Flink-源码学习-Job 提交-Graph 演变-JobGraph 构建
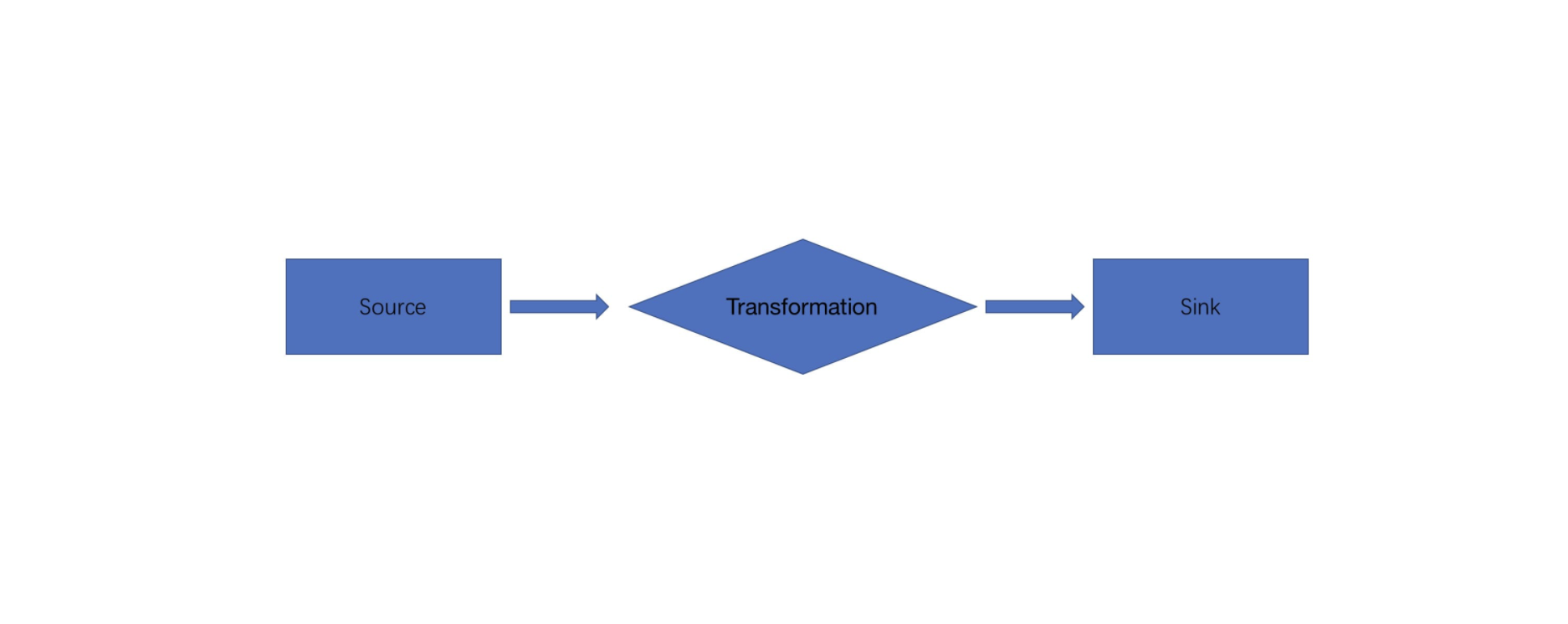
JobGraph 数据结构在本质上是将节点和中间结果集相连得到有向无环图。JobGraph 是客户端和运行时之间进行作业提交使用的统一数据结构,不管是流式 (StreamGraph) 还是批量 (OptimizerPlan),最终都会转换成集群接受的 JobGraph 数据结构。
一、概述
StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构
它包含的主要抽象概念有:
Jobvertex
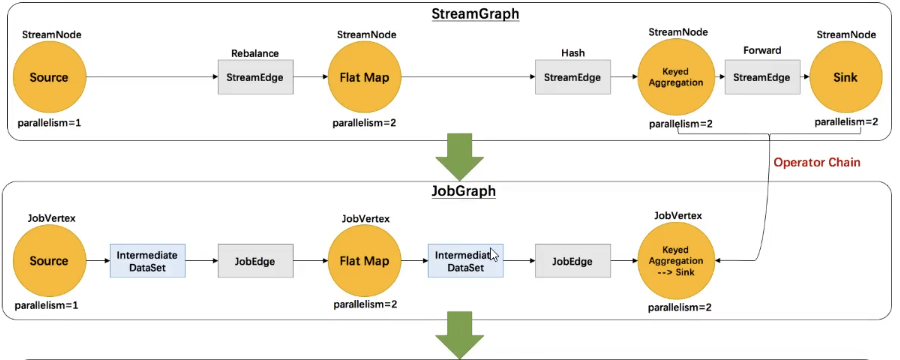
经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 Jobvertex, 即一个 JobVertex 包含一个或多个 operator, JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
IntermediateDataSet
表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是 Jobvertex, consumer 是 JobEdge
JobEdge
代表了job graph中的一条数据传输通道。source 是 IntermediateDataset, target 是 Jobvertex。即数据通过JobEdge 由 IntermediateDataset传递给目标Jobvertex。
二、源码
