Flink-源码学习-Job 提交-Graph 演变-ExecutionGraph 构建
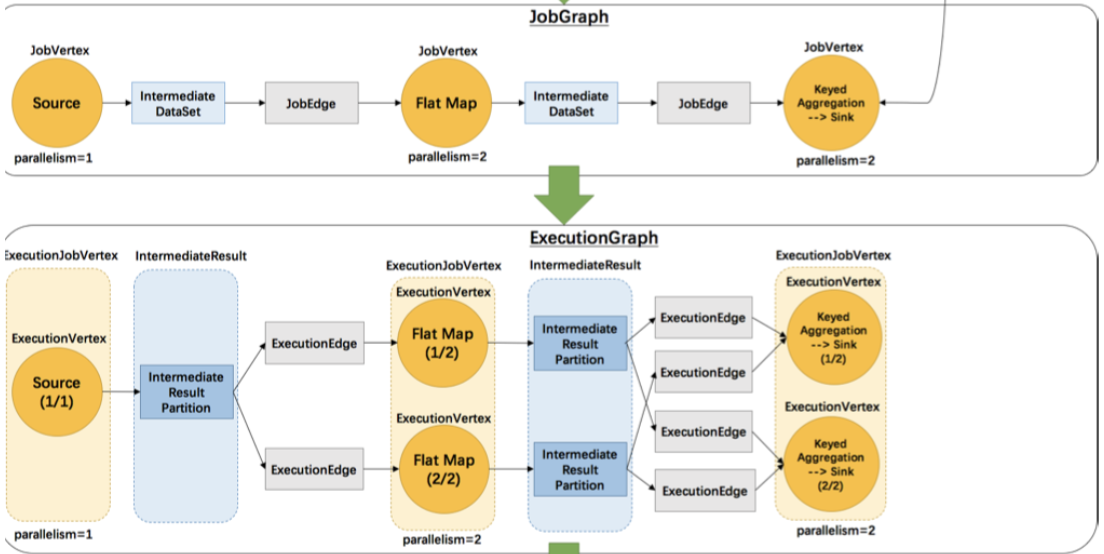
JobManager 根据 JobGragh 生成 ExecutionGragh, ExecutionGragh 是 JobGragh 的并行化版本,是调度层最核心的数据结构。来到 ExecutionGraph 构建源码分析~,有点难~~~
一、概述
JobManager 根据 JobGragh 生成ExecutionGragh, ExecutionGragh是JobGragh的并行化版本,是调度层最核心的数据结构,每个 ExecutionGraph 都有一个与其相关联的作业状态。此作业状态指示作业执行的当前状态
ExecutionJobVertex
和 JobGraph 中的 JobVertex一一对应。每一个 ExecutionJobVertex 都有和并发度一样多的 ExecutionVertex。
ExecutionVertex
表示 ExecutionJobVertex 的其中一个并发子任务,输入是ExecutionEdge,输出是 IntermediateResultPartition。
IntermediateResult
和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个 IntermediateResultPartition,其个数等于该operator的并发度。
IntermediateResultPartition
表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
ExecutionEdge
表示 ExecutionVertex 的输入,source 是 IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
Execution
是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过ExecutionAttemptID 来确定消息接受者。
二、源码
2.1. 接收 JobGraph
从客户端将 JobGraph 对象提交到集群运行时后,集群通过Dispatcher组件接收提交的 JobGraph对象。Dispatcher组件通过JobManagerRunnerFactory创建
