概述
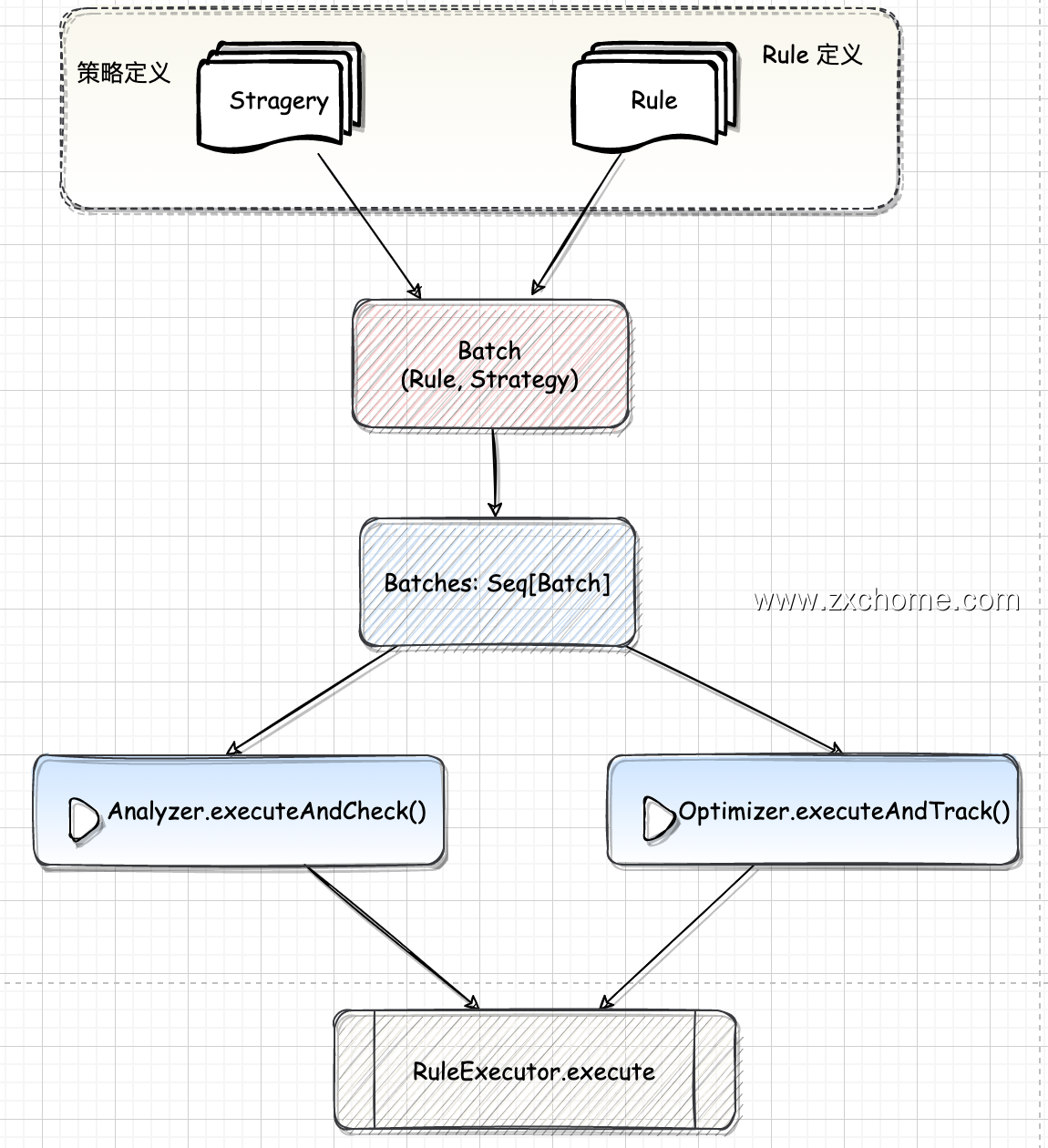
对逻辑算子树的操作(绑定,解析,优化等)主要都是基于规则的,通过 Scala 的语言模式匹配进行树结构转换或节点改写。由 RuleExecutor 来调用规则,所有涉及树形结构转换过程的都继承自RuleExecutor[TreeType] 抽象类。
Analyzer、Optimizer 定义了一系列 rule,而 RuleExecutor 定义了一个 rules 执行框架,即怎么把一批批规则应用在一个 plan 上得到一个新的 plan。Spark sql 通过 Analyzer 中定义的 rule 把 Parsed Logical Plan 解析成 Analyzed Logical Plan; 通过 Optimizer 定义的 rule 把 Analyzed Logical Plan 优化成 Optimized Logical Plan。
二、实现
RuleExecutor 内部提供一个 Seq[Batch] 定义了改 RuleExecutor 的处理步骤,每个 Batch 代表一套规则;$RuleExecutor.apply()$ 方法会按照 batches 和 batches 内 Rule 的顺序对传入的 plan 内的节点进行迭代处理。
