Spark-源码学习-集群启动-standalone-选举机制
一、概述
领导选举机制(Leader Election)可以保证集群虽然存在多个 Master,但是只有一个 Master 处于激活(Active)状态,其他的 Master 处于支持(Standby)状态。当 Active 状态的 Master 出现故障时,会选举出一个 Standby 状态的 Master 作为新的 Active 状态的 Master。由于整个集群的 Worker, Driver 和 Application 的信息都已经通过持久化引擎持久化,因此切换 Master 时只会影响新任务的提交,对于正在运行中的任务没有任何影响。
二、LeaderElectionAgent
特质 LeaderElectionAgent 定义了对当前的 Master 进行跟踪和领导选举代理的通用接口。
1 | trait LeaderElectionAgent { |
2.1. 属性
2.1.1. masterInstance
masterInstance 属性类型是 LeaderElectable
1 | trait LeaderElectable { |
LeaderElectable 定义了两个方法。
- $electedLeader()$: 被选举为领导。
- $revokedLeadership()$: 撤销领导关系。
LeaderElectable 目前只有 Master 这一个实现类
2.2. 实现
LeaderElectionAgent 一共有三种实现。由于 CustomLeaderElectionAgent 用于单元测试

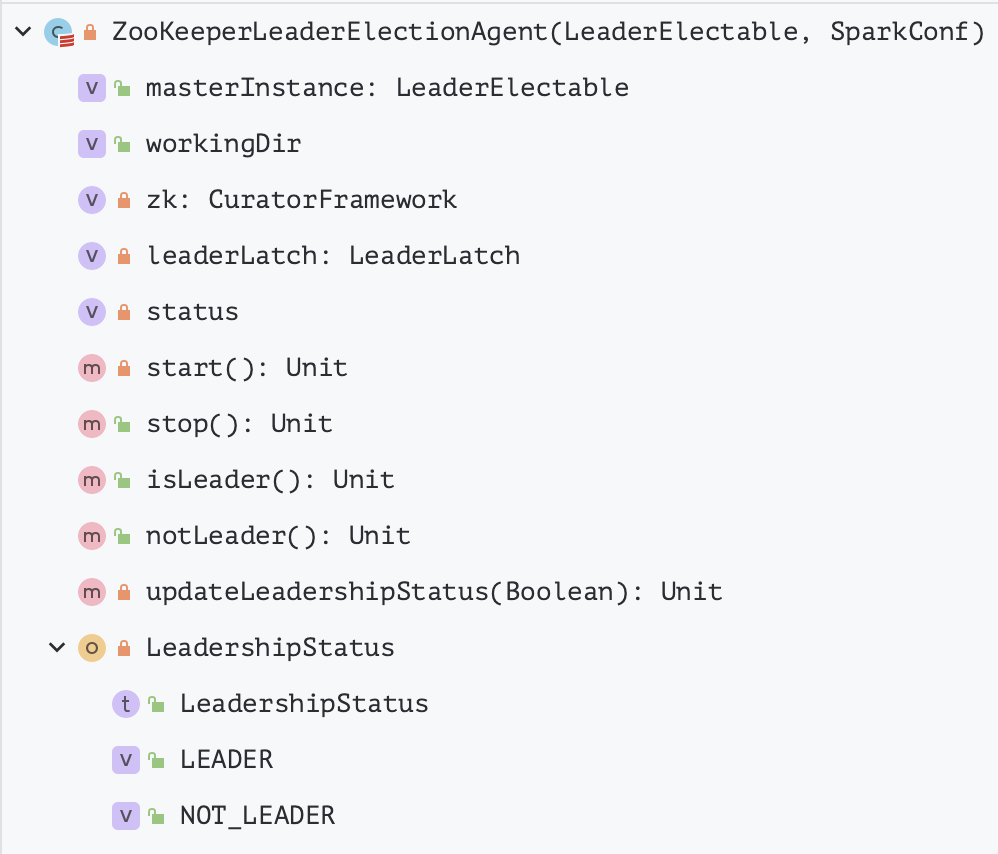
2.2.1. ZooKeeperLeaderElectionAgent
ZooKeeperLeaderElectionAgent 是借助 ZooKeeper 实现的领导选举代理,采用 ZooKeeper 作 HA, ZooKeeper 会自动化管理 Masters 的切换, ZooKeeper 会保存整个 Spark 集群运行时的元数据, 包括 Workers、Drivers、Applications、Executors。
ZooKeeper 遇到当前 Active 级别的 Master 出现故障时会从 Standby Masters 中选取出一台作为 Active Master, 但是要注意, 被选举后到成为真正的 Active Master 之前需要从 ZooKeeper 中获取集群当前运行状态的元数据信息并进行恢复。
在 Master 切换的过程中, 所有已经在运行的程序皆正常运行。因为 Spark Application 在运行前就已经通过 Cluster Manager 获得了计算资源, 所以在运行时,Job 本身的调度和处理和 Master 是没有任何关系的。
在 Master 的切换过程中唯一的影响是不能提交新的 Job:
- 一方面不能够提交新的应用程序给集群, 因为只有 Active Master 才能接收新的程序提交请求
- 已经运行的程序中也不能因为 Action 操作触发新的 Job 提交请求。
属性
WORKING_DIR: ZooKeeperLeaderElectionAgent 在 ZooKeeper 上的工作目录,是 Spark 基于 ZooKeeper 进行热备的根节点(可通过 spark.deploy.zooKeeper.dir 属性配置,默认为 spark)的子节点 leader_election