在 Flink-源码-集群启动(1)-JobManager启动.md 里我们说过,WebMonitorEndpoint 用来接收客户端提交的各种 restful 请求,在客户端通过 Flink 脚本提交了各种请求或者在 Flink UI中发出一个人请求,最终这些请求都会被 WebMonitorEndpoint 接收,WebMonitorEndpoint 内部初始化了各种 handler,针对不同请求调用不同 handler 进行处理WebMonitorEndpoint请求
将来自客户端提交应用程序上来,由 JobManager 中的 Netty 服务端的 JobSubmitHandler 来执行处理,所以我们来到 JobSubmitHandler#handleRequest() ~~~
2.1.1. 获取文件
从请求中获取文件,包含 JobGraph 序列化文件
1 | final Collection<File> uploadedFiles = request.getUploadedFiles(); |
2.1.2. 获取请求体
1 | final JobSubmitRequestBody requestBody = request.getRequestBody(); |
2.1.3. 反序列化得到 JobGraph
服务端接收到客户端提交的,其实就是一个 JobGraph,到这儿客户端终于把 JobGraph 提交给 JobManager 了。 最终由 JobSubmitHandler 来执行处理~~~
1 | CompletableFuture<JobGraph> jobGraphFuture = loadJobGraph(requestBody, nameToFile); |
- 获取 JobGraph 的序列化文件的存储位置
- 从 JobGraphFile 文件中,反序列化得到 JobGraph 对象
2.1.4. 获取 jar
1 | Collection<Path> jarFiles = getJarFilesToUpload(requestBody.jarFileNames, nameToFile); |
2.1.5. 获取依赖 jar
1 | Collection<Tuple2<String, Path>> artifacts = |
