
Flink-源码学习-FlinkSQL&Table-Planner 设计
一、概述
从 Flink 1.9 开始,Flink 提供了两种不同的 Planner 实现来执行 Table & SQL API 程序:
- Blink Planner:Flink 1.9+
- Old Planner:Flink 1.9 之前
在 1.14 新版本中,Old Planner 被移除,Blink Planner 将成为 Planner 的唯一实现
https://mp.weixin.qq.com/s/KaRjvtfLHJRqfmf1790chQ
二、Planner
二、流程
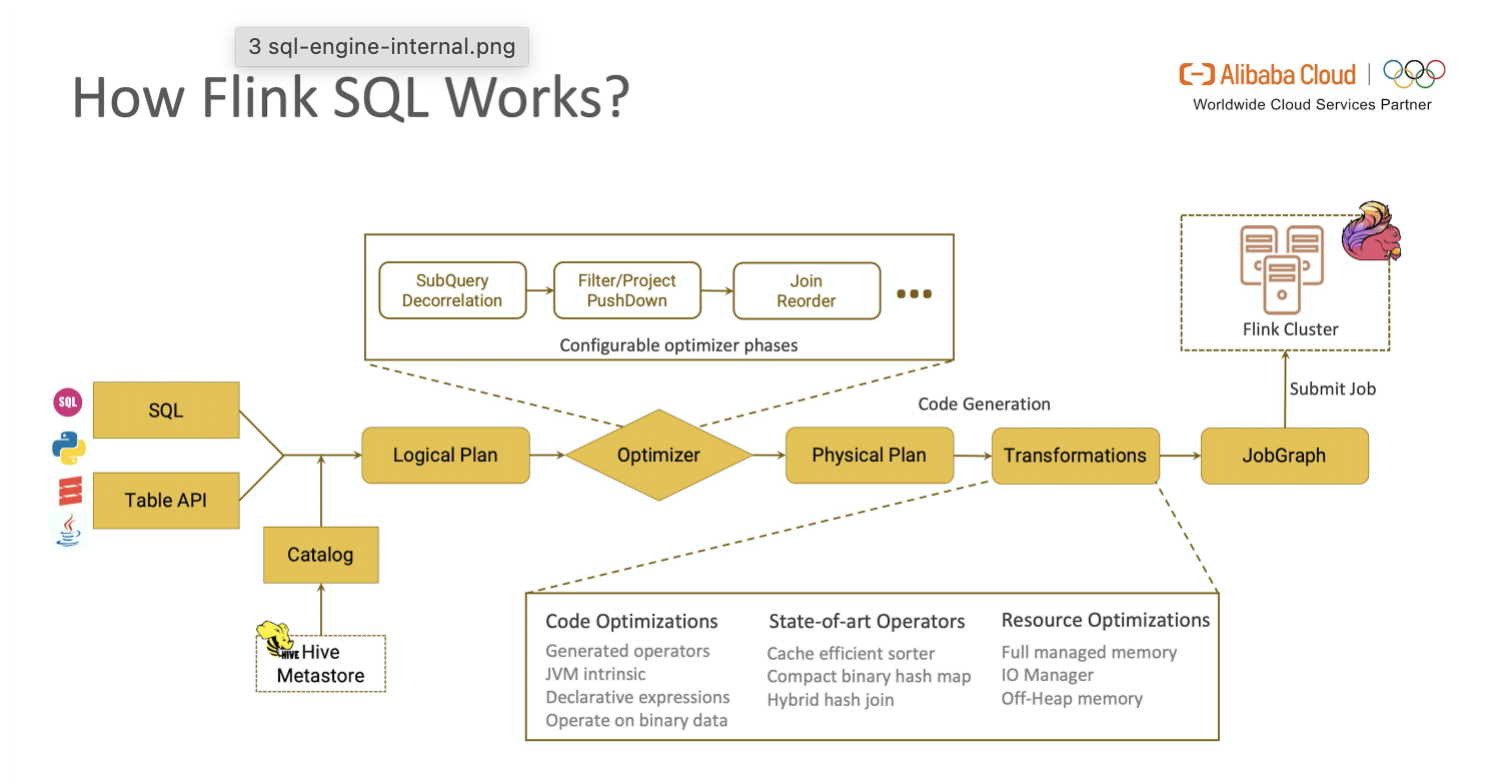
一段查询 SQL / 使用TableAPI 编写的程序从输入到编译为可执行的 JobGraph 主要经历如下几个阶段
- 将 SQL文本 / TableAPI 代码转化为逻辑执行计划(Logical Plan)
- Logical Plan 通过优化器优化为物理执行计划(Physical Plan)
- 通过代码生成技术生成 Transformations 后进一步编译为可执行的 JobGraph 提交运行
