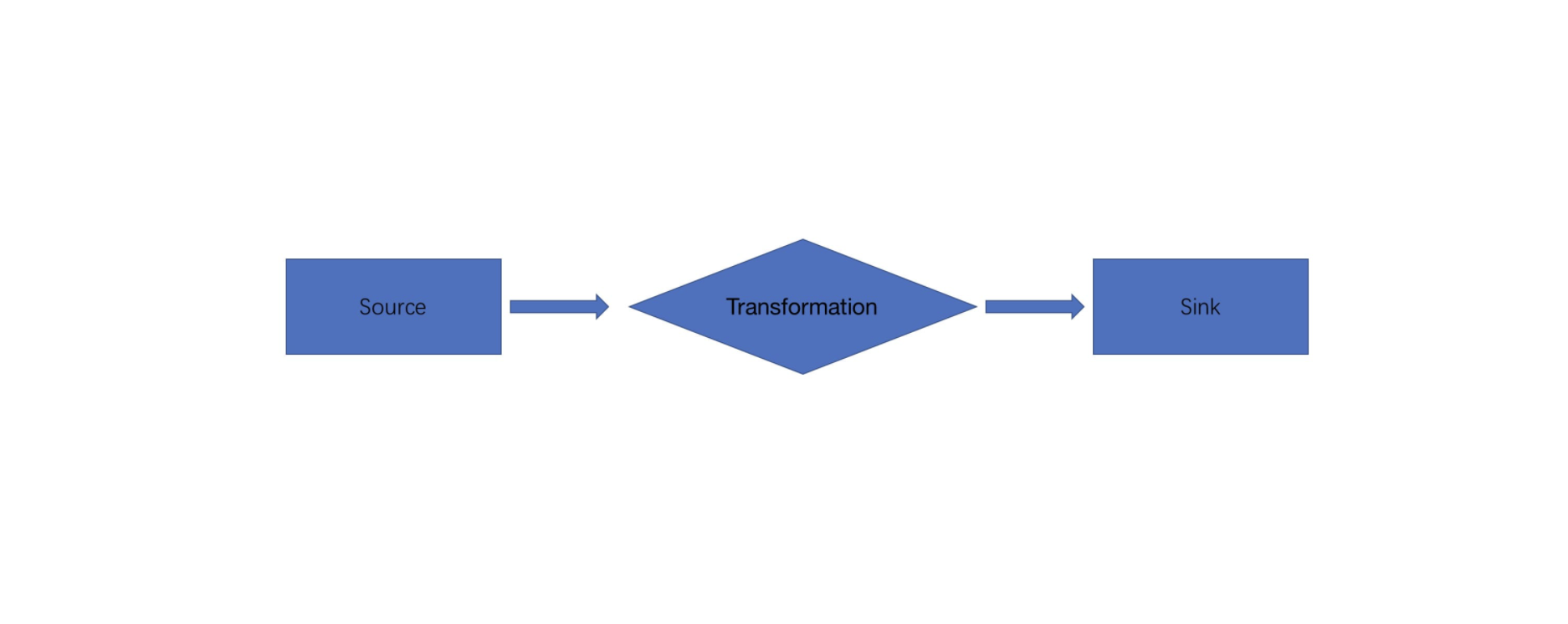
Flink-源码学习-Job 提交-Graph 演变-StreamGraph 构建
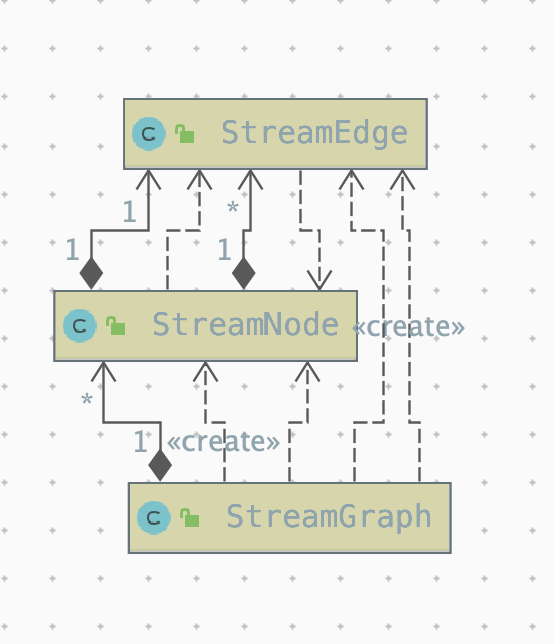
根据用户通过 Stream API 编写的代码,从 Source 节点开始,每一次 transform 生成一个 StreamNode,两个 StreamNode 通过 StreamEdge 连接在一起,形成 DAG
StreamNode 用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
StreamEdge表示连接两个StreamNode的边。
当客户端调用 StreamExecution Environment.execute() 方法执行应用程序代码时,就会通过 StreamExecutionEnvironment 中提供的方法生成
StreamGraph 对象。StreamGraph 结构描述了作业的逻辑拓扑结构,并以有向无环图的形式描述作业中算子之间的上下游连接关系。下面来看
StreamGraph的底层实现及构建过程~~~
一、概述
StreamGraph 结构是由 StreamGraphGenerator 通过 Transformation 集合转换而来的,StreamGraph 实现了Pipeline的接口,且通过有向无环图的结构描述了 DataStream 作业的拓扑关系。StreamGraph结构包含 StreamEdge 和 StreamNode 等结构,此外,StreamGraph结构还包含任务调度模式 ScheduleMode 及 TimeCharacteristic 时间概念类型等与作业相关的参数。