zk: 连接 ZooKeeper 的客户端,类型为 CuratorFramework
leaderLatch: 使用 ZooKeeper 进行领导选举的客户端,类型为 LeaderLatch
status: 领导选举的状态,包括有领导 (LEADER) 和无领导 (NOT_LEADER)
方法
$start()$: 启动基于 ZooKeeper 的领导选举代理
1
2
3
4
5
6private def start() {
zk = SparkCuratorUtil.newClient(conf)
leaderLatch = new LeaderLatch(zk, WORKING_DIR)
leaderLatch.addListener(this)
leaderLatch.start()
}ZooKeeperLeaderElectionAgent 实现了 LeaderLatchListener,因此发生领导选举后,LeaderLatch 会回调 ZooKeeperLeaderElectionAgent 的 $isLeader$ 或 $notLeader$ 方法。
$updateLeadershipStatus()$: 更新领导关系状态
1
2
3
4
5
6
7
8
9private def updateLeadershipStatus(isLeader: Boolean) {
if (isLeader && status == LeadershipStatus.NOT_LEADER) { // 选举为领导
status = LeadershipStatus.LEADER
masterInstance.electedLeader()
} else if (! isLeader && status == LeadershipStatus.LEADER) {// 撤销领导职务
status = LeadershipStatus.NOT_LEADER
masterInstance.revokedLeadership()
}
}如果 Master 节点之前不是领导(NOT_LEADER),当被选为领导 Leader 时,将其状态设置为 LEADER 并调用 $masterInstance.electedLeader()$ 方法将Master 节点设置为 Leader。
1
2
3override def electedLeader(){
self.send(ElectedLeader)
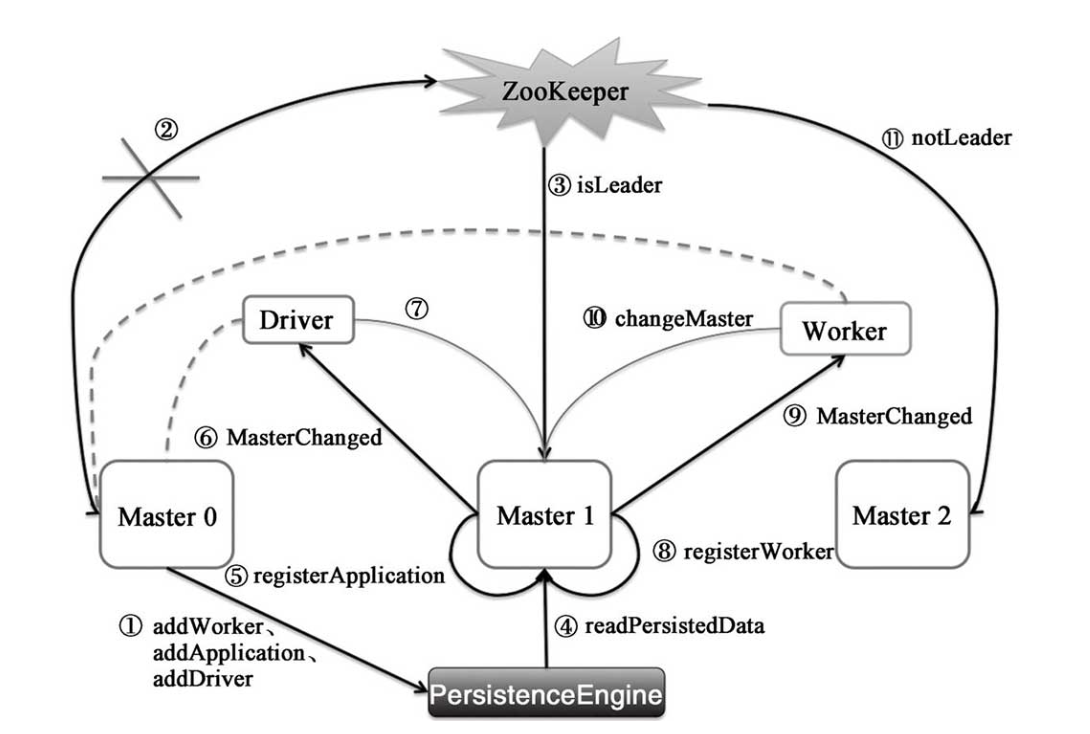
}Master的 $receive()$ 方法中实现了对 ElectedLeader 消息的处理, Master 处理 ElectedLeader 消息的步骤如下:
从持久化引擎 PersistenceEngine 中读取出持久化的 ApplicationInfo、DriverInfo、WorkerInfo 等信息。
1
val (storedApps, storedDrivers, storedWorkers) = persistenceEngine.readPersistedData(rpcEnv)
如果没有任何持久化信息,则将 Master 的当前状态设置为 ALIVE,否则将 Master 的当前状态设置为 RECOVERING
1
2
3
4
