Spark-源码学习-SparkCore-调度机制-资源调度-Standalone-启动 Driver
一、概述
Driver 端是 Spark 程序入口, 是运行 main 函数的一端,并且负责创建 SparkContext, 初始化 SparkContext 是为了准备 Spark 程序的运行环境,Spark 中由 SparkContext 负责与集群进行通信、资源申请,以及任务的分配与监控等。
二、实现
Master 接受到 RequestSubmitDriver 请求之后创建 DriverInfo 对象并将该对象放到一个 HashSet 对象中,然后开始调度 Driver 的启动
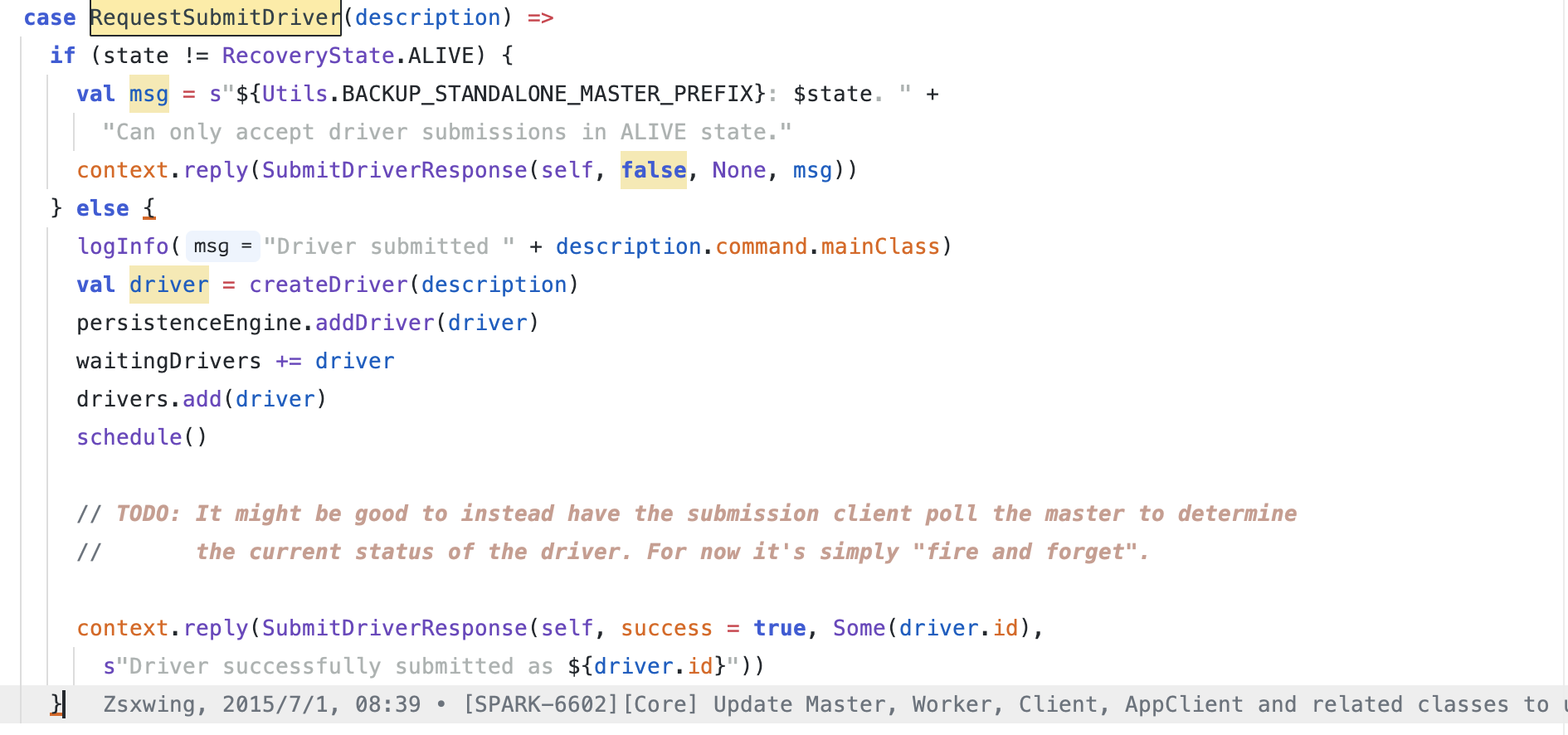
2.1. 构建 DriverInfo
构建 DriverInfo, 保存后续 Driver 启动所需的信息
1 | private def createDriver(desc: DriverDescription): DriverInfo = { |
2.2. 持久化 Driver 信息
1 | final def addDriver(driver: DriverInfo): Unit = { |
2.3. driver 加入 waiting list
driver 加入到 waiting list,方便后续有 worker 资源了再去创建
1 | waitingDrivers += driver |
drivers.add(driver)
执行
schedule()把 Driver 信息准备好之后,最后来到
schedule()方法,该方法中,会把所有的 waitingDrivers 等待被分配的 driver 一一 分配出去,分配到 alive 的 worker 中。打散 worker
启动 driver
来看 launchDriver(), 又是一个远程调用~
1
2
3
4
5
6private def launchDriver(worker: WorkerInfo, driver: DriverInfo): Unit = {
worker.addDriver(driver)
driver.worker = Some(worker)
worker.endpoint.send(LaunchDriver(driver.id, driver.desc, driver.resources))
driver.state = DriverState.RUNNING
}调用了 worker endpoint 的
send方法, 往 Worker 发消息~, 来到 Worker~
运行 command
1
process = Some(command.start())
阻塞等待
1
exitCode = process.get.waitFor()
回复消息
1
2context.reply(SubmitDriverResponse(self, success = true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
Master遍历waitingDrivers中等待调度的driver, 针对每个driver随机从集群中获取一个状态正常的worker,如果worker的资源足够启动driver,则将driver调度到这个worker节点上,并调整waitingDrivers:
Master通过向worker发送LaunchDriver指令来启动driver,在standalone模式下是在worker中启动了一个driver线程,然后对该worker的资源使用量进行调整:
 微信
微信 支付宝
支付宝