2.1.6. 上传 JobGraph + 程序jar + 依赖 jar
通过 BlobClient 来上传 jar 资源和依赖 jar 和 jobGraph
1 | CompletableFuture<JobGraph> finalizedJobGraphFuture = uploadJobGraphFiles(gateway, jobGraphFuture, |
2.1.7. 提交任务至 Dispatcher
1 | CompletableFuture<Acknowledge> jobSubmissionFuture = finalizedJobGraphFuture.thenCompose( |
注:这儿的 gateway (DispatcherGateway) 可以认为就是 Dispatcher 哦~
2.2. Dispatcher ExecutionGraph 构建

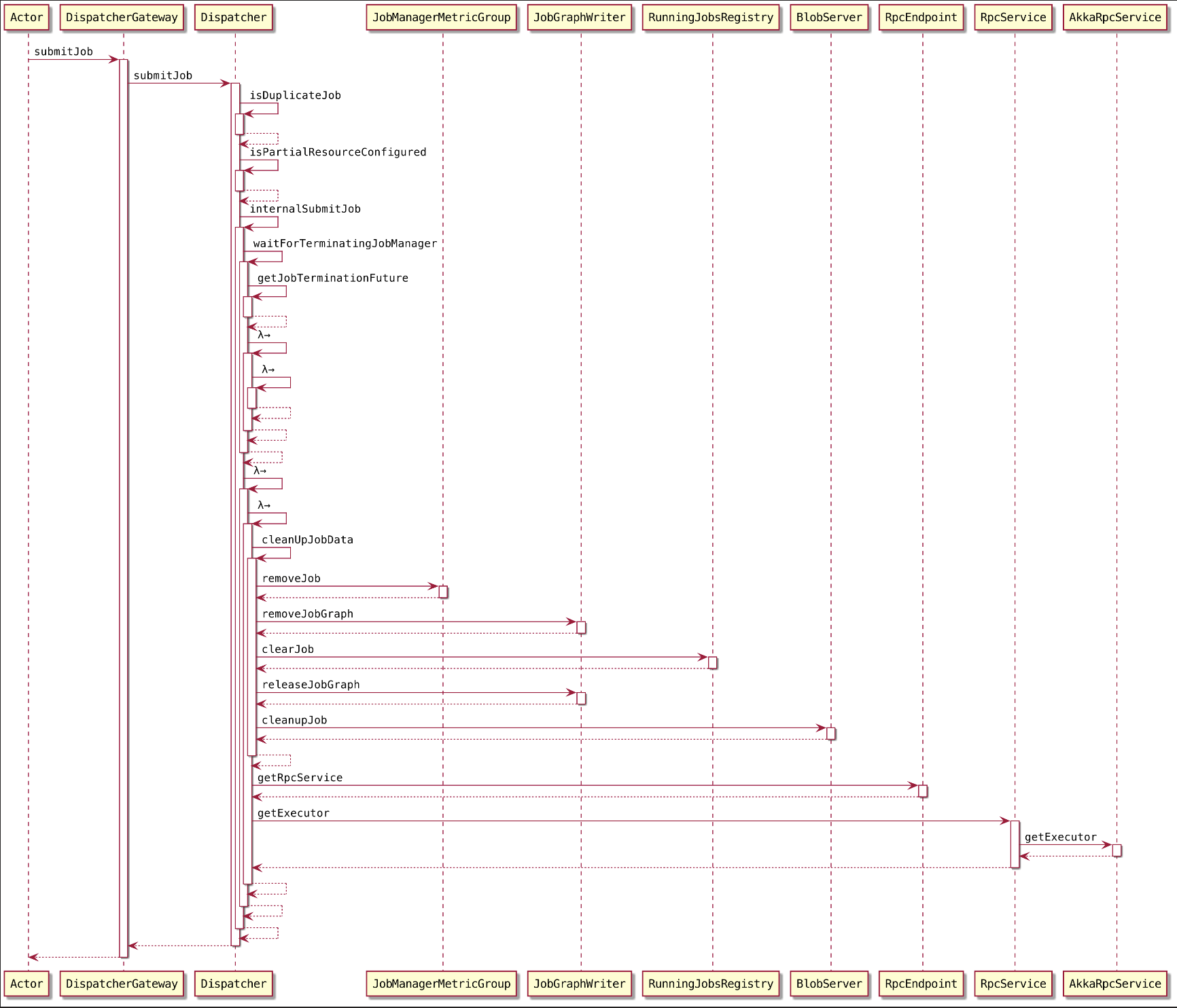
2.2.1. 判断提交的 JobGraph 中 JobID 是否重复
2.2.2. 判断 JobGraph 中是否仅为部分节点配置了资源
JobGraph的节点不支持部分资源配置,因此要么全部节点都配置资源,要么全不配置,否则会抛出异常
2.2.3. internalSubmitJob(jobGraph)
点点点~~~来到 waitForTerminatingJobManager()~~~,主要负责将 JobGraph 异步提交给 Dispatcher~
persistAndRunJob(JobGraph jobGraph)persistAndRunJob()方法主要涉及 JobGraph 的持久化及执行操作保存 JobGraph
调用 jobGraphWriter.putJobGraph() 方法对 JobGraph 进行持久化,如果基于 ZooKeeper 实现了集群高可用,则将 JobGraph 记录到 ZooKeeperJobGraphStore 中,异常情况下会通过ZooKeeperJobGraphStore恢复作业。
1
jobGraphWriter.putJobGraph(jobGraph);
运行 job
执行 jobGraph,然后返回 CompletableFuturerunJobFuture 对象。
1
