
Spark-源码学习-SparkSQL-Join 体系-物理计划-Join 选择
一、概述
在生成物理计划的过程中,JoinSelection 根据若干条件判断采用何种类型的 Join 执行方式。 目前在 Spark SQL 中, Join 的执行方式主要有 BroadcastHashJoinExec (BHJ)、 ShuffledHashJoinExec (SHJ)、SortMergeJoinExec (SMJ)、BroadcastNestedLoopJoinExec (BNLJ) 和 CartesianProductExec (CPJ) 这 5 种。
等值 Join
在等值数据关联中,Spark 会尝试按照 BHJ > SHJ > SMJ 的顺序依次选择 Join 策略
不等值 Join
不等值 Join 只能使用 NLJ 来实现,因此 Spark SQL 可选的 Join 策略只剩下 BNLJ 和 CPJ。在同一种计算模式下,相比 Shuffle,Broadcast 的网络开销更小。Spark SQL 会按照 BNLJ > CPJ 的顺序进行尝试。BNLJ 生效的前提自然是内表小到可以放进广播变量,否则 Spark SQL 用 CPJ 策略完成 Join 计算。
Join Hints
在满足前提条件的情况下,如等值条件、连接类型、表大小等等,Spark 会优先尊重开发者的意愿,去选取开发者通过 Join Hints 指定的 Join 策略。
Join 策略 Join Hints 适用场景 Broadcast Hash Join broadcast/broadcastjoin 内表较小,通常在 2GB 左右为宜,最大不能超过8GB Shuffle Merge Sort Join merge/mergejoin 等值 Join 下,Spark SQL 的兜底策略,不需要开发者特别设置 Shuffle Hash Join shuffle_hash 当大表超过小表 3 倍以上,且小表数据分布比较均匀,SHJ 比 SMJ 效率更佳 Broadcast Nested Loop Join 无 没有提供 Join Hints,开发者无能为力,只能靠 Spark SQL 自行判断 Cartesian Product Join shuffle_replicate_nl 不等值 Join 下,Spark SQL 的兜底策略,不需要开发者特别设置
二、实现
2.1. JoinSelection
2.1.1. 概述
JoinSelection 策略主要根据 Join 逻辑算子选择对应的物理算子。JoinSelection 策略中用到了 ExtractEquiJoinKeys 匹配模式来提取出 Join 算子中的连接条件。
ExtractEquiJoinKeys 模式的主要逻辑如下: 如果是等值连接(Equi-Join),则将左、右子节点的连接 key 都提取出来。 此时存在两种情况: EqualTo 和 EqualNullSafe。 两者的区别在于对空值(null)是否敏感。
- EqualTo 对空值没有额外的处理逻辑
- EqualNullSafe 在一般情况下的处理逻辑基本与 EqualTo 一样,但是它会对空值做处理,即赋予相应类型的默认值。
这两种情况实际上和用户编写的 SQL 语句有关,当 SQL 语句中 Join 条件表达式为 = 或 == 时, 会对应 EqualTo 模式;当 Join 条件表达式为 <=> 时, 会对应 EqualNullSafe 模式。 此外,在 ExtractEquiJoinKeys 中还通过 otherPredicates 记录除 EqualTo 和 EqualNullSafe 类型外的其他条件表达式, 这些谓词基本上可以在 Join 算子执行 Shuffle 操作之后 在各个数据集上分别处理。
2.1.2. 流程
等值连接
未使用 HINT
优先级最高的是 BroadcastHashJoinExec ,这种 Join 执行方式相对来讲效率最高,因此也是最先进行判断的,具体来讲,它包含两种情况:
- 能够广播右表 $canBroadcast$ 且右表能够 “构建” $canBuildRight$ ,那么构造参数中传入的是 BuildRight
- 能够广播左表 $canBroadcast$ 且左表能够 “构建” $canBuildLeft$,那么构造参数中传入的是 BuildLeft
优先级次之的是 ShuffledHashJoinExec,ShuffledHashJoinExec 执行方式需 要满足多种条件。
ShuffledHashJoinExec 的构造同样分为 BuildLeft 和 BuildRight 两种情况,以 BuildRight 为例:
- 配置中优先开启 SortMergeJoin 的参数 spark.sql.join.preferSortMerge 设置为 false
- 右表需要满足能够”构建” ($canBuildRight$) 和能够建立 HashMap ($canBuildLocalHashMap$)
- 右表的数据量要比左表的数据量小很多(3 倍以上)
此外,还有一种生成 ShuffledHashJoinExec 的情况是参与连接的 key 不具有排序的特性。
最常见的 Join 执行方式就是 SortMergeJoinExec,参与 Join 的 key 满足可排序的特性即可。
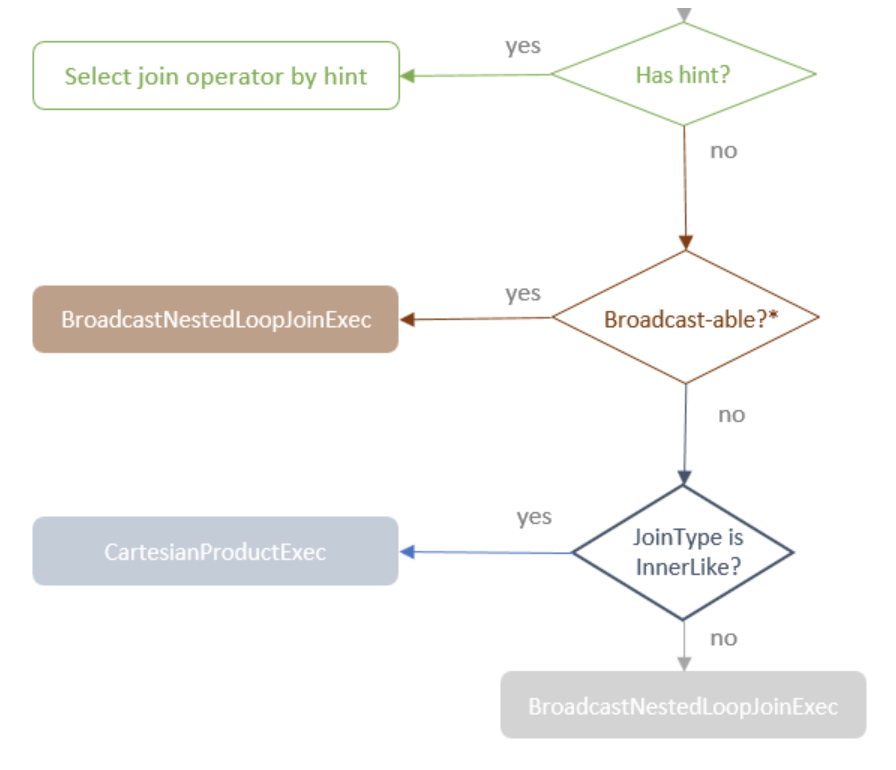
剩下的情况都是不包含 Join 条件的语句了,大致逻辑如下:首先判断是否执行数据表广播 操作,对应 BuildLeft 和 BuildRight 两种情况,生成 BroadcastNestedLoopJoinExec 类型的 Join 物理 算子 。 如果不满足数据表广播操作,而 Join 类型是 InnerLike ,那么就会生成 Car tesianProductExec 类型的 Join 物理算子 。 如果上述情况都不满足,那么只能选择两个数据表中数据量相对较少的 数据表来做广播,同样生成 BroadcastNestedLoop JoinExec 类型的 Join 物理算子 。
使用 HINT
非等值连接
2.2. DynamicJoinSelection
 微信
微信 支付宝
支付宝








