Flink-源码学习-API-Connector-Source 设计
一、Before Flink 1.10~
在 Flink 1.10 之前,Source connector 对于批模式和流模式需要不同的处理逻辑。
- https://blog.csdn.net/qq_21383435/article/details/126816224
- https://zhuanlan.zhihu.com/p/454440159
- https://blog.csdn.net/sinat_39809957/article/details/125527633
1.1. 设计
1.1.1. Inputformat
在 DataSet API 中 Source 对应的核心接口为 InputFormat。
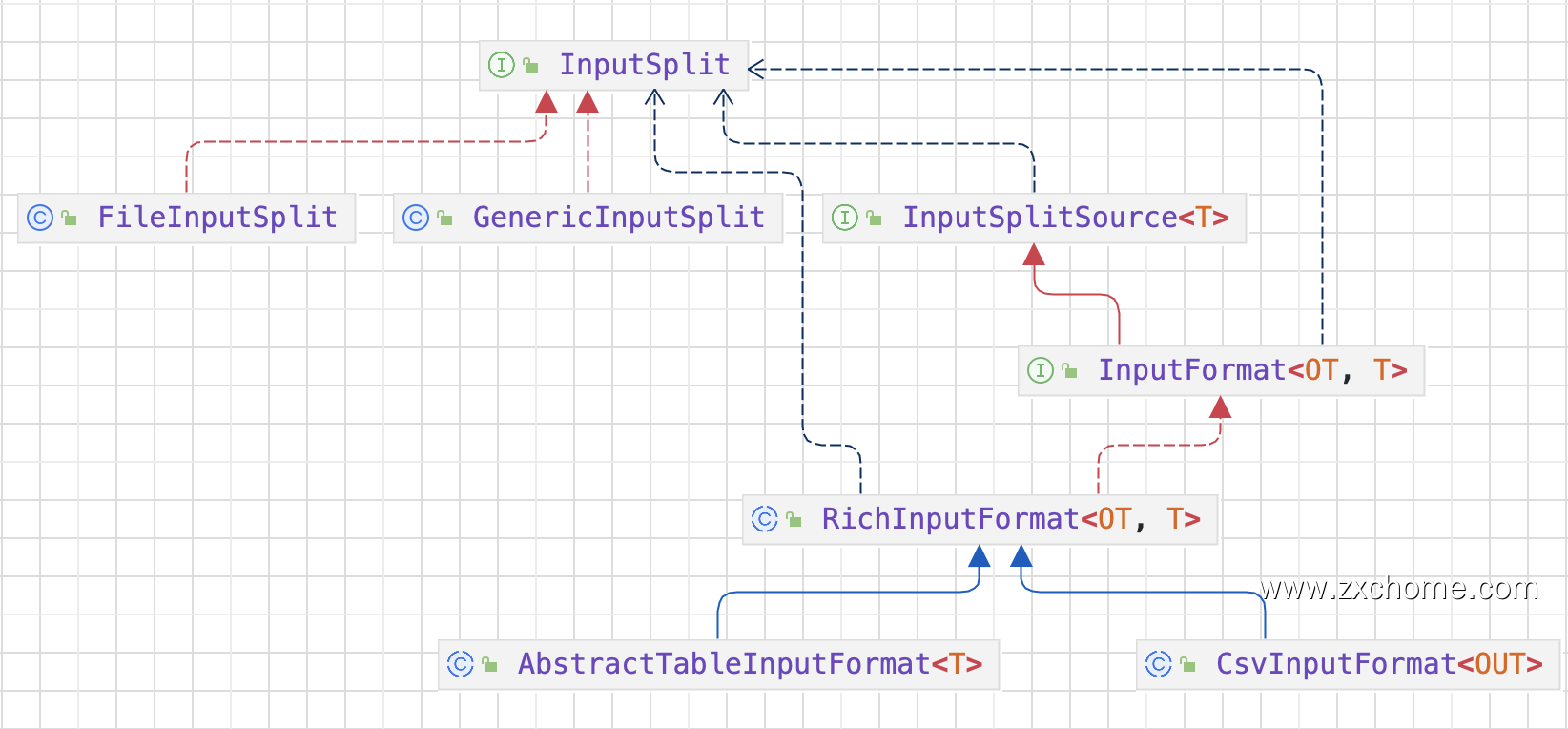
InputSplitSource 负责划分 InputSplit
InputSplit 表示一个逻辑分区,InputFormat 会根据 Split ID 读取输入数据的对应分区。
RichInputFormat 拓展 InputFormat,增加 $openInputFormat$ 和 $closeInputFormat$ 方法来管理运行时的状态。相比 InputFormat 的 $open$ 和 $close$ 是在每个 InputSplit 级别调用,
$openInputFormat$ 和 $closeInputFormat$ 是在每次 Task 执行时调用,而每次 Task 可以读多个 InputSplit,比如 TaskManager 要读取 HBase Table,需要要打开和关闭一个 HTable 的连接,这个连接可以在读多个 TableInputSplit 时复用。