从 Source 节点开始,StreamGraph 会经过作业链优化生成 JobGraph,提交给 JobManager 的数据结构,将并行度相同且流传输模式为 one-to-one 的节点 chain 在一起作为一个节点,以减少数据在节点之间流动所需要的传输消耗。经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个JobVertex,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
2.1. 构建 JobGraph
来到 构建 JobGraph 的入口~
点点点~,来到 StreamingJobGraphGenerator#createJobGraph()
2.1.1. 设置 ScheduleMode
1 | jobGraph.setScheduleMode(streamGraph.getScheduleMode()); |
Flink 内部提供了三种调度模式:
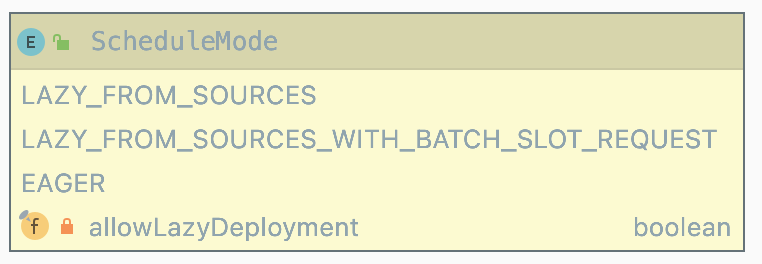
LAZY_FROM_SOURCES
LAZY_FROM_SOURCES 适用于批处理。从 SourceTask 开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游 Task 执行完毕后开始调度执行下游的 Task,读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的 Task,依次进行调度,直到作业完成。
EAGER
适用于流计算。一次性申请需要的所有资源,如果资源不足,则作业启动失败。
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST 适用于批处理。与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作业,但是需要确保在本阶段的作业执行中没有 Shuffle 行为。
