
Spark-源码学习-SparkSQL-Join 体系-物理计划-Join 生成
一、概述
相比单机环境,分布式环境中的数据关联在计算环节依然遵循着 NLJ、SMJ 和 HJ 这 3 种实现方式,只不过是增加了网络分发这一变数。在 Spark 的分布式计算环境中,数据在网络中的分发主要有两种方式,分别是 Shuffle 和 Broadcast。
2.1. Shuffle
采用 Shuffle 的分发方式来完成数据关联,那么外表和内表都需要按照 Join Key 在集群中做数据分发。因为只有这样,两个数据表中 Join Key 相同的数据记录才能分配到同一个 Executor 进程,从而完成关联计算
2.2. Broadcast
采用广播机制下,Spark 只需要把内表封装到广播变量,然后进行分发。由于广播变量中包含了内表的全量数据,因此体量较大的外表只要“待在原地、保持不动”,就能完成关联计算
结合 Shuffle、广播这两种网络分发方式和 NLJ、SMJ、HJ 这 3 种计算方式,对于分布式环境下的数据关联,就能组合出 6 种 Join 策略
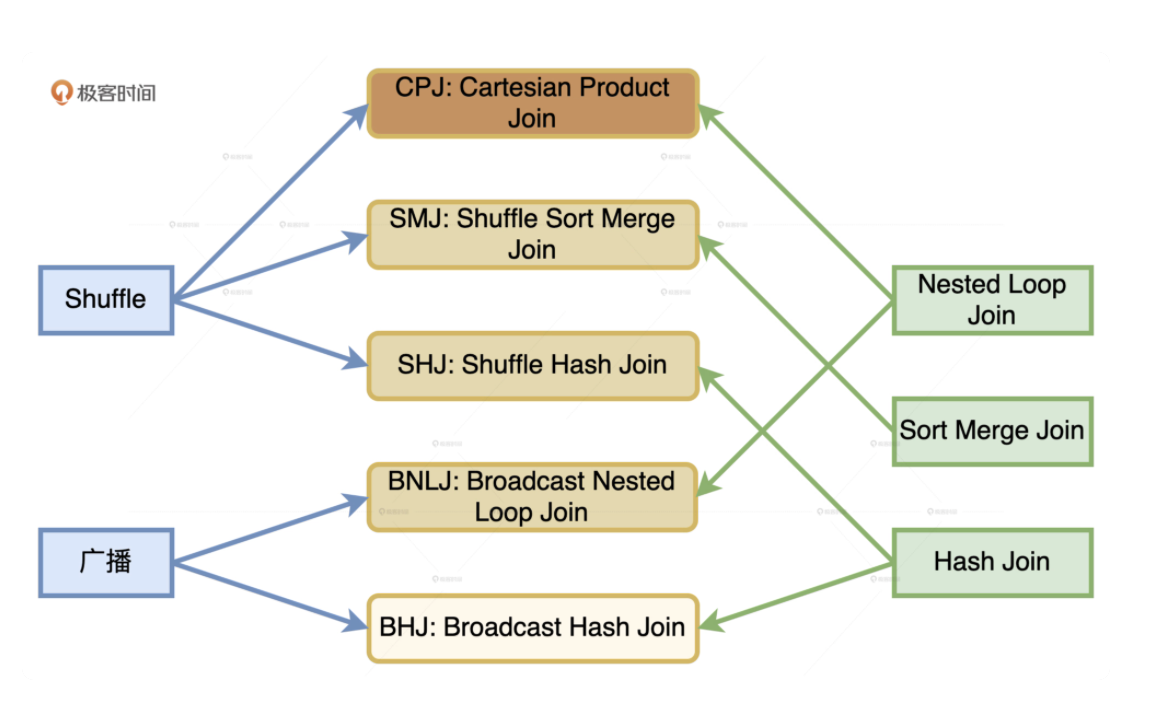
从执行性能来说,6 种策略从上到下由弱变强。相比之下,CPJ 的执行效率是所有实现方式当中最差的,网络开销、计算开销都很大。BHJ 是最好的分布式数据关联机制,网络开销和计算开销都是最小的。
二、实现
从逻辑计划到物理计划的生成是基于 Strategy 进行的,逻辑算子树将应用 3 个策略: 文件数据源(FileSource)策略、 Join 选择(JoinSelection)策略和基本算子( BasicOperators)策略。
结合 Shuffle、广播这两种网络分发方式和 NLJ、SMJ、HJ 这 3 种计算方式,对于分布式环境下的数据关联,就能组合出 6 种 Join 策略,从执行性能来说,6 种策略中,CPJ 的执行效率是所有实现方式当中最差的,网络开销、计算开销都很大。BHJ 是最好的分布式数据关联机制,网络开销和计算开销都是最小的。
此外 Spark 并没有选择支持 Broadcast + Sort Merge Join 这种组合方式。
当数据能以广播的形式在网络中进行分发时,说明被分发的数据,也就是基表的数据足够小,完全可以放到内存中去。这个时候,相比 NLJ、SMJ,HJ 的执行效率是最高的。因此,在可以采用 HJ 的情况下,Spark 自然就没有必要再去用 SMJ 这种前置开销比较大的方式去完成数据关联。