ReplicatingInputFormat 拓展 RichinputFormat,为输入数据提供广播的能力。
1.1.2. SourceFunction
DataStream API 中 Source 对应的核心接口为 SourceFunction 以及 SourceContext。SourceFunction 继承 Function 接口与 Operator 交互,负责通用的状态管理(比如初始化或取消);SourceContext 代表运行时的上下文,负责与单条记录级别的数据的交互,此外还有其他一些辅助类型的类或接口。
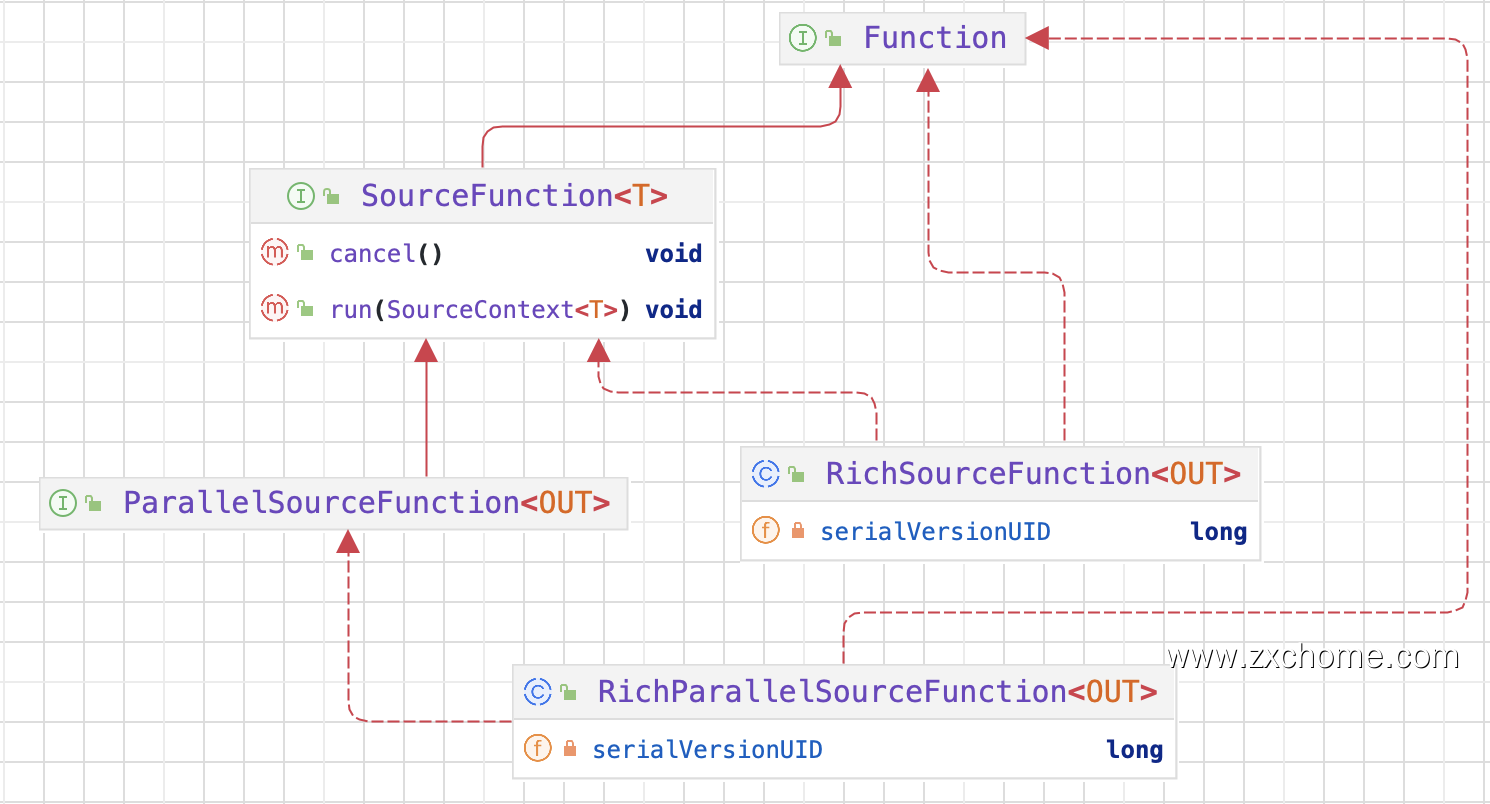
运行时,Source 主要通过 SourceContext 来控制数据的输出,主要职责包括:
- 从外部摄入数据或生成数据,输出到下游。
当 Source 开始发送数据时,SourceFunction 接口 $run$ 方法被调用,其参数 SourceContext 用于发送数据。 - 为数据生成 EventTime Timestamp。
- 计算 Watermark 并输出。
- 当暂时不会有新数据时将自己标记为 Idle,以避免下游一直等待自己的 Watermark。
ParallelSourceFunction 进一步继承 SourceFunction,标记该 Source 为可并行化的。
直接实现 SourceFunction 的 Source 的并行度只能为 1。