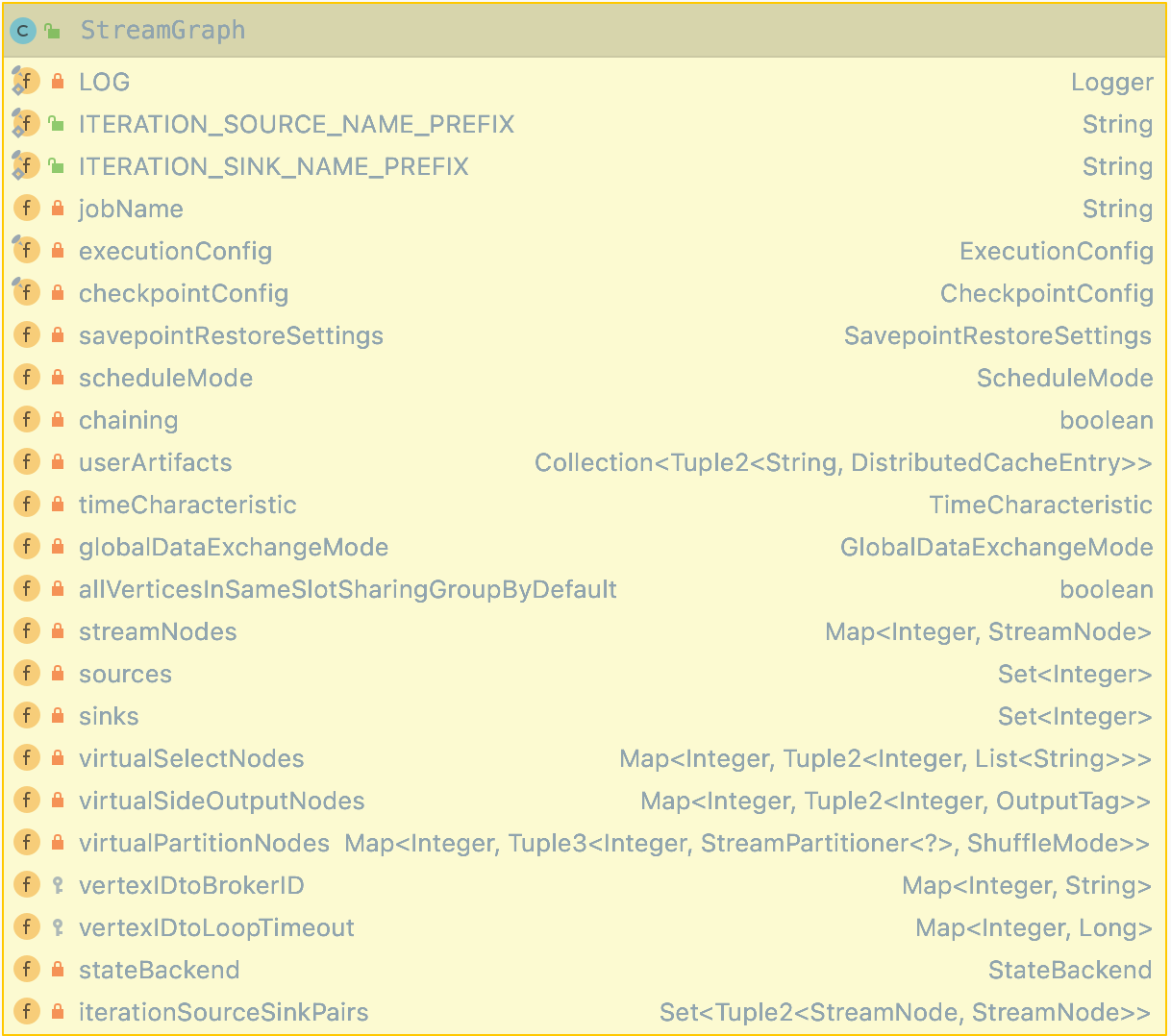
StreamGraph 中存储了这个 StreamGraph 中的所有 StreamNode, 在 StreamNode 节点中,会存储 StreamNode,和 StreamNode 之间的边 StreamEdge 之间的关系
二、源码
当客户端调用 StreamExecutionEnvironment.execute() 方法执行应用程序代码时,就会通过StreamExecutionEnvironment中提供的方法生成 StreamGraph 对象。StreamGraph 结构描述了作业的逻辑拓扑结构,并以有向无环图的形式描述作业中算子之间的上下游连接关系。
1 | env.execute("Socket Window WordCount"); |
点进 execute() ~
1 | public JobExecutionResult execute(String jobName) throws Exception { |
所以可以分为 getStreamGraph(jobName) 构建 StreamGraph 和 execute(Graph) 执行 StreamGraph 两部分来看~
2.1. StreamGraph 构建