final CompletableFuture<Void> runJobFuture = runJob(jobGraph);
点进来~~~
- 创建
JobManagerRunner - 防止 Job 重复执行
startJobManagerRunner
首先让我们来看看~创建
JobManagerRunner~1
2final CompletableFuture<JobManagerRunner> jobManagerRunnerFuture =
createJobManagerRunner(jobGraph);这儿 JobManagerRunner指的是 JobMaster ~🤔️
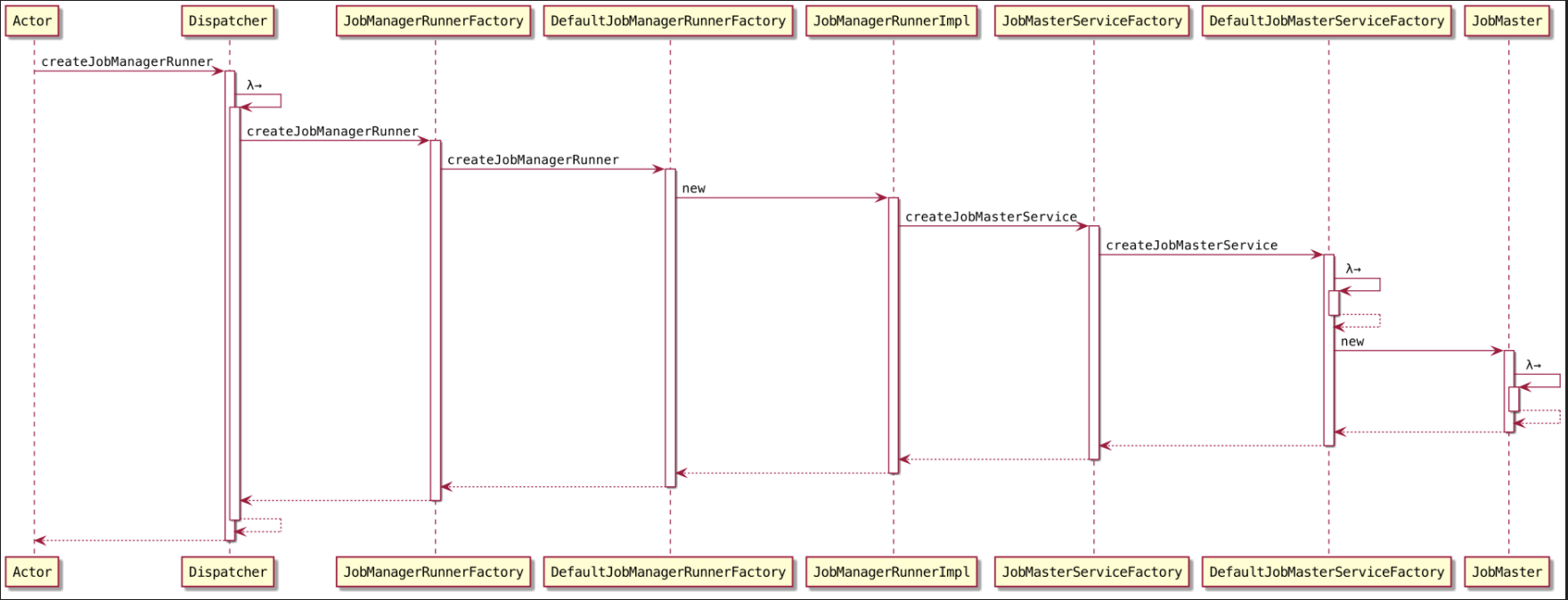
点点点~来到
DefaultJobMasterServiceFactory#createJobMasterService()~
在 JobMaster 初始化过程中 会将 JobGraph转为ExecutionGraph~~~
同时JobMaster 实现了
RpcEndpoint接口,所以在实例化之后会自动调用JobMaster#onStart(),可是在JobMaster和FencedRpcEndpoint都没有实现onStart()方法~~~,不用看啦~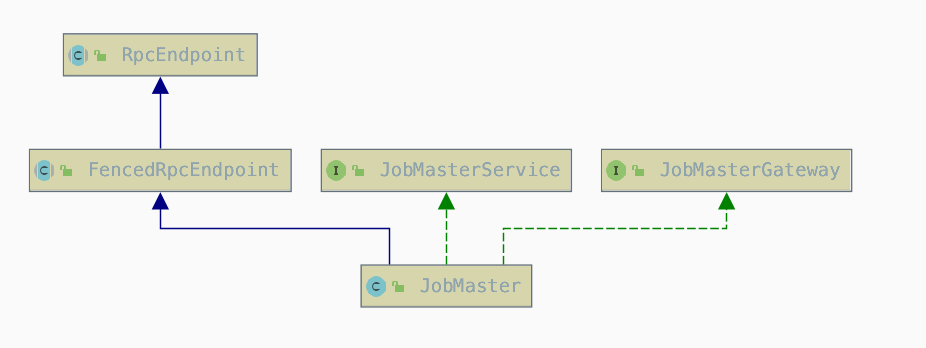
- 创建
2.3. ExecutionGraph 构建
在 JobMaster 初始化过程中,SchedulerBase#createAndRestoreExecutionGraph()会将 JobGraph转为ExecutionGraph~~~
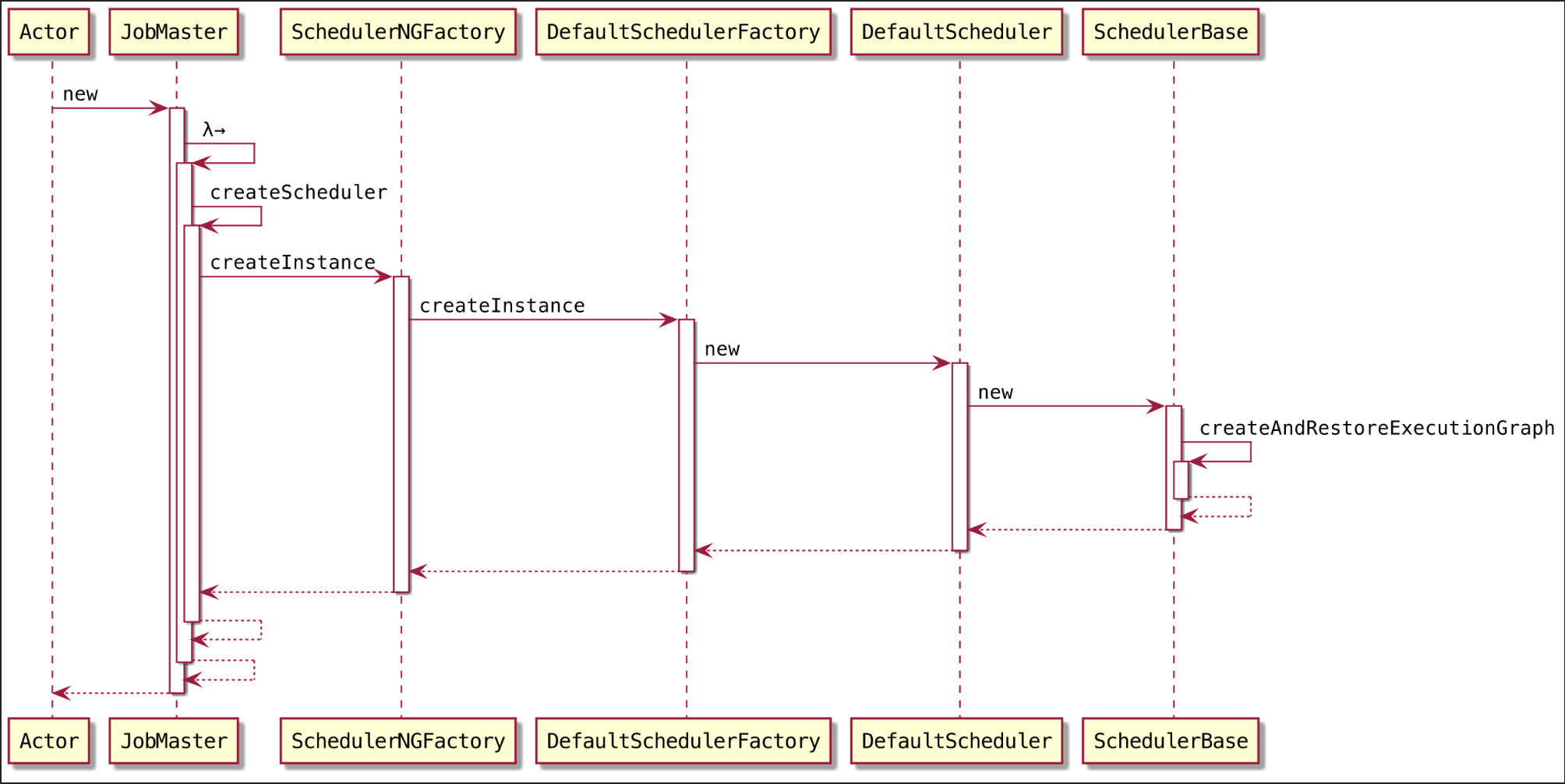
先来看看 DefaultSchedulerFactory#createInstance()~~~
2.3.1. DefaultSchedulerFactory#createInstance()
设置调度策略
设置重启策略
构造 SlotProviderStrategy
实例化调度器
点点点~~~,顺着时序图来到 ExecutionGraphBuilder.java#buildGraph() ,该方法是将 JobGraph 转为 ExecutionGraph的核心代码~~~
2.3.2. ExecutionGraphBuilder.java#buildGraph()