5state = if (storedApps.isEmpty && storedDrivers.isEmpty && storedWorkers.isEmpty) {
RecoveryState.ALIVE
} else {
RecoveryState.RECOVERING
}如果 Master 的当前状态为 RECOVERING, 则调用 $beginRecovery()$ 方法对整个集群的状态进行恢复。在集群状态恢复完成后,创建延时任务 recoveryCompletionTask, 在
WORKER_TIMEOUT_MS指定的时间后向 Master 自身发送CompleteRecovery消息。1
2
3
4
5
6
7
8if (state == RecoveryState.RECOVERING) {
beginRecovery(storedApps, storedDrivers, storedWorkers)
recoveryCompletionTask = forwardMessageThread.schedule(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CompleteRecovery)
}
}, workerTimeoutMs, TimeUnit.MILLISECONDS)
}集群的状态恢复: $beginRecovery()$

遍历从持久化引擎中读取 ApplicationInfo
调用 $registerApplication()$ 方法将 ApplicationInfo 添加到 apps、idToApp、endpointToApp、 addressToApp、waitingApps 等缓存中。
将 ApplicationInfo 的状态设置为 UNKNOWN
向提交应用程序的 Driver 发送 MasterChanged 消息(此消息将携带被选举为领导的 Master 和此 Master 的 masterWebUiUrl 属性)
Driver 接收到 MasterChanged 消息后,将自身的 master 属性修改为当前 Master 的 RpcEndpointRef, 并将 alreadyDisconnected 设置为 false, 最后向 Master 发送 MasterChangeAcknowledged 消息。Master 接收到 MasterChangeAcknowledged 消息后将 ApplicationInfo 的状态修改为 WAITING, 然后在不存在状态为 UNKNOWN 的 ApplicationInfo 和 WorkerInfo 时调用 completeRecovery() 方法完成恢复。
恢复 Driver
遍历从持久化引擎中读取的 DriverInfo, 将每个 DriverInfo 添加到 drivers 缓存
1
2
3for (driver <- storedDrivers) {
drivers += driver
}恢复 Worker
遍历从持久化引擎中读取的 WorkerInfo
1
2
3
4
5
6
7
8
9for (worker <- storedWorkers) {
try {
registerWorker(worker)
worker.state = WorkerState.UNKNOWN
worker.endpoint.send(MasterChanged(self, masterWebUiUrl))
} catch {
//...