调用 StreamExecutionEnvironment.getStreamGraph() 方法获取 StreamGraph。
1 | public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) { |
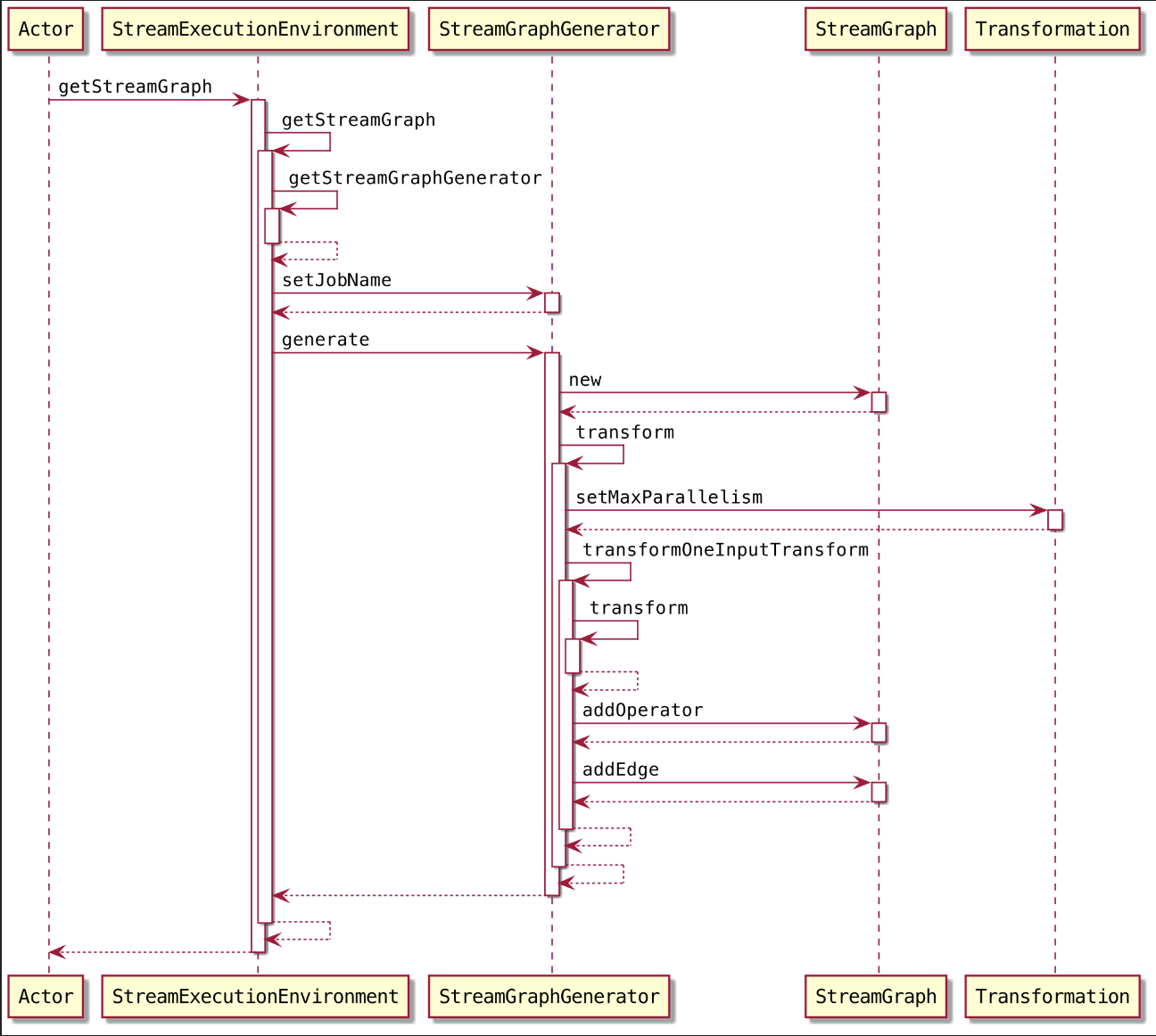
2.1.1. 获取 StreamGraphGenerator 对象
调用 StreamExecutionEnvironment.getStreamGraphGenerator() 方法获取 StreamGraphGenerator 对象
2.1.2. 生成 StreamGraph 对象
调用 StreamGraphGenerator.generate() 方法生成 StreamGraph 对象
构建 StreamGraph
设置各种属性

初始化一个容器用来去存储已经转换过的 Transformation
1
alreadyTransformed = new HashMap<>();
遍历 Transformation 集合,分别对集合中的 transformation 进行转换
从 Env 对象中,把 Transformation 拿出来,然后转换成 StreamNode
Function–> Operator–> Transformation–> StreamNode
1
2
3for (Transformation<?> transformation: transformations) {
transform(transformation);