从 JobGraph 中获取 JobName 和 JobID

构建包含 job 信息的 JobInformation 对象
1
2
3
4final JobInformation jobInformation =
new JobInformation(jobId, jobName, jobGraph.getSerializedExecutionConfig(),
jobGraph.getJobConfiguration(), jobGraph.getUserJarBlobKeys(),
jobGraph.getClasspaths());释放 IntermediateResultPartition 的策略
1
2final PartitionReleaseStrategy.Factory partitionReleaseStrategyFactory =
PartitionReleaseStrategyFactoryLoader.loadPartitionReleaseStrategyFactory(jobManagerConfig);初始化 ExecutionGraph 对象
设置 ExecutionGraph 基本属性
以 Json 格式
1
executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));
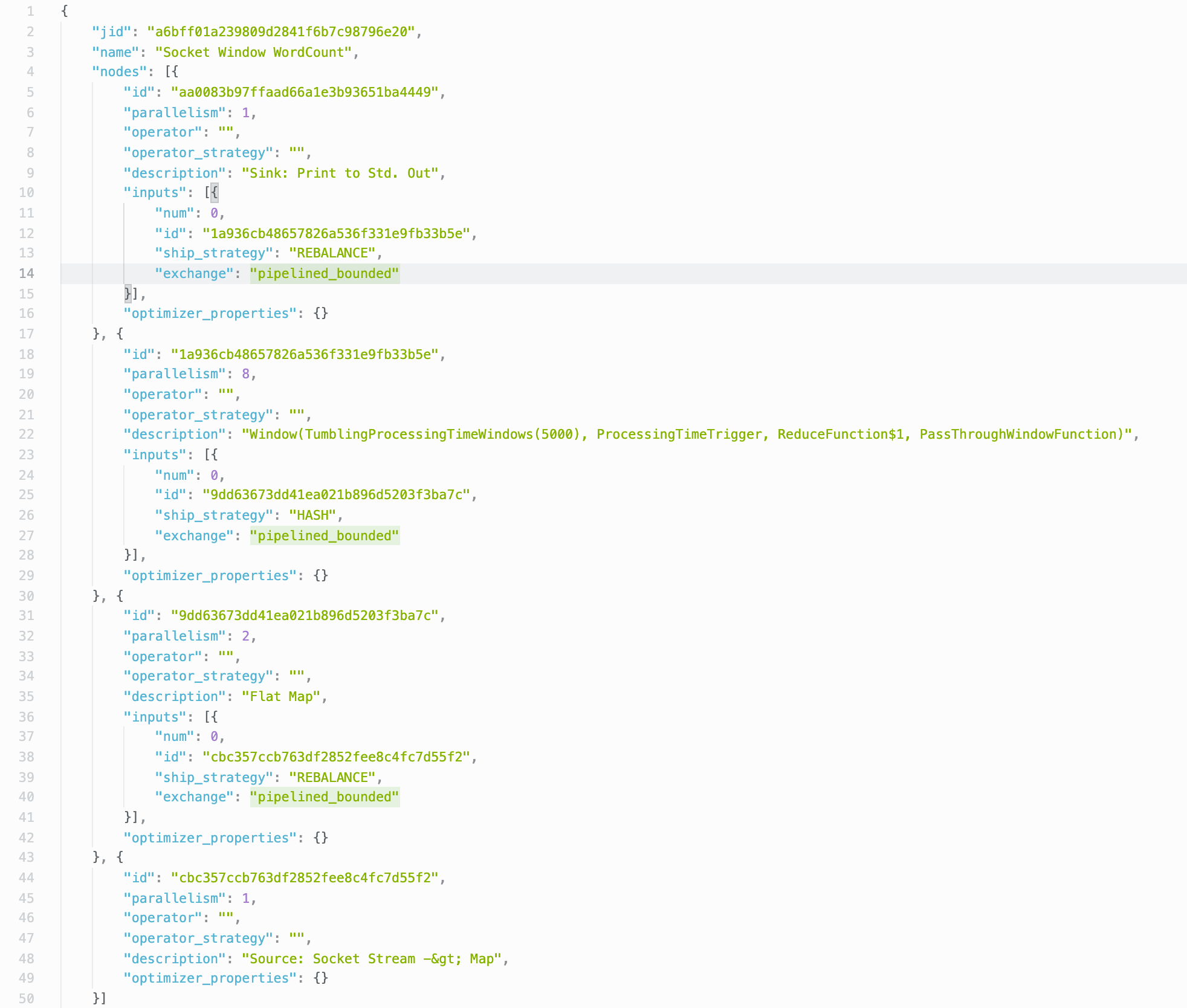
遍历 JobVertex 并进行初始化
- 获取 JobVertex 的 invokableClassName
- vertex.initializeOnMaster(classLoader)
executionGraph.attachJobGraph(sortedTopology)来啦来啦,最核心的代码~,方法主体在一个 for 循环里,遍历所有的 JobVertex
一个 JobVertex 对应的创建一个 ExecutionJobVertex
1
2
3ExecutionJobVertex ejv = new ExecutionJobVertex(this, jobVertex, 1,
maxPriorAttemptsHistoryLength, rpcTimeout,
