Spark-源码学习-通信服务-架构设计-路由层-Dispatcher
一、概述
Dispatcher 负责将 rpc 消息路由到对此消息进行处理的 RpcEndpoint 上。
二、实现
Dispatcher 实现在 Spark 2.x 和 Spark 3.x 有一些差别~
2.1. 结构

2.1.1. 属性
endpoints: ConcurrentMap[String, MessageLoop]
负责存储 endpoint name 和 MessageLoop 的映射关系
1
private val endpoints: ConcurrentMap[String, MessageLoop] = new ConcurrentHashMap[String, MessageLoop]
endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef]
负责存储 RpcEndpoint 和 RpcEndpointRef 的映射关系。
1
2private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] =
new ConcurrentHashMap[RpcEndpoint, RpcEndpointRef]receivers 是一个 LinkedBlockingQueue[EndpointData] 消息阻塞队列, 用于存放 EndpointData 对象。它主要用于追踪 那些可能会包含需要处理消息 receiver。在 $post()$ 消息到 Dispatcher 时, 一般会先 post 到 EndpointData 的 Inbox中,然后,再将 EndpointData 对象放入 receivers 中。Spark 3.x 中移除 Dispatcher 属性: receivers
三、注册 RpcEndpoint
实例化 RpcEndpoint 之后需要向 RpcEnv 注册该 RpcEndpoint,底层实现是向 NettyRpcEnv 进行注册,而实际上是通过调用 Dispatcher 的 $registerRpcEndpoint()$ 方法向 Dispatcher 进行注册。

具体的注册就是向 endpoints、endpointRefs 中插入记录,注册完成后返回 RpcEndpointRef,之后通过 RpcEndpointRef 就可以向其代表的 RpcEndpoint 发送消息。
endpointRefs
1
2
3
4val addr = RpcEndpointAddress(nettyEnv.address, name)
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
...
endpointRefs.put(endpoint, endpointRef)endpoints
初始化 MessageLoop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var messageLoop: MessageLoop = null
try {
messageLoop = endpoint match {
case e: IsolatedRpcEndpoint => new DedicatedMessageLoop(name, e, this)
case _ =>
sharedLoop.register(name, endpoint)
sharedLoop
}
endpoints.put(name, messageLoop)
} catch {
case NonFatal(e) =>
endpointRefs.remove(endpoint)
throw e
}
}
Spark 2.x: 注册向 endpoints、endpointRefs、receivers 中插入记录,而 receivers 中插入的信息会被 Dispatcher 中的线程池中的线程执行:会将记录 take 出来然后调用 Inbox 的 $process()$ 方法通过模式匹配的方法进行处理,注册的时候通过匹配到 OnStart 类型的 message,去执行 RpcEndpoint的 $onStart$ 方法(例如 Master、Worker 注册时,就要执行各自的 $onStart$ 方法),注册完成后返回 RpcEndpointRef,之后通过 RpcEndpointRef 就可以向其代表的 RpcEndpoint 发送消息。
四、消息路由
Dispatcher 调用 $postMessage()$ 方法进行消息路由,将消息提交给指定的 RpcEndpoint。$postMessage()$ 会向具体的 RpcEndpoint 发送消息,如果当前 Dispatcher 没有停止并且缓存 endpoints 中确实存在名为 endpointName 的 MessageLoop,那么将调用 MessageLoop 对应 Inbox 的 $post()$ 方法将消息加入 Inbox 的消息列表中。
1 | val loop = endpoints.get(endpointName) |
此外还需要将 inbox 推入 active, 以便 MessageLoop 处理此 Inbox 中的消息。