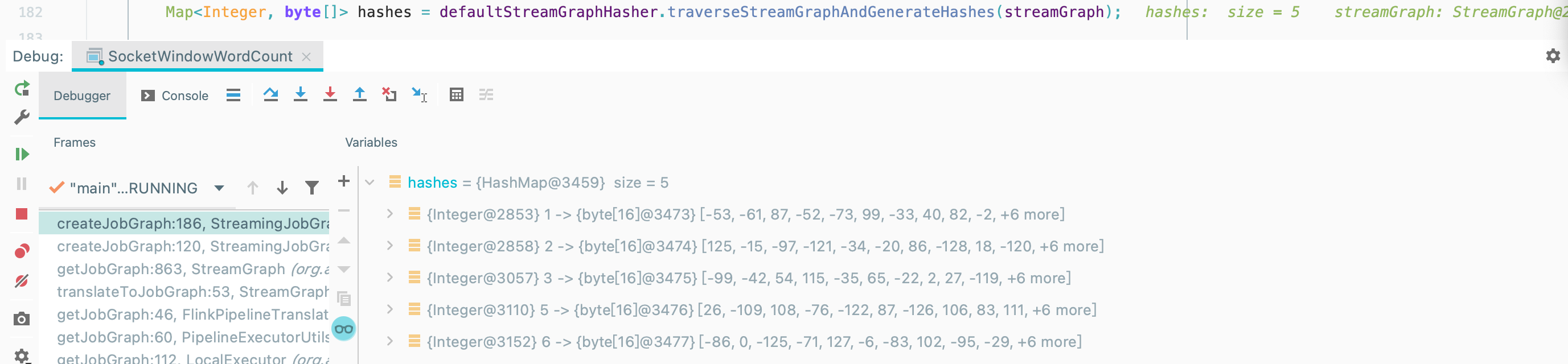
2.1.2. 为节点生成确定性哈希
对 StreamGraph 的 StreamNode 进行哈希化处理,用于生成 JobVertexID。
在 StreamGraph 中 StreamNodeID 为数字表示,而在 JobGraph 中 JobVertexID 由哈希码生成,通过哈希码区分 JobGraph中的节点。
1 | Map<Integer, byte[]> hashes = |
key 为节点 StreamNode Id
value 为 byte[] 类型,StreamNode 生成的哈希值
2.1.3. 设置 Chaining
将可以 chain 到一起的 StreamNode Chain 在一起
1 | setChaining(hashes, legacyHashes); |
根据每个节点生成的哈希码从源节点开始递归创建 JobVertex 节点,此处会将多个符合条件的 StreamNode节点链化在一个
JobVertex 节点中。执行过程中会根据 JobVertex 创建OperatorChain,以减少数据在 TaskManager 之间网络传输的性能消耗。

一个 StreamNode 也可以认为是 做了 chain 动作 StreamNode -> JobVertex,两个StreamNode 做了 chain 动作 StreamNode + StreamNode -> JobVertex
存储 chain 的 出边集合
1
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
初始化存储可 chain 的 StreamEdge
1