}在执行各种算子的时候,就已经把算子转换成对应的 Transformation 放入 transformations 集合中啦~

StreamGraphGenerator.transform()方法主要涵盖了对Transformation节点的解析,根据不同的 Transformation 类型,会选择不同的解析逻辑,例如对于 OnelnputTransformation 就会调用 transformOnelnputTransform() 方法进行转换。最终将所有的 Transformation 转换为StreamGraph中对应的节点,完成整个StreamGraph对象的构建。我们来到 transform()~~~
已经转换为 StreamNode 的 transformation 会放在这个集合中
1
2
3if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}目前这个集合还为空哦~,等会儿再看~
根据 transform 的类型,做相应不同的转换
以 OneInputTransformation 为例,在 transformOnelnputTransform() 方法中,会对 OneInputTransformation 具
体的转换操作类型进行解析,常见的转换操作有 Map、Filter 等。接下来按照代码顺序,开始
Map算子~
以执行 transformOnelnputTransform() 方法将单输入类型转换操作转换成 Stream Graph 节点为例,我们来到 transformOneInputTransform() ~~~
OnelnputTransformation 转换过程主要涉及以下步骤:
递归解析当前Transformation操作对应的上游转换操作,并将解析后的 Transformation ID信息存储在 inputIds 集合中
1
Collection<Integer> inputIds = transform(transform.getInput());
获取 share group
将 transformation 添加到 StreamGraph 中。
1
2
3
4
5
6
7streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getCoLocationGroupKey(),
transform.getOperatorFactory(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());设定 KeySelector 参数信息
获得Transformation中的并行度参数,并将其设置到 StreamGraph 中。
设置当前 StreamNode 和 上游所有 StreamNode 之间的 StreamEdge
将上游转换操作的 inputld 和当前转换操作的 transformld 相连,构建成 StreamGraph 对应的边。
1
2
3for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}找到该 StreamNode 的上游顶点