而 RichParallelSourceFunction 则是在 ParallelSourceFunction 基础之上再结合 AbstractRichFunction,提供有状态的并行 Source 基类。
1.2. 存在问题
不符合流批一体要求
不便动态发现数据源变更
不便 Source Subtask 间的协作
不同于 DataSet 中 Source Subtask 之间几乎是完全独立的,DataStream 中 Source Subtask 通常需要某种程度上的协作,比如不同 Subtask 之间的 Event Time 对齐。Event Time 对齐通常需要在 Master 节点上新增一个协调者,由协调者来管控 Split/Partition 的元数据,来判定某个 Source Subtask 是否需要阻塞(这点在 SourceFunction 接口上做不到)。
线程缺乏统一管理
在 DataStream 应用中,Source 通常会需要一些 IO 线程来避免阻塞 Task 主线程,而这些线程是每个 Source 独立实现,每个 Source 需要自己设计复杂的线程模型。比如常用的 Kafka Connector,每个 FlinkKafkaConsumer 会额外启动一个 Fetcher 线程负责调用 KafkaConsumer API 进行消费,然后通过阻塞队列交给 Task Thread 来进行消费。
Checkpoint Lock
在 DataStream 作业中,为了保证 State 更新和输出记录的一致性,通过 Checkpoint Lock 进行同步。SourceFunction 可以通过 SourceContext 来获取 Checkpoint Lock,但是这个锁并不是公平锁,SourceFunction 有可能一直占据 Checkpoint Lock 导致 Checkpoint 被阻塞。