globalModVersion, createTimestamp);ejv.connectToPredecessors(this.intermediateResults)处理 JobEdge 和 IntermediateResult 和 ExecutionJobVertex中的 ExecutionVertex,对每个 JobEdge,获取对应的 IntermediateResult,并记录到本节点的输入上,最后,把每个 ExecutorVertex 和对应的 IntermediateResult 关联起来
方法主体同样在一个 for 循环里,遍历 jobVertex 的所有输入 JobEdge
如图获取
FlatMap的输入边 JobEdge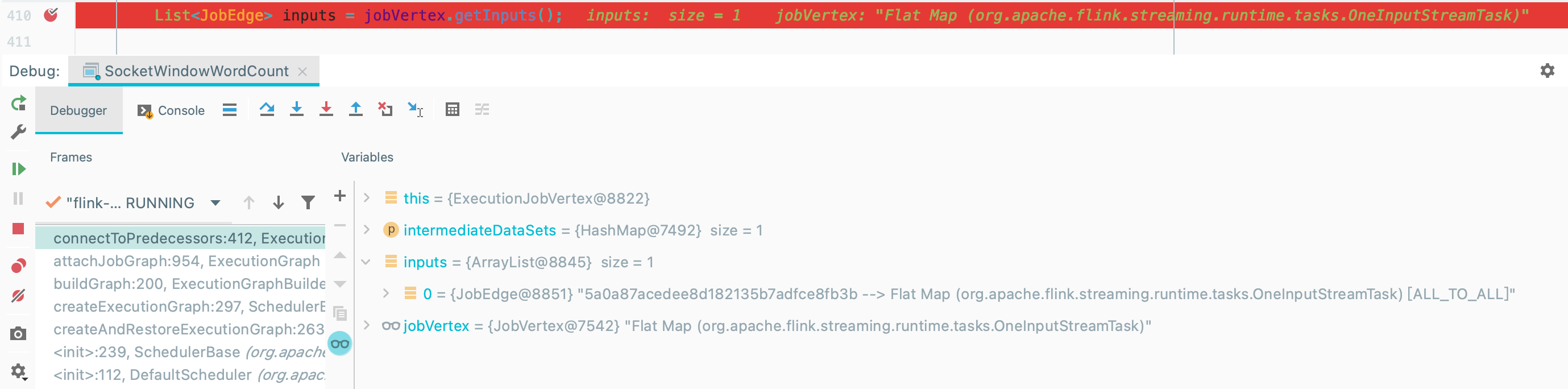
遍历 JobEdge
获取到 JobEdge 连接的 IntermediateResult
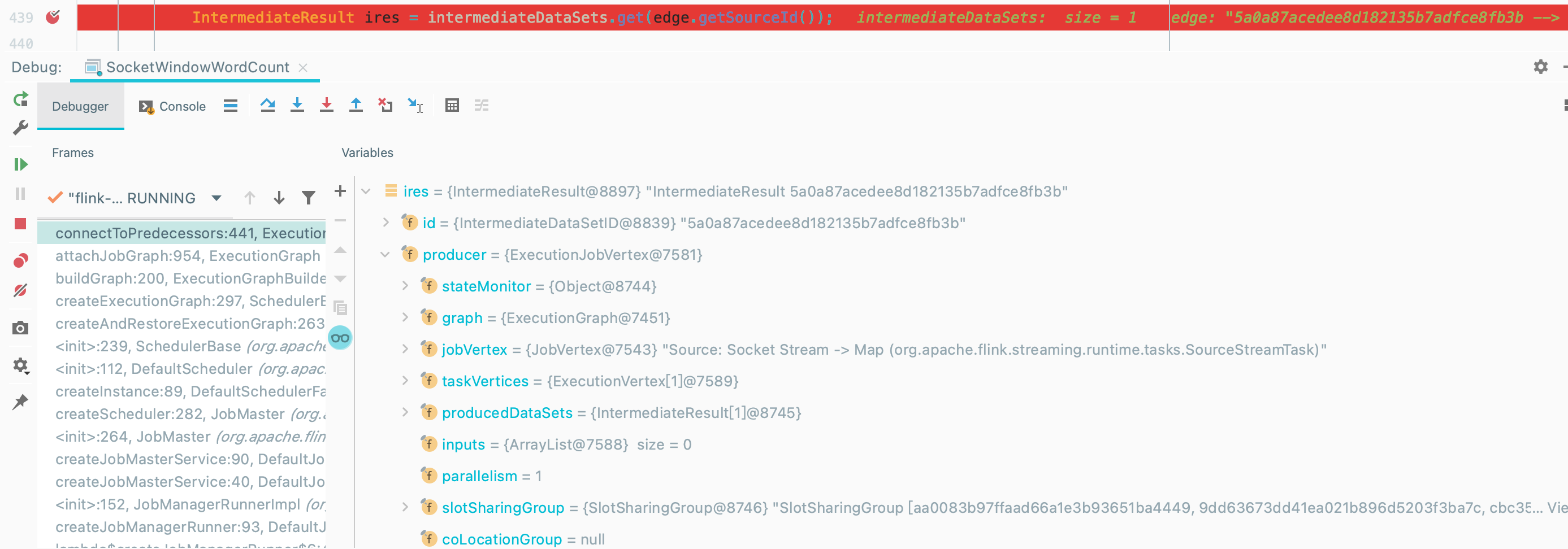
将当前 IntermediateResult 作为 ExecutionJobVertex 的输入
1
this.inputs.add(ires);
根据并行度来设置 ExecutionVertex
我们的并行度为2~~~

将生成好的 ExecutionJobVertex 加入到 ExecutionGraph 中
1
ExecutionJobVertex previousTask = this.tasks.putIfAbsent(jobVertex.getID(), ejv);
将当前 JobVertex 的输入 IntermediateResult 加入到 intermediateResults map 中
1
2
3
4for(IntermediateResult res : ejv.getProducedDataSets()) {
IntermediateResult previousDataSet =
this.intermediateResults.putIfAbsent(res.getId(), res);
}顺序保存 ExecutionJobVertex
1
this.verticesInCreationOrder.add(ejv);
获取总并行度
ExecutionJobVertex 加入 newExecJobVertices List 中
设置 checkpoint
设置状态后端