如图我们这个例子上游顶点是 Source~

找到该 StreamNode 的下游顶点
我们 下游顶点是 Map

设置数据分发策略
如果上游 StreamNode 和 下游 StreamNode 的并行度一样,则使用: ForwardPartitioner 数据分发策略,如果上游 StreamNode 和 下游 StreamNode 的并行度不一样,则使用: RebalancePartitioner 数据分发策略
我们在这个测试例子中上游节点 upstreamNode 和 downstreamNode 的并行度相同,都为 1

所以我们选择 ForwardPartitioner ~
设置 ShuffleMode
构建 StreamNode 之间的边 StreamEdge 对象
设置 Source 和 Map 两个节点的边~
1
2
3StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber,
outputNames, partitioner, outputTag,
shuffleMode);
给上游 StreamNode 设置出边
1
getStreamNode(edge.getSourceId()).addOutEdge(edge);

同理给下游 StreamNode 设置入边
构建到现在我们的 StreamGraph里已经有两个 StreamNode 啦~
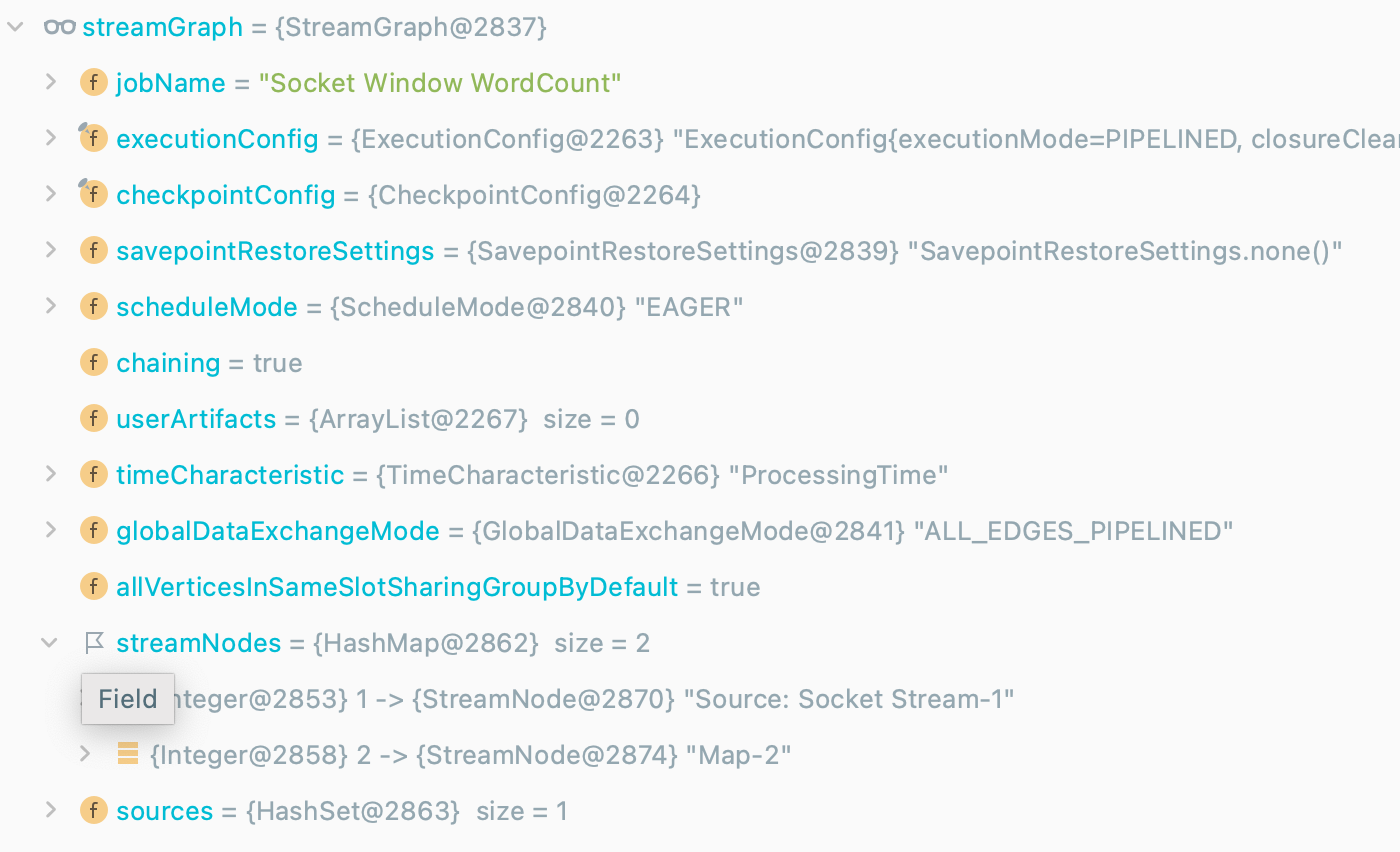
