
Spark-源码学习-架构设计-DataSource 体系-FileFormat-ORC
一、概述
https://blog.csdn.net/onway_goahead/article/details/111186675
二、OrcFileFormat
2.1. supportBatch()
$supportBatch()$ 方法用来判断是否支持向量读取
1 | override def supportBatch(sparkSession: SparkSession, schema: StructType): Boolean = { |
需要满足以下条件:
开启 spark.sql.orc.enableVectorizedReader: 默认 true;
[关键]所有列数据类型需要为 AtomicType 类型的
1
2
3
4
5
6
7
8
9
10
11def supportColumnarReads(dataType: DataType, nestedColumnEnabled: Boolean): Boolean = {
dataType match {
case _: AtomicType => true
case st: StructType if nestedColumnEnabled =>
st.forall(f => supportColumnarReads(f.dataType, nestedColumnEnabled))
case ArrayType(elementType, _) if nestedColumnEnabled => supportColumnarReads(elementType, nestedColumnEnabled)
case MapType(keyType, valueType, _) if nestedColumnEnabled =>
supportColumnarReads(keyType, nestedColumnEnabled) && supportColumnarReads(valueType, nestedColumnEnabled)
case _ => false
}
}
2.2. 构建分区 reader
2.3. 类型推断 inferSchema
三、数据结构
3.1. ColumnarBatch
3.2. OrcColumnVector

三、Spark ORC 文件读取
https://blog.csdn.net/crispy_rice/article/details/79452007
https://blog.csdn.net/qq_27882063/article/details/80983476
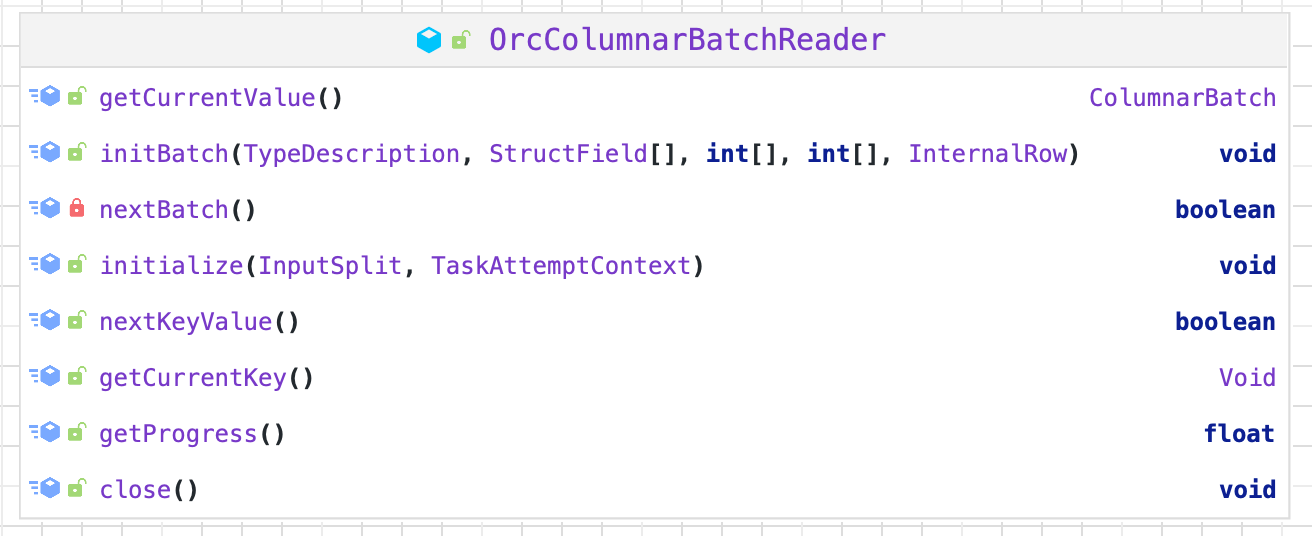
3.1. OrcColumnarBatchReader
读取一个 file 的数据时,OrcFileFormat (orc的读写入口) 会先初始化一个默认 orcReader 用来做 schema 验证,初始化 Vector 等操作,然后调用 OrcColumnarBatchReader 的 $initialize()$ ,$initBatch()$ ,$nextBatch()$ 等方法进行数据读取。
$initialize()$ 初始化 OrcFileReader 及 Hadoop 环境配置,会初始化一个带有 start,end,sarg 等条件的 orcReader
$initBatch()$ 初始化batch变量和columnarBatch变量(其中batch为ORC Reader矢量化每次读取的结果存储变量,columnarBatch为codegen转换为Spark定义类型存储变量
读取时会根据copyTospark参数判断是复制还是引用orc Vector。
$nextBatch()$ 迭代器,其核心还是调用ORC自定义的vectored函数,需要根据类型转换Spark定义type;
四、Spark ORC 文件写入
五、总结
 微信
微信 支付宝
支付宝








