
Spark-源码学习-SparkSQL-Join 体系-SortMergeJoinExec
一、概述
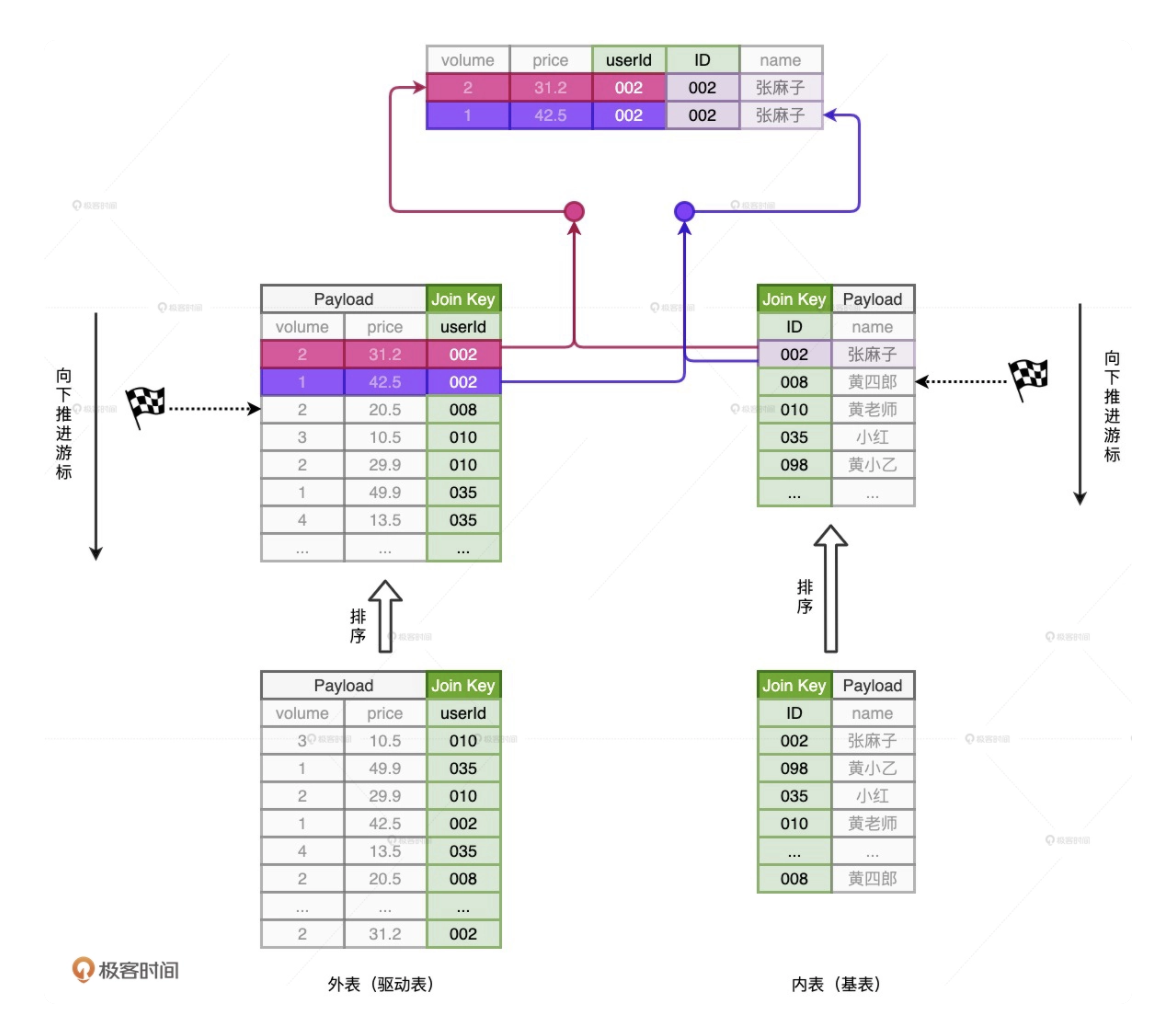
SMJ 的思路是先排序、再归并,参与 Join 的两张表先分别按照 Join Key 做升序排序。然后,SMJ 会使用两个独立的游标对排好序的两张表完成归并关联。
SMJ 刚开始工作的时候,内外表的游标都会先锚定在两张表的第一条记录上,然后再对比游标所在记录的 Join Key。对比结果以及后续操作主要分为 3 种情况
- 外表 Join Key 等于内表 Join Key,满足关联条件,把两边的数据记录拼接并输出,然后把外表的游标滑动到下一条记录外表
- 外表 Join Key 小于内表 Join Key,不满足关联条件,把外表的游标滑动到下一条记录外表
- 外表 Join Key 大于内表 Join Key,不满足关联条件,把内表的游标滑动到下一条记录
SMJ 基于这 3 种情况,不停地向下滑动游标,直到某张表的游标滑到头,即关联结束。对于 SMJ 中外表的每一条记录,由于内表按 Join Key 升序排序,且扫描的起始位置为游标所在位置,因此 SMJ 算法的计算复杂度: $O(M + N)$

SMJ 计算复杂度的降低的前提是两张表预先排序,排序是一项非常耗时的操作,为了完成归并关联,参与 Join 的两张表都需要排序。
二、实现
2.1. SortMergeJoinExec
2.2. SortMergeJoinScanner
SortMergeJoinScanner 是查找匹配数据的核心类。
在 SortMergeJoinScanner 的构造参数中会传递 streamedTable 的迭代器(streamedIter) 和 bufferedTable 的迭代器(bufferedIter), 考虑到 streamedTable 与 bufferedTable 都是已经排好序的, 因此在匹配满足条件数据的过程中只 需要不断移动迭代器 , 得到新的数据行进行比较即可。 在 SortMerge JoinScanner 中,两个表迭代 器所指向的数据行分别用 streamedRow 和 bufferedRow 表示。 数据行对应的 Join 操作的 key 分别 为 streamedRowKey 与 bufferedRowK町, 这些对象都属于 InternalRow 类型。

2.2.1. 实现

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Joker!
 微信
微信 支付宝
支付宝
相关推荐



评论
ValineTwikoo