SQL语句经过Calcite解析生成抽象语法树SQLNode,基于生成的SQLNode并结合flink Catalog完成校验生成一颗Operation树,接下来blink planner将Operation树,接下来blink planner将Opearation树转为RelNode然后进行优化,最后生成Transformation变成流计算任务。
https://blog.csdn.net/Yuan_CSDF/article/details/123397988
https://developer.aliyun.com/article/765311#slide-7
2.1. 逻辑计划
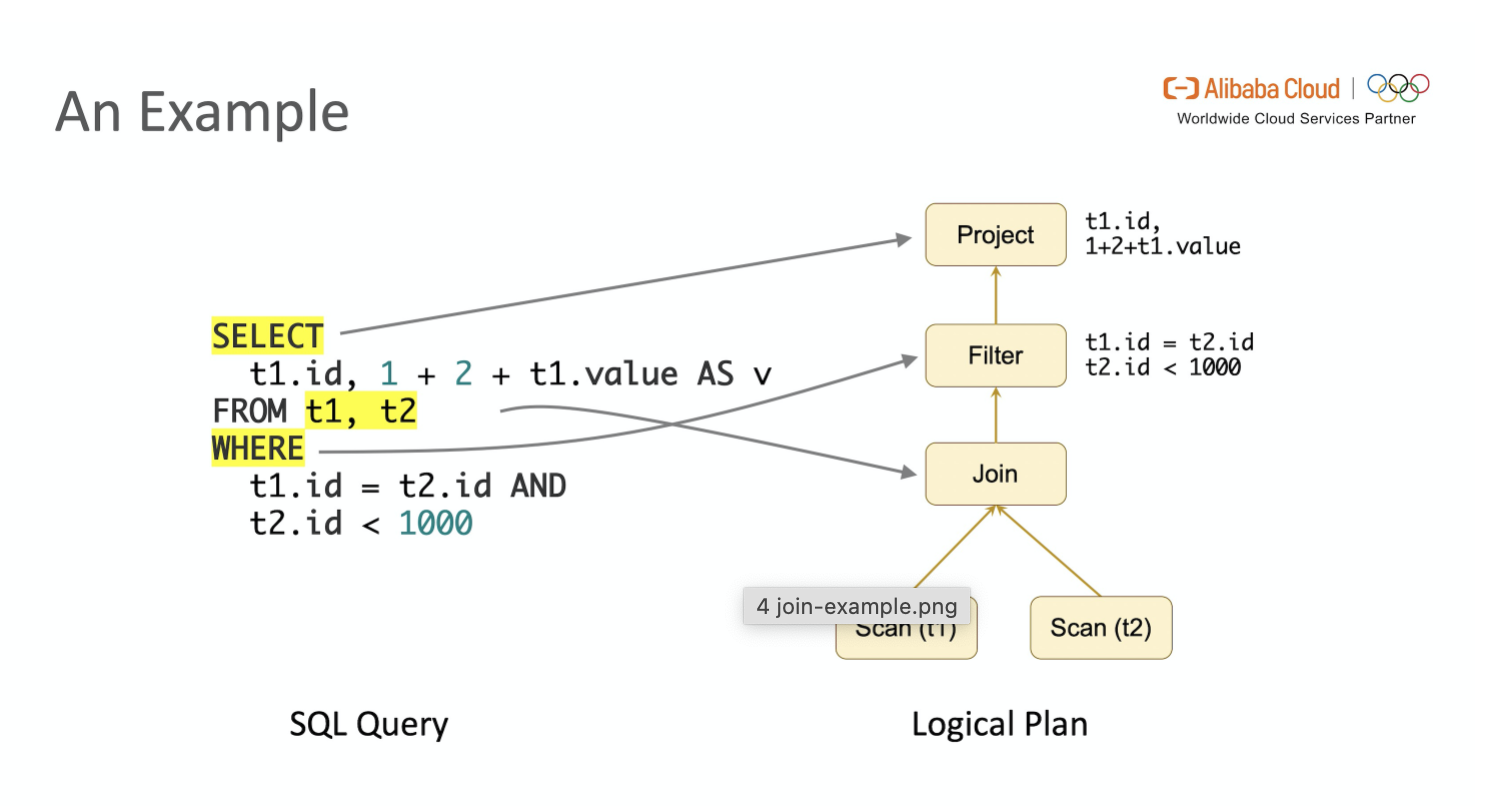
Flink SQL 引擎使用 Apache Calcite SQL Parser 将 SQL 文本解析为词法树,SQLValidator 获取 Catalog 中元数据的信息进行语法分析和验证,转化为关系代数表达式(RelNode),再由 Optimizer 将关系代数表达式转换为初始状态的逻辑执行计划。
和 SparkSQL 类似
Flink 中的 sql 解析、sql 校验和 sql 优化便是依赖 Calcite 来完成的。
