Flink-源码学习-API-Connector 体系
一、概述
Flink 做为新一代流批统一的计算引擎,程序主要由三部分组成: Source、Transformation 和 Sink。 Source 从不同的第三方存储引擎中把读取数据,利用各种算子进行处理加工 (transform),然后再输出到另外的存储引擎中(Sink),在运行时,Flink 上运行的程序会被映射成 “逻辑数据流”(Dataflows),每一个 Dataflow 以一个或多个 Sources 开始以一个或多个 Sinks 结束。
Connector (包括: Source 和 Sink) 的作用就相当于一个连接器,连接 Flink 计算引擎跟外界存储系统。为了使 Flink 能够访问外部数据源,Flink 内置了大量的 Connector,也提供了自定义 Connector 机制,目前 Connector 接口分为DataStream/DataSet/Table API 三个不同的栈。
Table API 是基于前两者的封装。
二、DataSet/Stream Connector
2.1. Source
2.1.1. 设计
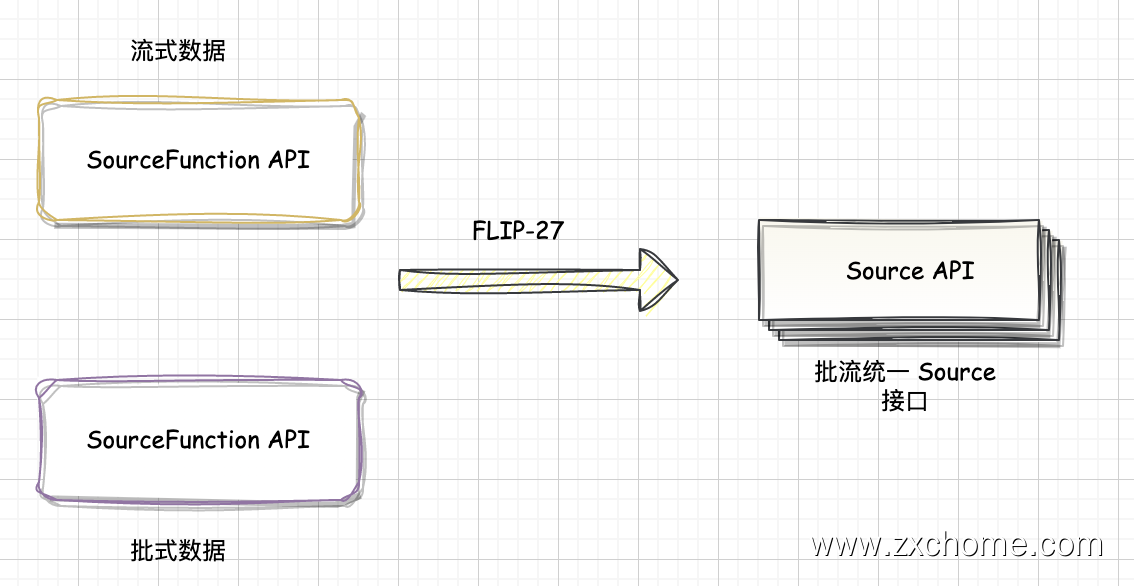
在早期版本中,Flink Connector Source 的架构设计相对简单,主要使用 InputFormat 和 SourceFunction 等组件来读取外部数据源,并将数据转换为 Flink 内部数据格式。这种设计方式的优点是实现简单,但缺点是批流无法统一,读取性能较差,难以满足大规模数据处理的需求。
在 FLIP-27 重构了 Source 接口,核心是统一流批两种执行模式的 Source 架构。
2.1.2. 自定义 Source
Flink 提供了灵活的机制方便开发者开发新的 Connector。对于 Source connector 的开发,有基于传统的 SourceFunction 的方式和基于 Flink 改进计划 FLIP-27 的 Source 新架构的方式。
FLIP-27实现 FLIP-27 Source
https://blog.csdn.net/cloudbigdata/article/details/122406155
Split/SplitState
- Split: 外部系统分片
- SplitSerializer: 序列化/反序列化 Split 传递给 SourceReader
- SplitState: Split 状态,用于 Checkpoint 与恢复
SplitEnumerator
- 发现与订阅 Split
- EnumState: Enumerator 的状态,用于 Checkpoint 与恢复
- EnumStateSerializer: 序列化/反序列化 EnumState
SourceReader
- SplitReader: 与外部系统进行数据交互的接口
- FetcherManager: 选择线程模型
- RecordEmiter: 转换消息类型与处理事件时间
2.2. Sink
2.2.1. 设计
2.2.2. 自定义 Sink
通过实现 SinkFunction 接口可以自定义 Sink。 SinkFunction 中 $invoke$ 方法用于数据输出,每条记录都会执行 $invoke$ 方法一次。
- KafkaSink
三、Table Connector
3.1. 设计
Flink 为 Table API 和 SQL 设计了 Table Connector 体系,包括 Table Source 和 Table Sink, 满足 Table API 和 SQL 对数据源访问的需求。
Table Connector 体系基于 DataSet/Stream Connector API,是对 DataSet/Stream Connector API 的封装。

3.2. 自定义
3.2.1. 举个栗子🌰~
 微信
微信 支付宝
支付宝