2.1. Rule
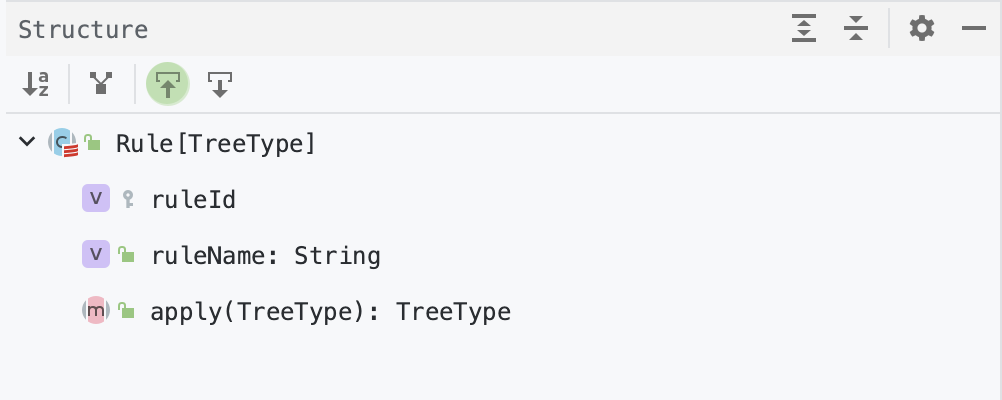
Rule 是一个抽象类,子类需要复写 $apply()$ 方法来制定特定的处理逻辑。
2.2. Batch
规则批(Batch)由规则名称、执行策略和规则列表组成。
1 | protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*) |
2.1.1. 执行策略
1 | abstract class Strategy { |
执行策略分为 2 种类型:fixedPoint 和 Once
FixedPoint
FixedPoint 代表运行到定点或最大迭代次数的策略
1
2
3case class FixedPoint(override val maxIterations: Int,
override val errorOnExceed: Boolean = false,
override val maxIterationsSetting: String = null) extends StrategyOnce
Once 代表是一种只运行一次且幂等的策略。
1