Apache Calcite 是一个动态数据管理框架 ,它具备很多典型数据库管理系统的功能,如SQL解析、SQL校验、SQL查询优化等,又省略了一些功能,如不存储相关数据,也不完全包含相关处理数据等。
2.1.1. SQL 文本解析为词法树
调用 parser 方法,将 SQL 转为未经校验的 AST 抽象语法树,也就是 SqlNode,它主要会用到词法解析和语法解析。词法解析就是将Sql语句转为一组token,而语法解析就是将 token 进行递归下降词法分析。
Flink 中 Calcite 通过 JavaCC 生成分析器用于 sql 解析和校验。
Spark 使用 Antlr
2.1.2. RelNode
SQL Validator 获取 Catalog 中元数据的信息进行语法分析和验证,转化为关系代数表达式(RelNode)
将未经校验的抽象语法树校验成已经校验的抽象语法树,在校验阶段主要校验两部分:
- 校验表名,字段名,函数名是否正确
- 校验特殊的类型是否正确,如
join操作,groupby是否有嵌套等
调用rel()方法:将抽象语法树SqlNode转为关系代数树RelNode(关系代数表达式)和RexNode行表达式,在这个过程中,DDL它是不执行rel()方法的,因为DDL实际是对元素区的修改,不涉及复杂查询
调用 $convert()$ 方法将 RelNode 转化为 operation,operation 它包括多种类型,但最终都会生成根节点 modify operation
2.1.3. Optimizer
2.2. 物理计划
2.3. Translation & Code Generation
代码生成(Code Generation)在计算机领域是一种广泛使用的技术。在 Physical Plan 到生成 Transformation Tree 过程中就使用了 Code Generation。
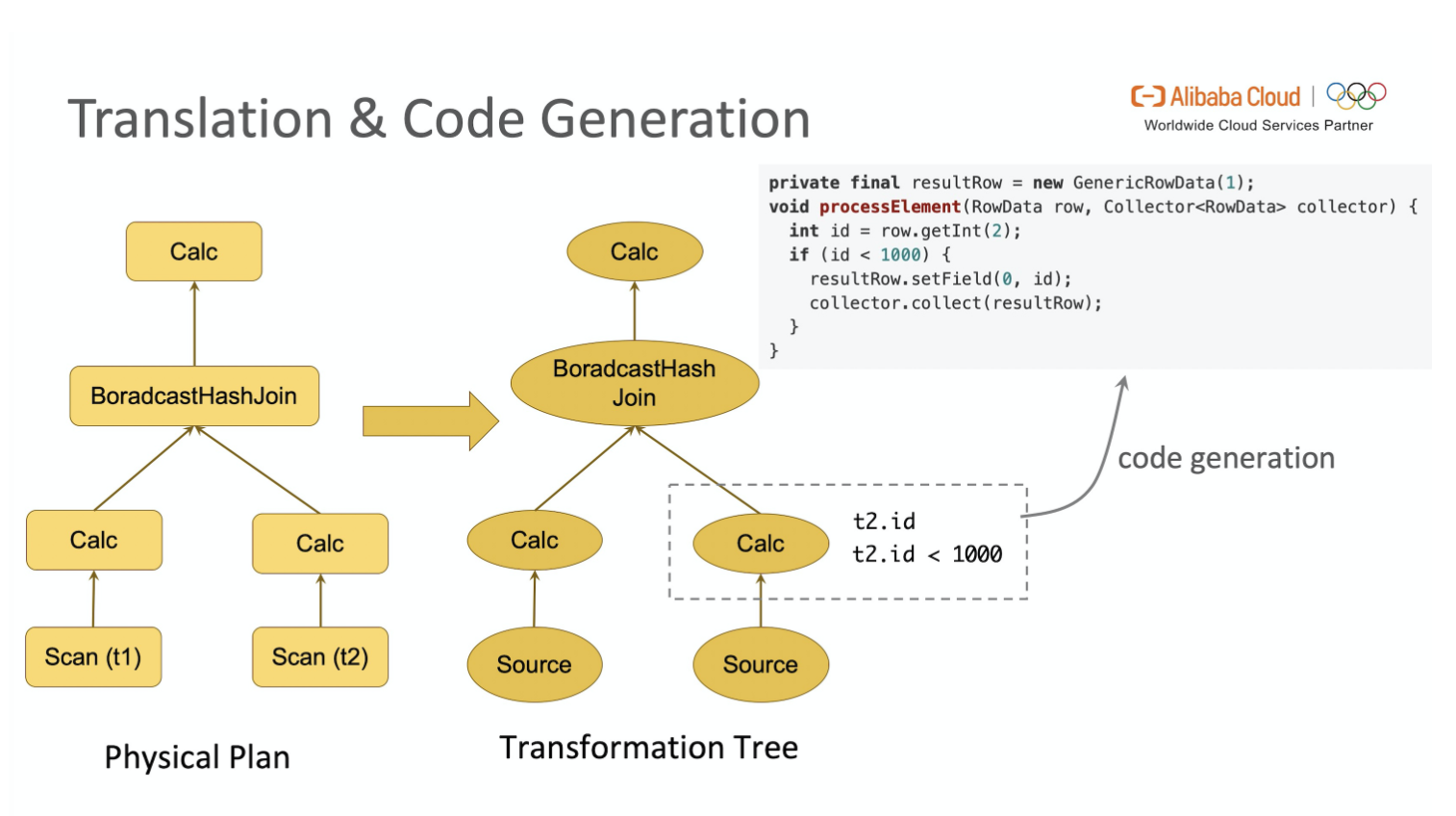
Flink SQL 引擎会将 Physical Plan 通过 Code Generation 翻译为 Transformations,再进一步编译为可执行的 JobGraph。
https://blog.csdn.net/weixin_44052055/article/details/126035846
 微信
微信 支付宝
支付宝