到这基本完成了将 JobGraph 转换为 ExecutionGraph 的过程, JobGraph 转换为 ExecutionGraph 的过程是实例化 JobMaster 核心之一
在创建 JobManagerRunner 结束之后~~~,我们开始 startJobManagerRunner 啦~~~
2.4. 运行 JobManagerRunner
这儿 JobManagerRunner 指的就是 JobMaster~
客户端正常提交一个 job 的时候,最终由集群主节点中的 Dispatcher 接收继续提交执行,回到 Dispatcher#runJob()
JobMaster 已经实例化结束,接下来将任务提交到 JobMaster 开始运行~~~
将创建的 jobManagerRunnerFuture 对象添加到 jobManagerRunnerFutures 中,防止 Job 重复执行。
1 | jobManagerRunnerFutures.put(jobGraph.getJobID(), jobManagerRunnerFuture); |
提交任务
1 | FunctionUtils.uncheckedFunction(this::startJobManagerRunner) |
因为 JobMaster 服务实现了高可用,所以在启动它时,会通过调用 leaderElectionService 启动LeaderContender 实现类 JobManagerRunnerImpl。
1 | leaderElectionService.start(this); |
这种格式我们见过好多次了~,选举成功,则跳转到 ZooKeeperLeaderElectionService 的 isLeader() 方法来到 isLeader()~,这个方法我们来过好几次了😯~
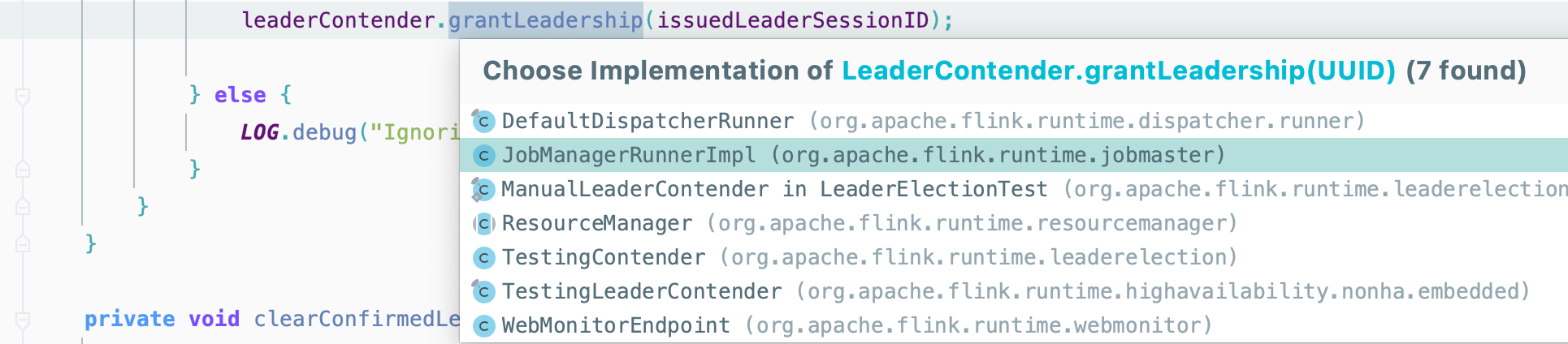
这次轮到 JobManagerRunnerImpl~
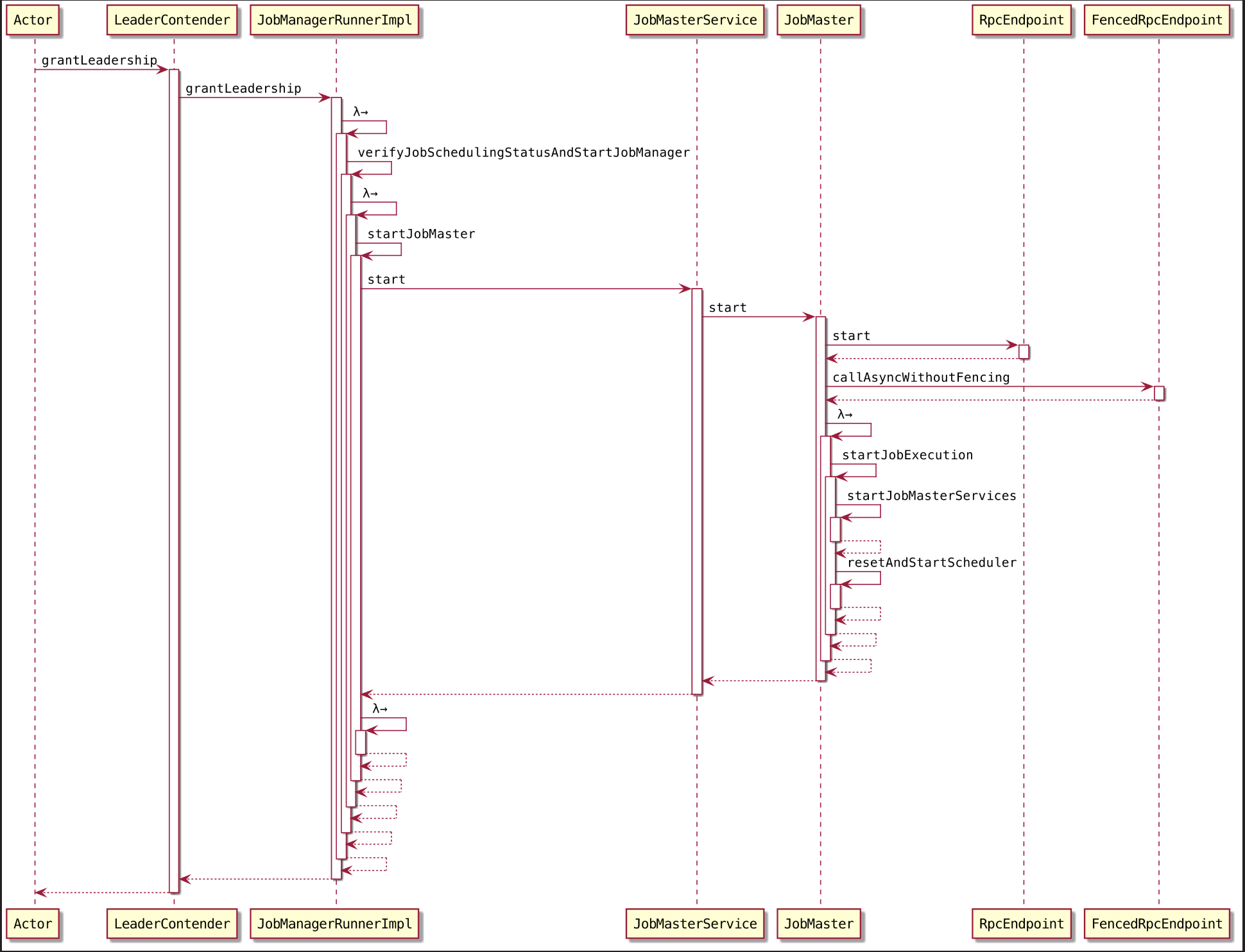
grantLeadership() 最终会调用verifyJobSchedulingStatusAndStartJobManager()方法启动 JobMaster服务
来到 verifyJobSchedulingStatusAndStartJobManager()~~~