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
存储不可 chain 的 StreamEdge
1
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
判断是否可以 chain 在一起
1
2
3
4
5
6
7for(StreamEdge outEdge : currentNode.getOutEdges()) {
if(isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}isChainable()
判断一个 StreamEdge 链接的上下游 Operator 是否可以 chain 在一起。如图,按照我们的程序代码首先会判断
Source和Map~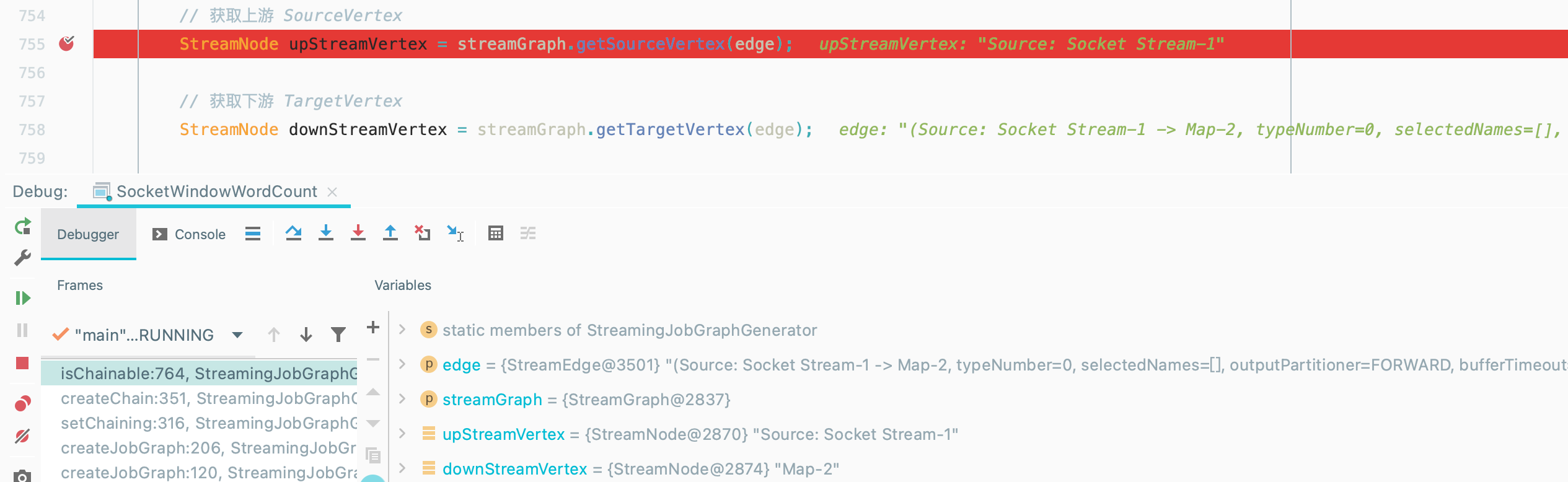
算法中给出了算子是否可以合并为算子链的几个条件~
1
2
3
4
5
6
7boolean isChainable = downStreamVertex.getInEdges().size() == 1
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& edge.getShuffleMode() != ShuffleMode.BATCH
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled();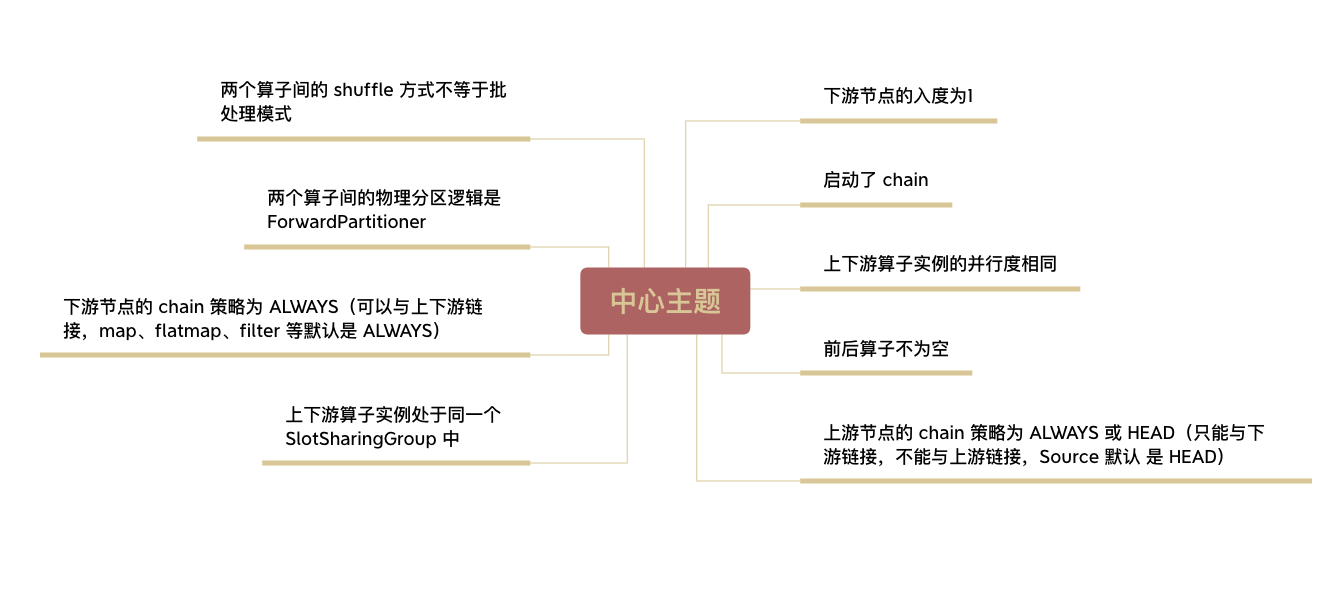
根据条件得到
isChainable = true,所以Source和Map可以合并哒~
如果可以 chain,则加入集合
chainableOutputs,否则加入集合nonChainableOutputs