二、FLIP-27~
FLIP-27 重构了 Source 接口,核心是统一流批两种执行模式的 Source 架构,新架构的核心接口是 SplitEnumerator 和 SourceReader 前者负责数据分片和分配,后者负责 Split 的读取。

此外,FLIP-27 新增 Operator 间的通信机制,Source Subtask 之间可以协调完成, Event Time 对齐等新特性。最后,SplitReader 底层封装了通用的线程模型,相比之前 SourceFunction 简化了 Source 的实现。
2.1. 架构设计
SplitEnumerator 是领导者、协调者的角色,运行在 JobMaster 上面的,SourceReader 是执行者的角色,运行在 TaskExecutor 上面。
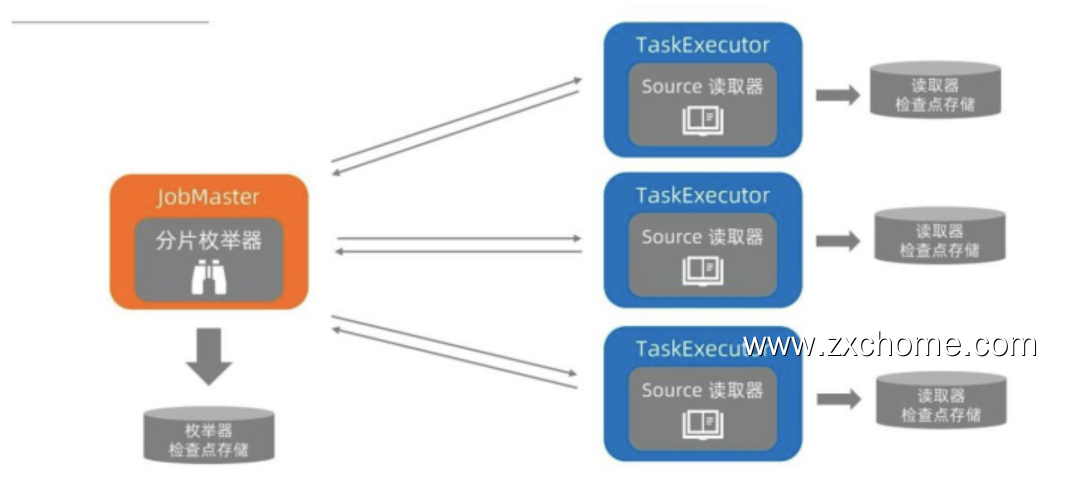
2.1.1. 通信设计
SplitEnumerator 需要给 SourceReader 来分配任务,也要通知 SourceReader 后续没有更多的分片需要处理。由于
运行环境不一样,SolitEnumerator 和 SourceReader 需要网络通信。
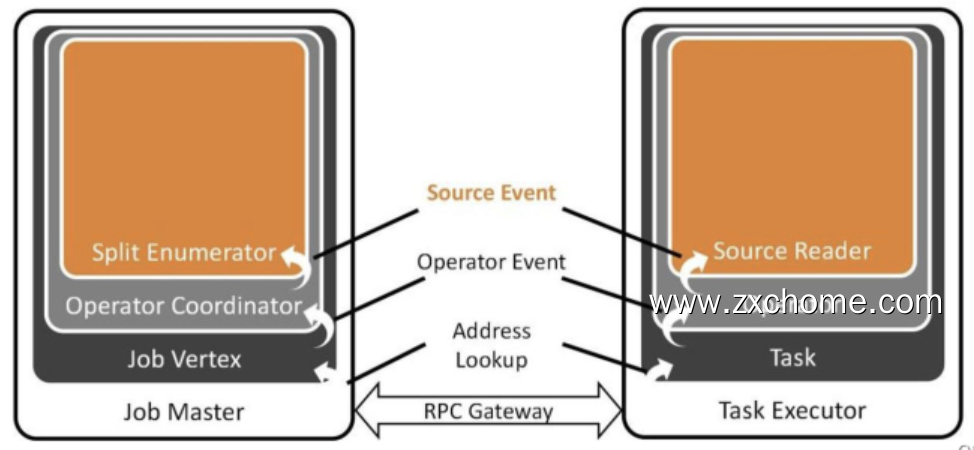
- Source Event, 开发者自定义一些客户化的操作
比如 SourceReader 在某些条件下可能要暂停读取,SplitEnumerator 可以通过 Source event 的方式发送给 SourceReader.