2.4.1. 获取 Job 的调度状态
1 | final CompletableFuture<JobSchedulingStatus> jobSchedulingStatusFuture = getJobSchedulingStatus(); |
2.4.2. 启动 JobMaster
首先判断返回的 JobSchedulingStatus 是否为 JobSchedulingStatus.DONE,如果是,则表明 Job 已经被其他的 JobMaster 执行过,此时调用 jobAlreadyDone()方法处理后续流程;否则调用创建并启动新的JobMaster服务。然后通过该 JobMaster 调度和执行 JobGraph 中的Task实例
1 | if (jobSchedulingStatus == JobSchedulingStatus.DONE) { |
在 runningJobsRegistry 中注册当前的 JobId 信息,当 JobMaster 启动好了之后,更改 Job 状态为 Running
1
runningJobsRegistry.setJobRunning(jobGraph.getJobID());
启动 JobMaster
1
startFuture = jobMasterService.start(new JobMasterId(leaderSessionId));
启动 JobMaster 对应的 RPC 服务
执行 JobGraph
1
callAsyncWithoutFencing(() -> startJobExecution(newJobMasterId), RpcUtils.INF_TIMEOUT);
JobMaster 的注册和心跳
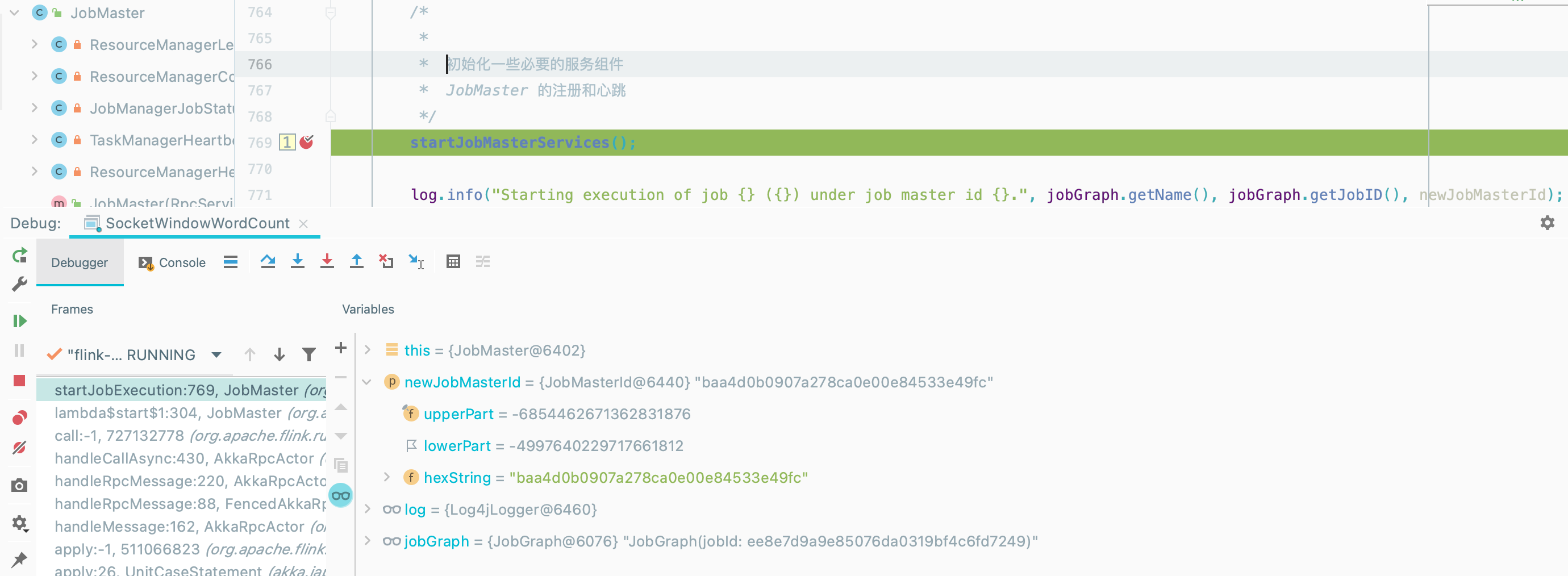
- 启动心跳服务
- 启动 SlotPool 和 scheduler 服务
- 向 ResourceManager 注册该 JobMaster
- 工作准备就绪,请尝试与资源管理器建立连接
这儿的注册和心跳机制 和 TaskManager基本一样,可以参考这个哦😯~~~
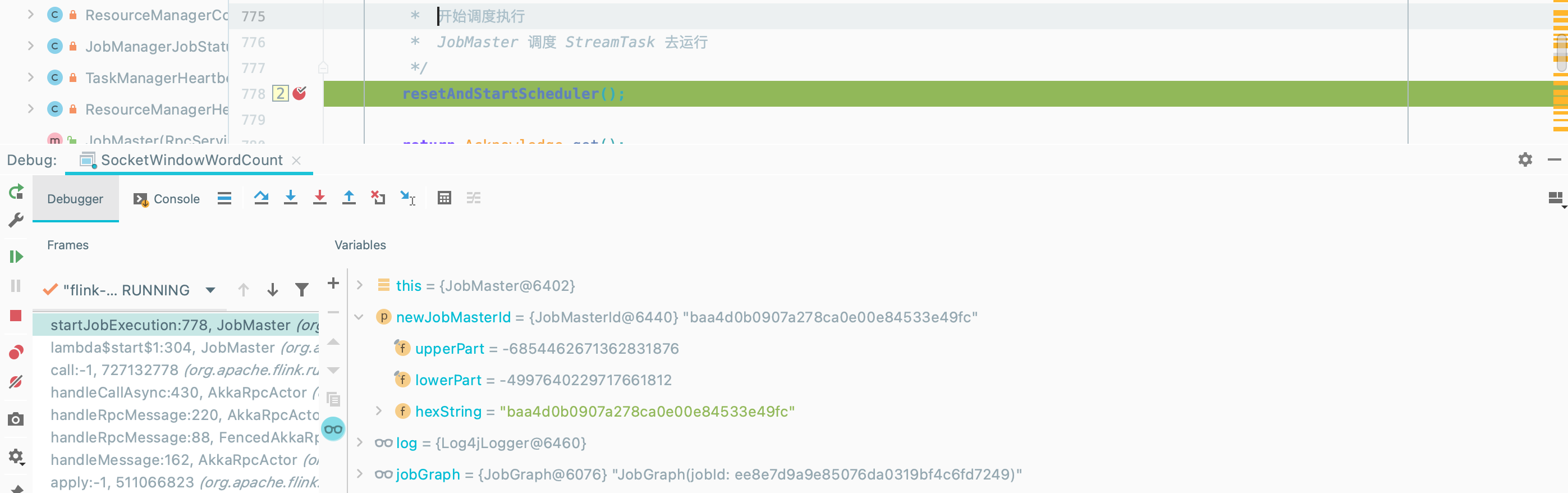
JobMaster 调度 StreamTask 去运行
 微信
微信 支付宝
支付宝