}
}调用 $registerWorker()$ 方法将 WorkerInfo 添加到 workers、idToWorker、addressToWorker 等缓存中
将 WorkerInfo 的状态修改为 UNKNOWN
向 Worker 发送
MasterChanged消息(此消息将携带被选举为领导的 Master 和此 Master 的 masterWebUiUrl 属性)Worker 接收到 MasterChanged 消息后, 将自身的 activeMasterUrl、activeMasterWebUiUrl、master 等属性修改为当前 Master 的对应信息, 然后将 connected 设置为 true, 最后向 Master 发送
WorkerSchedulerStateResponse消息。Master 接收到
WorkerSchedulerStateResponse消息后, 首先将 WorkerInfo 的状态修改为 ALIVE, 然后对此 Worker 上的 Executor 和 Driver 也进行恢复, 最后在不存在状态为 UNKNOWN 的 ApplicationInfo 和 WorkerInfo 的调用 $completeRecovery()$ 方法完成恢复。- 如果 Master 的状态不是 RECOVERING, 直接返回。
- 将 Workers 中状态为 UNKNOWN 的所有 WorkerInfo, 通过调用 removeWorker 方法从 Master 中移除
- 将 apps 中状态为 UNKNOWN 的所有 ApplicationInfo,通过调用 $finishApplication()$ 方法从 Master 中移除
- 从 drivers 中过滤出还没有分配 Worker 的所有 DriverInfo, 如果 Driver 是被监管的,则调用 $relaunchDriver()$ 方法重新调度运行指定的 Driver, 否则调用 $removeDriver()$ 方法移除 Master 维护的关于指定 Driver 的相关信息和状态。
- 将 Master 的状态设置为 ALIVE
- 调用 $schedule()$ 方法进行资源调度
向 Master 自身发送
CompleteRecovery消息处理
CompleteRecovery消息: $completeRecovery()$
如果 Master 节点之前 LEADER,当没有被选为 Leader 时,将其状态设置为 NOT_LEADER 并调用 $masterInstance.revokedLeadership()$ 方法撤销 Master 节点的领导关系。
$isLeader()$
ZooKeeperLeaderElectionAgent 所属的 Master 节点被选为 Leader,会调用 ZooKeeperLeaderElectionAgent 的 $isLeader()$ 方法
LeaderLatch 通过在 Master 上创建领导选举的 Znode 节点,并对 Znode 节点添加监视点来发现 Master 是否成功竞选
- $notLeader()$
ZooKeeperLeaderElectionAgent 所属的 Master 节点没有被选为 Leader,并更新领导关系状态。当 LeaderLatch 发现 Master 没有被选举为 Leader,会调用 ZooKeeperLeaderElectionAgent 的 $notLeader()$ 方法
2.2.2. MonarchyLeaderAgent
MonarchyLeaderAgent 在构造时会调用 masterInstance 的 electedLeader 方法选举领导
2.2.3. CustomLeaderElectionAgent
用于单元测试
三、总结
 微信
微信 支付宝
支付宝