
Spark-源码学习-SparkSQL-Join 体系-逻辑计划生成
一、概述
逻辑计划阶段的开始由 AstBuilder 将抽象语法树 AST 生成 Unresolved LogicalPlan,然后在此基础上经过解析得到 Analyzed LogicalPlan,最后经过优化得到 Optimized LogicalPlan。
二、生成
2.1. 从 AST 到 Unresolved LogicalPlan
与 Join 算子相关的部分主要在 From 子句中,具体看,逻辑计划生成过程由 AstBuilder 类定义的 $visitFromClause()$ 方法开始,其核心代码如下:
从 FromClauseContext 中得到的 relation 是 RelationContext 的列表。根据前面的文法分析可知,每个 RelationContext 代表一个通过 Join 连接的数据表集合,每个 RelationContext 中有一个主要的数据表 RelationPrimaryContext 和多个需要 Join 连接的表 JoinRelationContext。
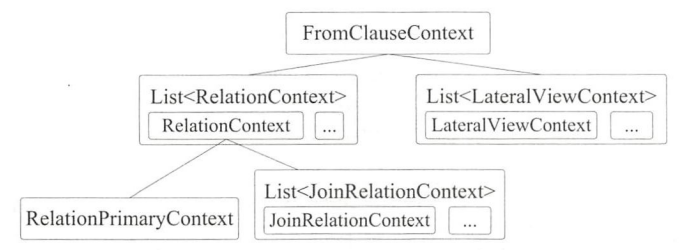
针对 RelationContext 对象列表进行 $foldLeft$ 操作,将已经生成的逻辑计划与新的 RelationContext 中的主要数据表(relationPrimary)结合得到 Join 算子 (optionalMap 方法),然后将生成的 Join 算子加入新的逻辑计划中。
对于本例来说,FromClauseContext 对应的 RelationContext 列表中只有一个元素,其 relationPrimary 为 student 数据表。由于初始的 LogicalPlan 为 nul,所以上述代码中的 join 值同样为 student 对应的 LogicalPlan。然后调用 $withJoinRelations()$ 方法,将得到的 LogicalPlan 与数据表 exam 进行 Join 操作。
在 $visitfromClauseContext$ 方法中生成 primaryRelation (student 表) 对应的 LogicalPlan 之后,进入 $withJoinRelation()$ 方法中对 JoinRelationContext 中的表进行处理,其实现逻辑如下。
$withjoinRelation()$ 方法首先会根据 SQL 语句中的 Join 类型构造基础的 JoinType 对象,然后在此基础上判断查询中是否包含了 USING 等关键字,并进行进一步的封装,最终得到一个 Join 对象的逻辑计划。对于案例中的 SQL 语句,最终生成的逻辑计划如图所示。