同理根据代码,接下来判断
Map和FlatMap是否可以形成一个 OperatorChain ~,结果是这两个算子不可以~😭
把可以 chain 在一起的 StreamEdge 两边的 Operator chain 在一个形成一个 OperatorChain
1
2
3for(StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(createChain(chainable.getTargetId(), chainIndex + 1, chainInfo));
}如果可以 chain 在一起的话,chainIndex 加 1,同时递归调用
createChain(),其实方法参数中sourceNodeId为 chainable 的 TargetId,也就是我们例子中的map~不能 chain 一起的话,递归调用
createChain()这里的 chainIndex 是从 0 开始,同时 会将 chainInfo 中的 startNode 加一,当前 StreamEdge 的 getTargetId节点和前面的chain 断裂,重新开始新的 chain,chain 的 startNodeId 为
nonChainable.getTargetId()1
2
3
4for(StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(nonChainable.getTargetId(), 0, chainInfo.newChain(nonChainable.getTargetId()));
}我们例子中 TargetId=3 的时候,即
FlatMap算子会和 由map和source构成的 算子链断开~
把 可以 chain 在一起的多个 Operator 创建成一个 JobVertex
如果当前节点是 chain 的起始节点, 则直接创建 JobVertex 并返回 StreamConfig, 否则先创建一个空的 StreamConfig
获取 startStreamNode
生成一个 JobVertexID
1
JobVertexID jobVertexId = new JobVertexID(hash);
生成 operatorIDPairs
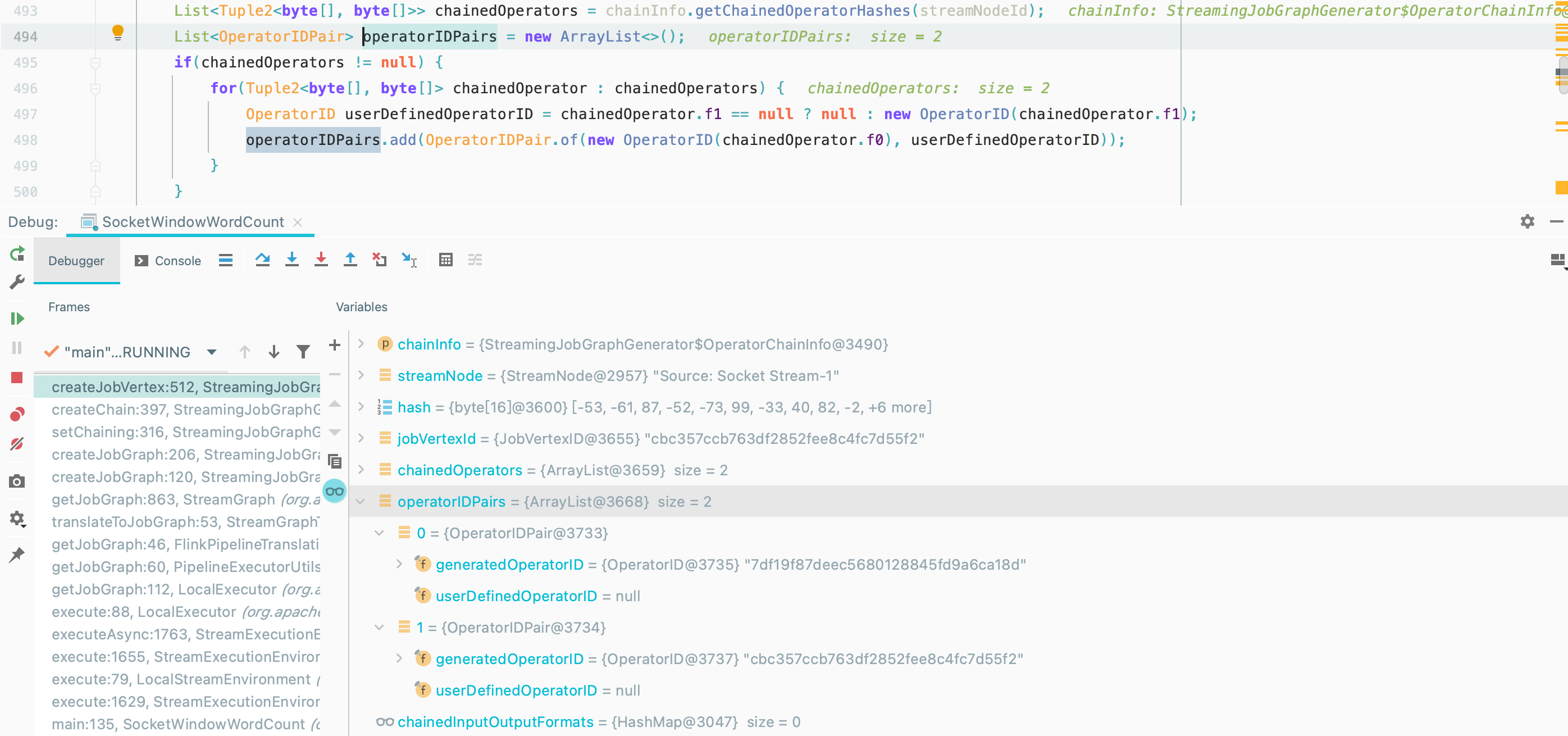
JobVertex 初始化
1
jobVertex = new JobVertex(chainedNames.get(streamNodeId), jobVertexId, operatorIDPairs);
获取 JobVertex 的并行度
将生成好的 JobVertex 加入到 JobGraph
设置 JobVertex 的 StreamConfig
基本上是将 StreamNode 中的配置设置到 StreamConfig 中
2.1.4. 入边集合
将每个 JobVertex 的入边集合也序列化到该 JobVertex 的 StreamConfig 中
1 | setPhysicalEdges(); |
2.1.5. 设置 SlotSharingAndCoLocation
1 | setSlotSharingAndCoLocation(); |
2.1.6. 设置 ManagedMemoryFraction
1 | setManagedMemoryFraction( |
2.1.7. checkpoint 相关的设置
1 | configureCheckpointing(); |
2.1.8. 设置 SavepointRestoreSettings
1 | jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings()); |