case object Once extends Strategy { val maxIterations = 1 }
2.3. RuleExecutor
有了各种具体规则后,还需要驱动程序来调用这些规则,在 Catalyst 中这个功能由 RuleExecutor 提供。凡是涉及树型结构的转换过程(如Analyzer 逻辑算子树分析过程、Optimizer 逻辑算子树的优化过程和后续物理算子树的生成过程等),都要实施规则匹配和节点处理,都继承自 RuleExecutor[TreeType] 抽象类。
2.3.1. execute()
$RuleExecutor.execute()$ 分批次 (batch) 执行一系列的优化规则直到稳定点(fixpoint)或最大迭代次数
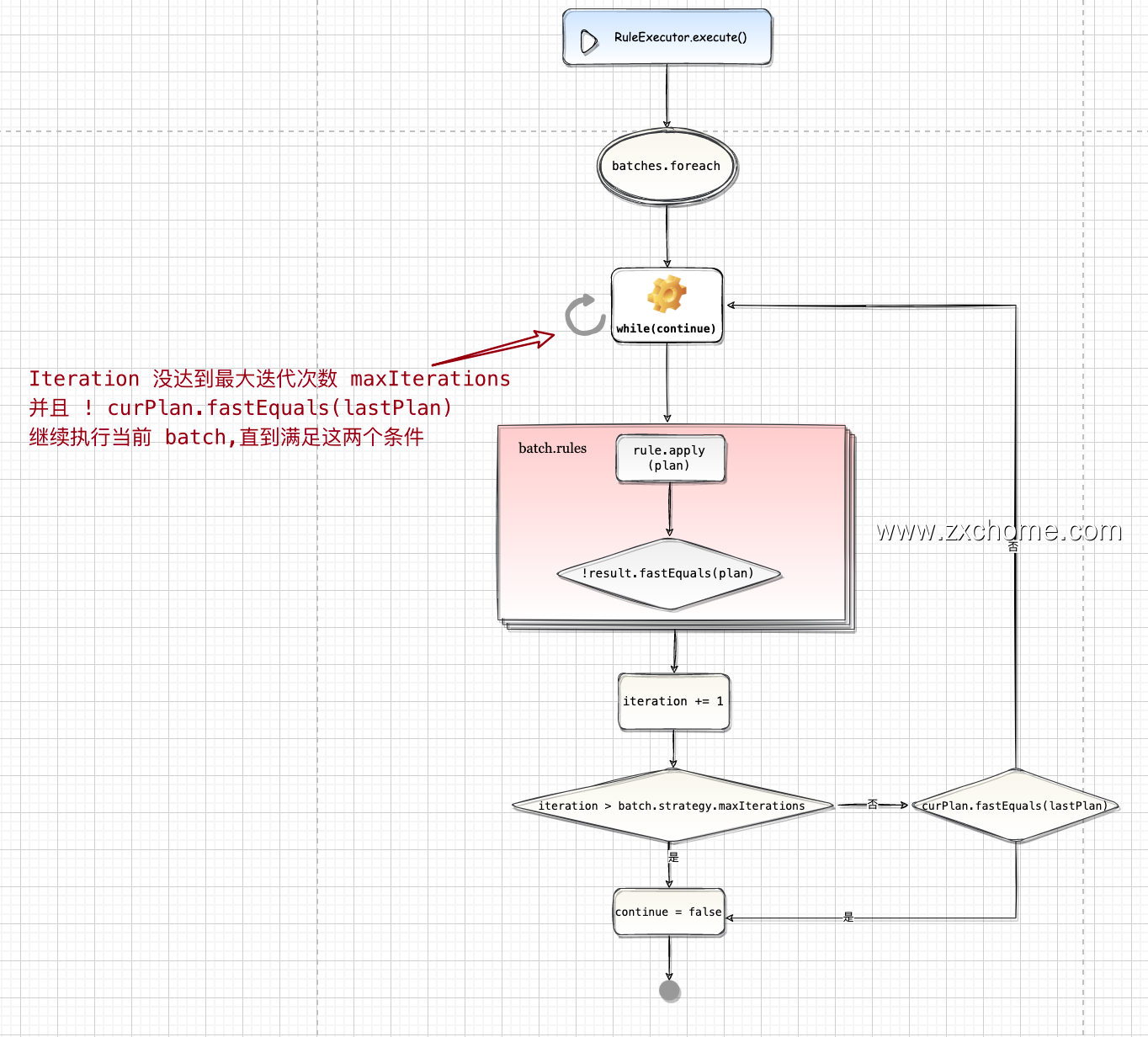
- 遍历 batches,取出 batch
- 针对每个 batch,调用其 $batch.rules.foldLeft(curPlan){…}$
- 对比执行规则前后,初始的 plan 有无变化
- 执行直到达到稳定点或者最大迭代次数,到达最大迭代次数, 不再执行优化,对最大迭代次数大于1的情况打 log
- plan 不变,到达稳定点后,不再执行优化
 微信
微信 支付宝
支付宝








