Spark-源码学习-集群启动系列
一、Spark 集群架构
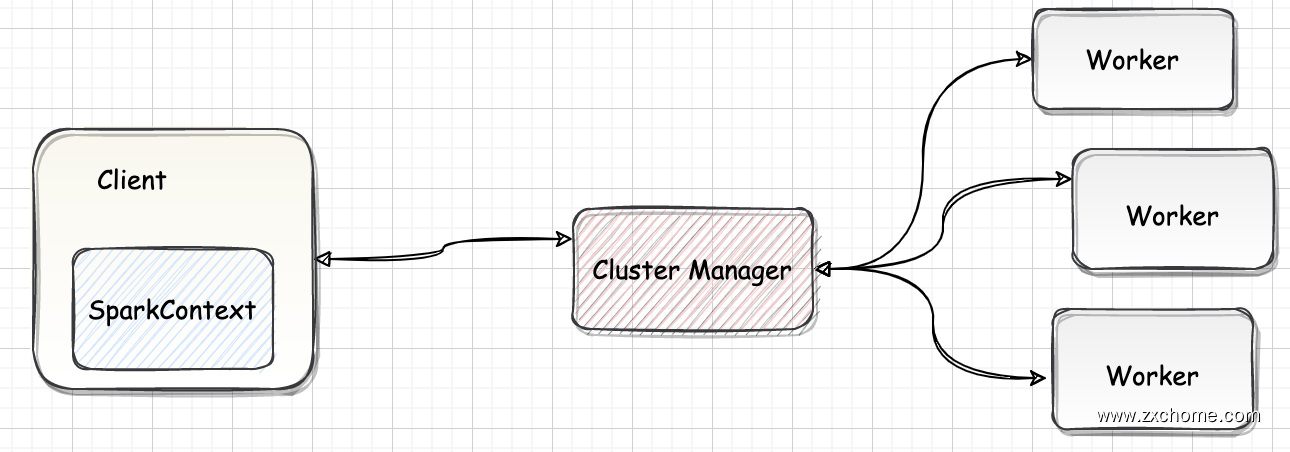
1.1. ClusterManager
Cluster Manager 负责集群的资源管理和调度。目前 Spark 支持4种 Cluster Manager
Standalone
Spark 自带的集群管理模式, Master
Apaehe MesosMesos 是一种通用的集群资源管理服务,用于管理 MapReduce 应用或者其他类型的应用。Hadoop YARN
YARN 是由 Hadoop 2.0 引入的集群资源管理服务。
Kubernetes
Kubernetes 是一种管理 containerized 的应用的服务。Spark 2.3以后引入了对Kubernetes的支持
1.2. Worker
Worker Node 是集群中可以执行计算任务的节点。在 YARN 部署模式下实际由 NodeManager 替代。
Worker 节点主要负责以下工作
- 将自己的内存、CPU 等资源通过注册机制告知 Cluster Manager
- 创建 Executor,将资源和任务进一步分配给 Executor
二、部署模式
Spark 应用程序在集群上部署运行时,可以由不同的 Cluster Manager 为其提供资源管理调度服务(资源包括CPU、内存等)。比如: 可以使用自带的独立集群管理器(standalone),或者使用 YARN、Kubernetes 以及 Mesos。
2.1. Standalone
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能。Master 是一个进程,负责资源的调度和分配,并进行集群的监控等职责;Worker 也是一个进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行处理和计算。
2.2. Yarn
Spark on yarn 的支持两种模式: cluster&client
Yarn-cluster 和 Yarn-client 模式的区别其实就是 AppMaster 进程的区别
Yarn-cluster 模式下,driver 运行在 AppMaster 中,它负责向 Yarn 申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉 Client,作业会继续在 Yarn 上运行。然而 Yarn-cluster 模式不适合运行交互类型的作业。
而 Yarn-client 模式下,AppMaster 仅仅向 Yarn 请求 executor,client 会和请求的 container 通信来调度他们工作。
2.2.1. Cluster
2.2.2. Client
2.3. Kubernetes
 微信
微信 支付宝
支付宝