- Operator Coordinator, 算子的协调者。
它和真正去执行任务的算子通过 Operator Event 算子事件进行通信,如添加分片、通知leader 没有新的分片等。对于所有的Source 通用的事件,在 Operator Event 层进行抽象。
- Address Lookup 用来定位消息应该发送给哪一个 Operator
Flink 作业不同的算子可能运行在不同的 TaskManager 中,Address Lookup 层负责定位对应的 task 算子。
- 所有的 Event 最终都会通过 RPC Gateway,RPC 调用的方式进行网络传输
2.1.2. 数据读取器设计
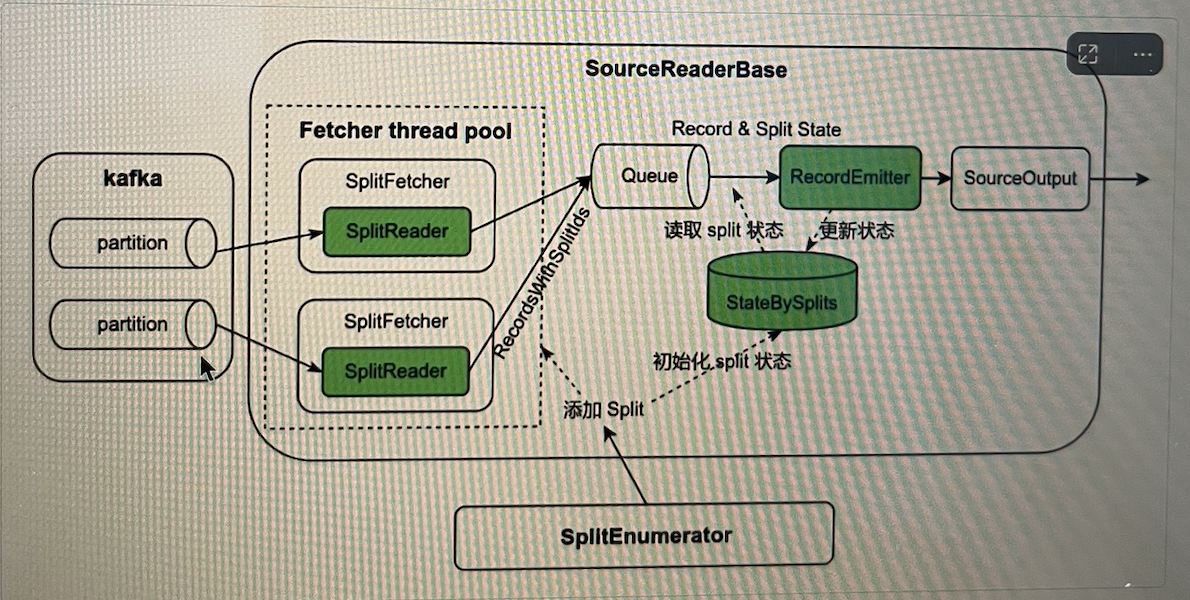
SplitEnumerator 将新的分片添加到 SourceReader,SourceReader 首先初始化分片状态并放入状态哈希表中,然后分片被分配给 SplitReader 读取数据。读取的数据以小批量模式封装于 RecordsWithSplitids 并放置于中间队列 Queue。 SourceReader 从 Queue 中读取一批数据,并遍历批次中每一条数据,查找数据相应的分片状态,数据和分片状态并传递给 RecordEmitter,RecoroEmitter 先把数据传递给 SourceOutput,然后更新分片状态。哈希表中的状态在 checkpoint 时持久化到状态存储。
三、实现
3.1. KafkaSource
 微信
微信 支付宝
支付宝