2.1. ShuffledJoin

2.1.1. ShuffledHashJoinExec
Spark SQL 优先级次之的是 ShuffledHashJoinExec,ShuffledHashJoinExec 执行需要满足多种条件。 ShuffledHashJoinExec 的构造同样分为 BuildLeft 和 BuildRight 两种情况,以 BuildRight 为例:
- 配置中优先开启 SortMergeJoin 的参数 spark.sql.join.preferSortMerge 设置为 false
- 右表需要满足能够”构建” ($canBuildRight$) 和能够建立 HashMap ($canBuildLocalHashMap$)
- 右表的数据量要比左表的数据量小很多(3 倍以上)
此外,还有一种生成 ShuffledHashJoinExec 的情况是参与连接的 key 不具有排序的特性。
2.1.2. SortMergeJoinExec
SMJ 的思路是先排序、再归并,参与 Join 的两张表先分别按照 Join Key 做升序排序。然后,SMJ 会使用两个独立的游标对排好序的两张表完成归并关联。
2.1.3. CartesianProductExec
如果选择 Shuffle SortMergeJoin 策略的条件没有得到满足,并且连接的 JoinType 是 InnerLike,流程则会选择 Cartesian Product Join。通常发生在没有定义连接条件的连接查询中。笛卡尔乘积连接的核心思想是计算两个连接数据集的乘积。因此可以想象,对于大型数据集,笛卡尔乘积连接的性能可能会非常糟糕,因此应该尽量避免这种类型的连接。
2.2. BroadcastJoin
2.2.1. BroadcastHashJoinExec
BroadcastJoinExec 实现的主要思想是对小表进行广播操作,避免大量 Shuffle 的产生。这也是一种常见的思路,在 Spark SQL 中,对两个表做 Join 操作最直接的方式是先根据 key 分区,然后在每个分区中把 key 值相同的记录提取出来进行连接操作。这种方式不可避免地涉及数据的 Shuffle,而 Shufle 是比较耗时的操作。因此,当一个大表和一个小表进行 Join 操作时,为了避免数据的 Shufle,可以将小表的全部数据分发到每个节点上,供大表直接使用。
2.2.2. BroadcastNestedLoopJoinExec
当以上四种连接策略的条件都不满足时,流程会选择 BroadcastNestedLoopJoin 策略。这个策略的连接过程涉及到 StreamTable 和 BuildTable 的嵌套循环。Broadcast nested loop join 支持等值和不等值 Join,支持所有的 Join 类型。

 微信
微信 支付宝
支付宝