到这基本完成了将 StreamGraph 转换为JobGraph的过程,接下来向 Flink 集群提交创建的 JobGraph 对象~~~
2.2. JobGraph 提交
JopGraph 数据结构是Flink客户端与集群交互的统一数据结构,不管是批数据处理的 DataSet API、流数据处理的 DataStream API,还是 Table/SQL API,最终都会将作业转换成 JobGraph 提交到集群中运行。
1 | return clusterClient.submitJob(jobGraph) |
将 JobGraph 提交到集群主要是通过 ClusterClient完成的,ClusterClient 构建了与集群运行时中 Dispatcher 之间的RPC连接
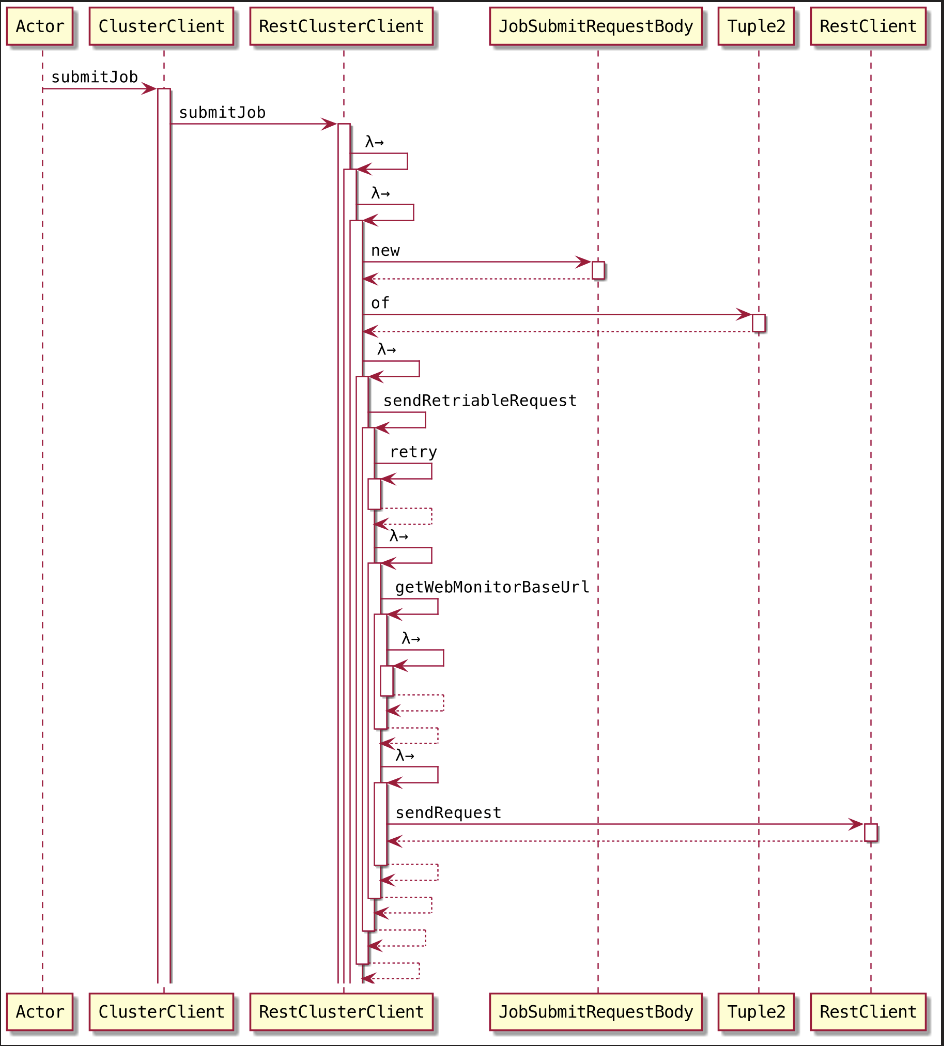
开始一步一步来~~~,RestClusterClient 提交到 Flink Rest 服务接收处理

持久化
把 JobGraph 持久化到磁盘文件形成 jobGraphFile
- 持久化 JobGraph 的前缀:
flink-jobgraph - 持久化 JobGraph 的后缀:
.bin
把 JobGraph 持久化为一个文件: jobGraphFile
1
final java.nio.file.Path jobGraphFile = Files.createTempFile("flink-jobgraph", ".bin");
其实,在提交 JobGraph 到 Flink 集群运行额时候,其实提交的就是 这个文件‼️哦~~~,Flink 集群的 WebMonitor (JobSubmitHandler) 接收请求来执行处理的第一件事情就是把传送过来的这个文件反序列化得到 JobGraph 这个对象~