2.2. 从 Unresolve LogicalPlan 到 Analyzed LogicalPlan
在 Analyzer 中,与 Join 相关的解析规则有很多,包括 ResolveReferences 和 ResolveNaturalAndUsingJoin 等。
- ResolveRelations 规则负责从 Catalog 中找到 student 和 exam 的基本信息,包括数据表存储格式、每一列列名和数据类型等。
- ResolveReferences 规则负责解析所有列信息,对于上面的逻辑算子树,ResolveReferences 的解析是一个自底向上的过程,将所有 UnresolvedAttribute 与 UnresolvedExtractValue 类型的表达式转换成对应的列信息。
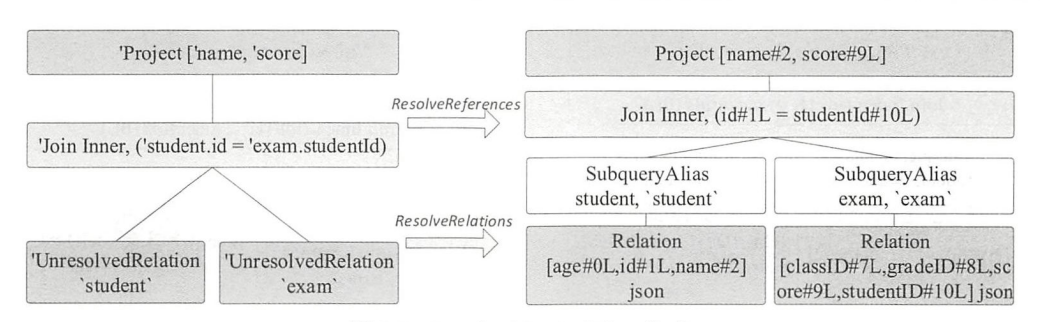
在 ResolveReferences 规则中,如果传入的逻辑算子树根节点为 Join 类型,则还存在如下的逻辑来处理 Join 中冲突的列。在 $dedupRight()$ 方法中,针对存在冲突的表达式会创建一个新的逻辑计划,通过增加别名(Alias)的方式来避免列属性的冲突。
根据该逻辑,如果 Join 操作存在重名的属性(左、右子节点的输出属性名集合有重叠),则调用 $dedupRight()$ 方法将右子节点对应的 Expression 用一个新的 Expression ID 表示,这样即使出现同名,经过处理之后 Expression ID 也不相同,因此可以区分 Join 操作中不同的数据表。
在 Analyzer 中,还有一个和 Join 操作直接相关的 ResolveNaturalAndUsingJoin 规则。该规则将 NATUAL 或 USING 类型的 Join 转换为普通的 Join。其主要处理逻辑是根据 Join 两边的输出列信息计算得到总的输出列信息,然后将 Project 算子添加到常规的 Join 算子上。
2.3. 从 Analyzed LogicalPlan 到 Optimized LogicalPlan
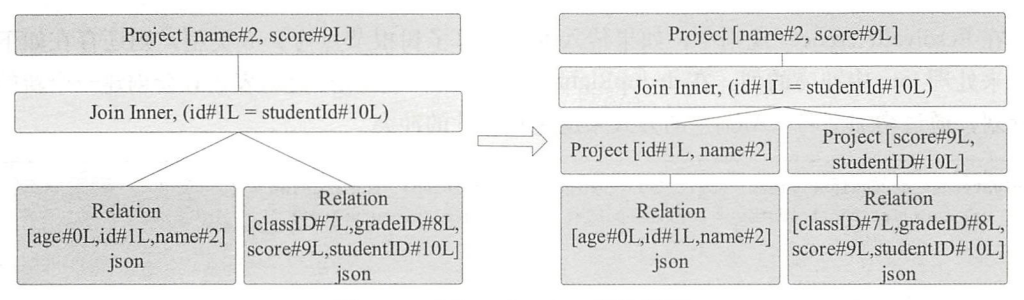
Analyzer 的解析得到上述逻辑算子树之后,开始进入逻辑算子树的优化阶段。逻辑算子树优化的第一阶段就是消除多余的别名,对应 EliminateSubqueryAliases 优化规则。将 SubqueryAlias(_, child,_)节点直接替换为 child 节点,起

可以看到,Relation 原来的 SubqueryAlias 父节点已经被移除,Join 成为 Relation 的父节点。经过别名消除之后,接下来的优化是常用的列剪裁ColumnPruning,在上述逻辑算子树中,父节点只需要用到两个数据表中的4列,因此可以在 Relation 节点之后添加新的 Project 节点进行列剪裁的操作,经过列剪裁优化后,得到新的逻辑算子树。
2.3.1. 相关优化规则
PushPredicateThroughJoin
在 Optimizer 阶段,有一条专门针对 Join 算子的 PushPredicateThroughJoin 优化规则,该优化规则所起的作用就是对 Join 中连接条件可以下推到子节点的谓词进行下推操作。
因为经过上一步的优化规则,逻辑算子树中 Join 节点多了两个条件用来判定列不为 null,这两个条件只涉及单个数据表,因此可以下推到对应的子节点中,这样可以达到尽早过滤数据的效果。经过 PushPredicateThroughJoin 优化规则后,得到的逻辑算子树如图所示。

InferFiltersFromConstraints
经过 PushPredicateThroughjoin 优化规则后,Join 中的两个连接条件生成了对应的两个 Filter 节点。一般来讲,优化阶段会将过滤条件尽可能地下推,因此逻辑算子树中的 Filter 节点还会被继续处理。该逻辑对应 PushDownPredicate 优化规则,得到的新的逻辑算子树如图所示,Filter 节点已经位于 Project 节点之下。

至此,整个逻辑算子树的优化工作完成。整个过程应用了5 条优化规则,对应了5次树型结构的操作转换。从上述转换过程来看,对于 Join 节点,密切相关的是 InferFiltersFromConstraints 和 PushPredicate ThroughJoin 两条优化规则。
PushDownPredicate
 微信
微信 支付宝
支付宝








