Spark-理论笔记-本地化执行引擎-Gluten-Backend-Arrow
一、概述
1.1. 什么是 Arrow?
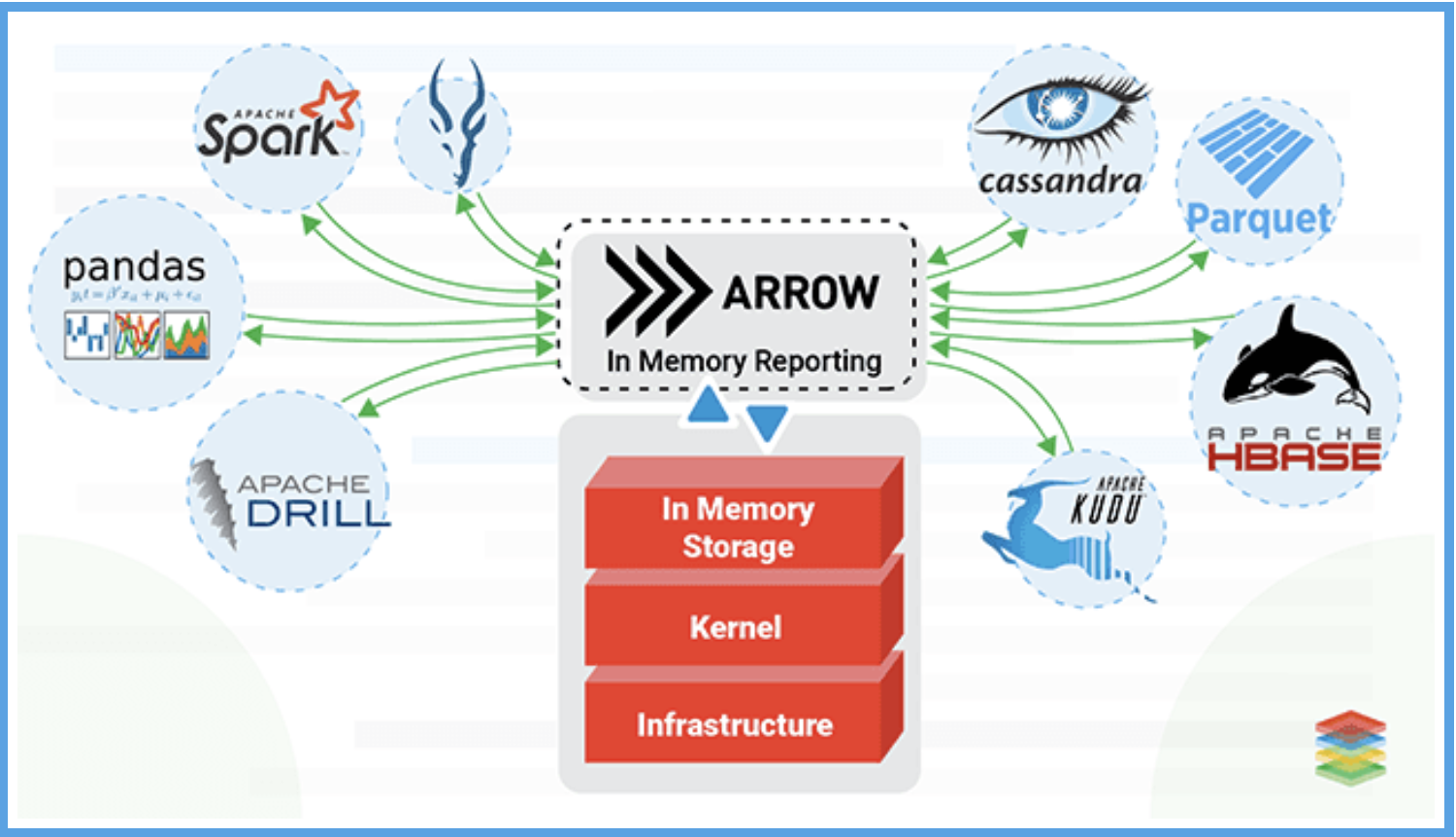
Apache Arrow 是 Apache 基金会近几年最活跃的项目之一,它基于内存列式格式彷生出了完善的内存计算生态,是当前内存列式数据格式事实上的标准。Arrow 的内存模型可以帮助编译器自动地实现向量化,且在传输时没有序列化/反序列化成本,实现了 CPU 和 IO 的效率提升。
在 Arrow 之前,任何应用程序或库之间交换数据的标准方式是以一种或另一种方式将其存储到磁盘。
如果 NET Core 库想要将数据传递给 Python 进行数据分析,很可能有人会将数据写入文件(例如 csv、json、Parquet 等),然后用 Python 再次读取它。写入(序列化)和读取(反序列化)这两个步骡都是昂贵且缓慢的,数据集越大,完成每个步骤所需的时间就越长。
是否存在一种通过握手和零复制直接交换数据的方式呢?🤔️
举个栗子: NET 将开始与 Python 聊天,指向内存中的一堆数据,然后就像:嘿,伙计,这堆东西现在是你的了。然后Python 就可以直接访问这个数据,而不用把宅从二个地方拖到另一个地方(例如先写入再读出)。那岂不是很棒😄,而这,就是 Apache Arrow 的意义所在!
1.2. 生态
除了 Arrow 本身的数据结构外,Arrow 项目还围绕这种数据协议搭建了一整套完善的生态,包括:
Compute: 原生的向量化计算引擎,支持数值计算、数组计算、聚合计算等各种常见的计算函数
Gandiva: 基于 LLVM JIT 的表达式计算库,在数值计算上可以得到明显加速效果
Datafusion: Rust 原生的 SQL 查询引擎
Flight: 用于传输 Arrow 数据的 RPC 框架
第三方文件格式支持: 如 JSON、 CSV、 Apache Parquet Apache ORC 等等协议与 Arrow 之间的转换
大数据表支持: 除了 Array 外,Arrow 还提供了 RecordBatch 二维数据表、Dataset 数据集的类型
二、Spark Arrow
三、总结
3.1. refer
 微信
微信 支付宝
支付宝