首先通过 endpointName 从 endpoints 中获得注册时的 EndpointData,如果不为空就执行 EndpointData 中 Inbox 的 post(message) 方法,向 Inbox 的 mesages 中插入一条 InboxMessage,同时向 receivers 中插入一条记录。
Spark 2.x 是往 receivers 阻塞队列中添加 EndpointData 对象,这些方法将发往本地的消息以及从远程 RpcEndpoint 接收到的消息都添加到 receivers 阻塞队列中,然后由上述启动的那些 MessageLoop 线程来消费这些消息。
Dispatcher 中还有一些方法间接使用了 Dispatcher 的 $postMessage()$ 方法除了 $postOneWayMessage()$ 方法, 其他需要回复的消息中都封装了 RpcCallContext。
RpcCallContext 是用于回调客户端的上下文, RpcCallContext 一共定义了三个接口:
- $reply()$ 用于向发送者回复信息。
- $sendFailure()$ 用于向发送者发送失败信息。
- $senderAddress()$ 用于获婆发送者的地址。
五、Dispatcher 停止
Dispatcher 的 $stop()$ 方法用来停上 Dispatcher
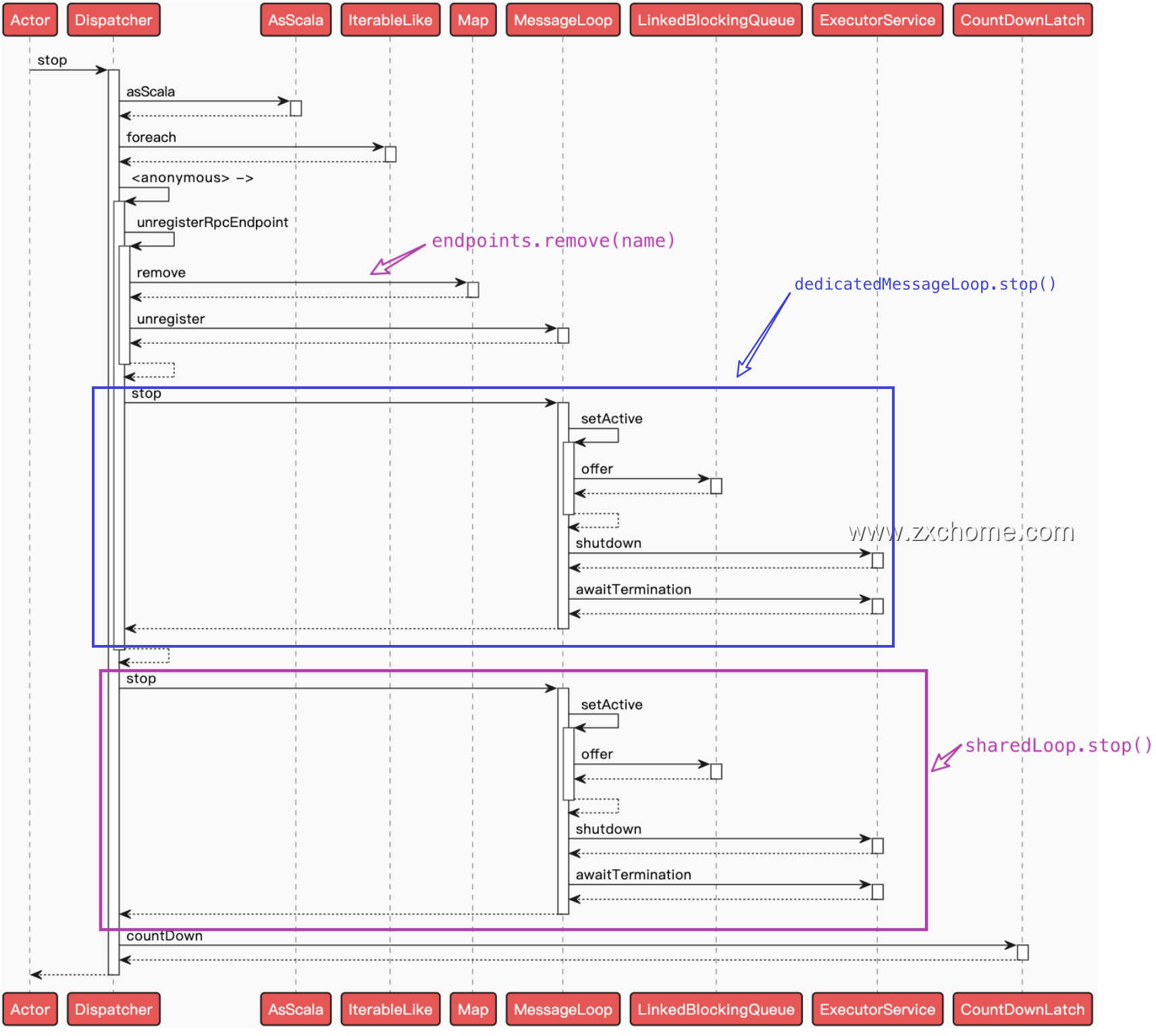
如果 Dispatcher 还未停止, 则将自身状态修改为已停止
调用 $unregisterRpcEndpoint()$ 方法,将向 endpoints 中的每个 Inbox 里放置
OnStop消息。1
2
3
4
5
6private def unregisterRpcEndpoint(name: String): Unit = {
val loop = endpoints.remove(name)
if (loop != null) {
loop.unregister(name)
}
}$DedicatedMessageLoop.unregister()$
投放 “毒药”
MessageLoop.PoisonPill,由于 Dispatcher 停止, 所以 Dispatcher 中的所有 DedicatedMessageLoop 线程没有存在的必要。1
2
3
4
5
6
7
8override def unregister(endpointName: String): Unit = synchronized {
require(endpointName == name)
inbox.stop()
// Mark active to handle the OnStop message.
setActive(inbox)
setActive(MessageLoop.PoisonPill)
threadpool.shutdown()
}$SharedMessageLoop.unregister()$

关闭 MessageLoop
关闭 threadpool 线程池。
 微信
微信 支付宝
支付宝