接下来按照代码顺序,开始
FlatMap算子~注意注意😯~,到这儿,我们的这个集合里面已经有两个元素了,就是刚才转换的两个算子~

接下来流程就基本一致,找到 upstreamNode 和 downstreamNode 加边~~~

同理我们处理剩余算子~
基本完成了在 StreamExecutionEnvironment 中将 Transformation 集合转换成 StreamGraph 对象啦~
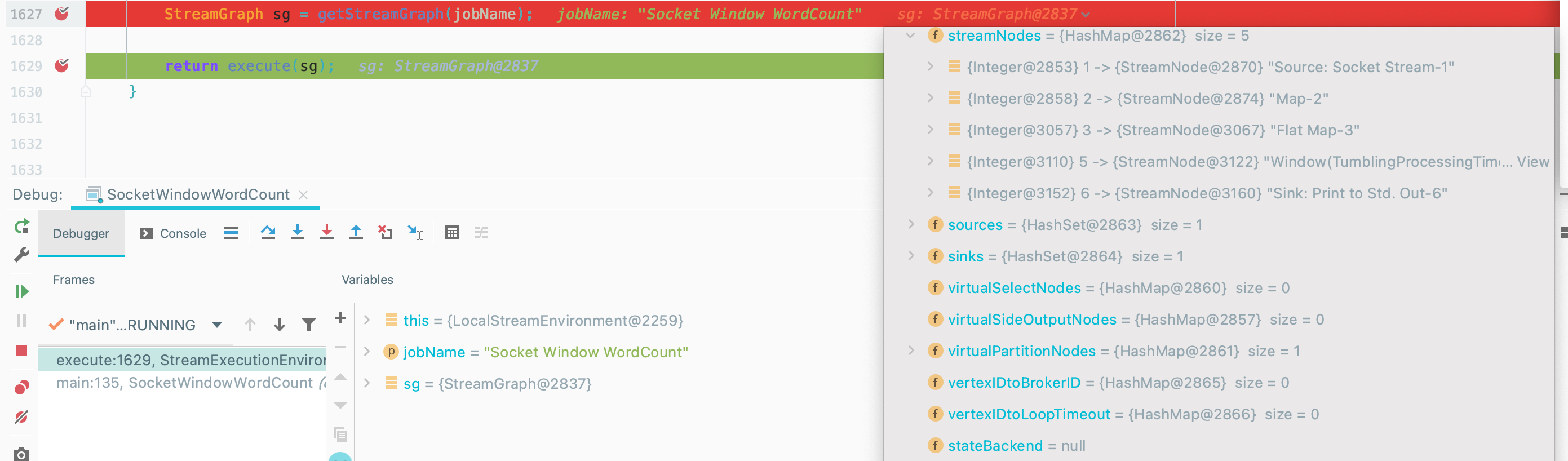
2.2. 执行 StreamGraph
在构建完 StreamGraph 之后,我们去执行~~~
1 | public JobExecutionResult execute(StreamGraph streamGraph) throws Exception { |
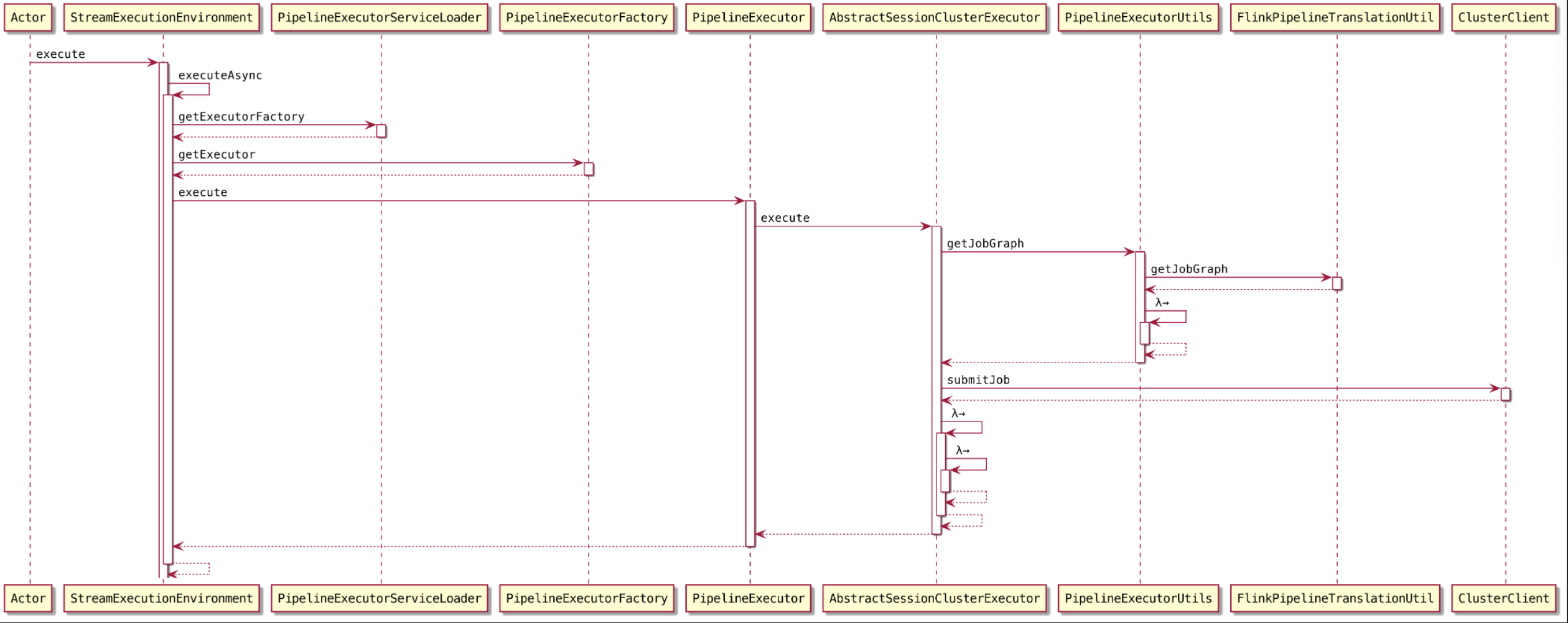
点点点~,来到核心代码 AbstractSessionClusterExecutor#execute()
1 | final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration); |
注:这儿的 pipeline 可以理解为 StreamGraph
这个方法 将 pipeline 转换成 JobGraph 提交到 Flink 集群,所以,我们下面看看 JobGraph 构建和提交~
总结
 微信
微信 支付宝
支付宝