- 持久化 JobGraph 的前缀:
上传文件
1
filesToUpload.add(new FileUpload(jobGraphFile, RestConstants.CONTENT_TYPE_BINARY));
构建提交任务的请求体
包含对应的一些资源, 主要是 JobGraph 的持久化文件 和 对应的依赖 jar
1
2final JobSubmitRequestBody requestBody = new
JobSubmitRequestBody(jobGraphFile.getFileName().toString(), jarFileNames,artifactFileNames);返回一个 Tuple2
包含两个返回结果: requestBody 和 filesToUpload
发送上传文件请求
1
2
3
4
5requestAndFileUploads -> sendRetriableRequest(JobSubmitHeaders.getInstance(),
EmptyMessageParameters.getInstance(),
requestAndFileUploads.f0,
requestAndFileUploads.f1,
isConnectionProblemOrServiceUnavailable()));通过 Http Restful 方式提交,提交 Request 给 WebMonitorEndpoint, 最终由 JobSubmitHandler 来执行请求处理
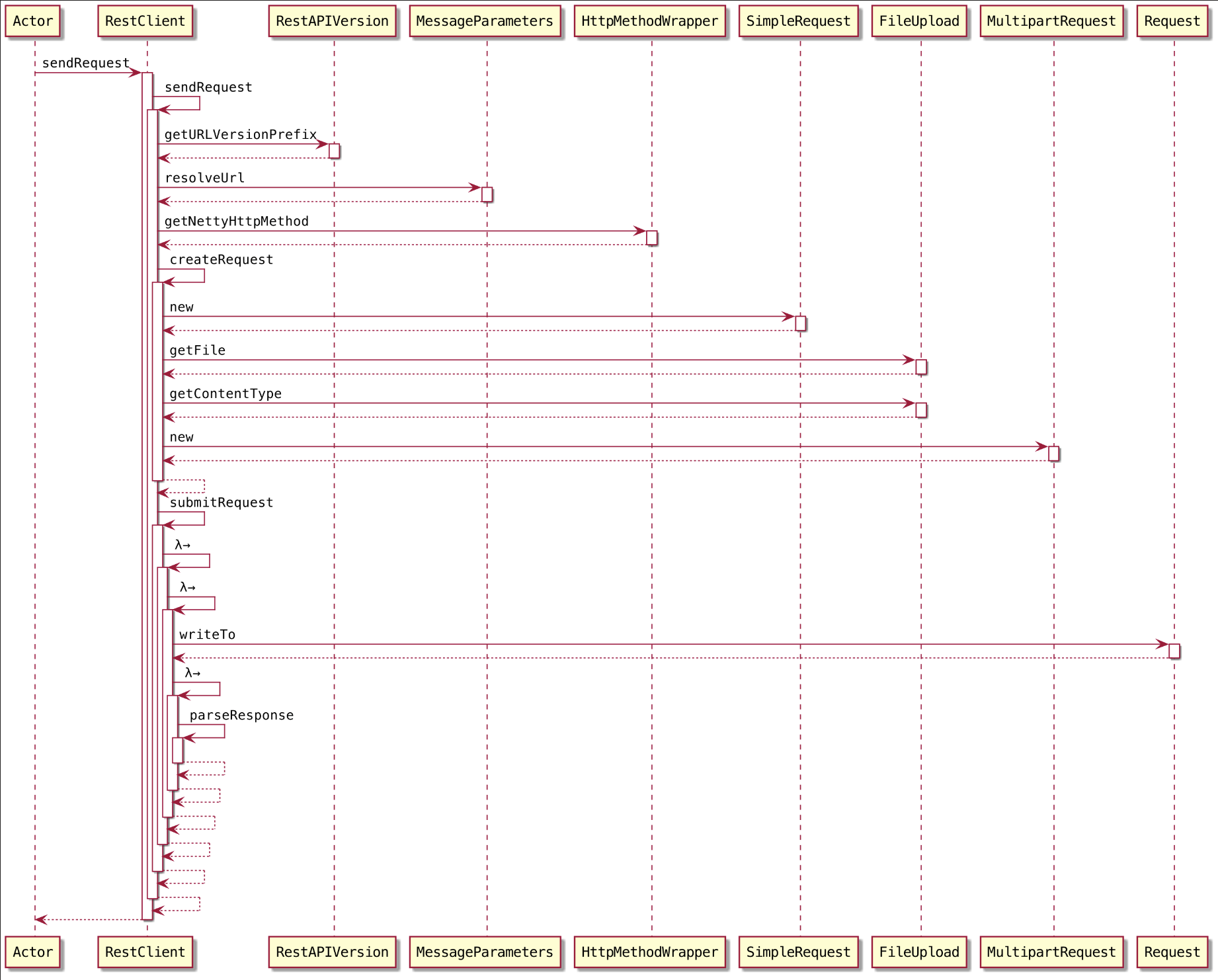
删除文件
在
sendRetriableRequest提交完成之后,删除生成的 JobGraphFile
 微信
微信 支付宝
支付宝