
Spark-源码学习-SparkSQL-Join 体系
一、概述
在面对多表数据分析的需求时,必须将多个分散的数据表关联起来进行 Join 操作。 目前 Spark SQL 中支持的 Join 类型主要包括 Inner、 FullOuter、 LeftOuter、 RightOuter、LeftSemi、 LeftAnti 和 Cross 共7种。

二、文法定义
在 Spark SQL 的 ANTLR4 文法文件中,与 Join 相关的文法定义如下:
1 | fromClause |
在 FROM 关键字表示的数据源中,至少包含一个或多个 $relation$, 以及可能的 $lateralView$。每个 $relation$ 包含一个主要数据表 $relationPrimary$ 和零个或多个参与 Join 操作的数据表 $joinRelation$。
在 $joinRelation$ 中,除参与 Join 的数据表外,还包括 Join 类型 ($joinType$) 和 Join 条件 ($joinCriteria$)。

Join 方式
目前,Spark SQL 中支持的 Join 类型主要包括 Inner、 FullOuter、 LeftOuter、 RightOuter、LeftSemi、 LeftAnti 和 Cross 共 7 种。JoinType 实现为抽象类,里面定义了返回 Join 类型字符串的函数。
Join 条件
从文法定义中可以看到,joinCriteria 有 ON 和 USING 关键字两种写法。
三、AST
SQL 栗子:
1 | select name, score from student join exam on student.id = exam.studentId |
经过 ANTLR 4 编译器的处理,该查询语句会生成图所示的抽象语法树。类似常见的查询语句,QuerySpecifcationContext 节点的子节点 NamedExpressionSeqContext 对应 Select 语句中所选择的列,图中的两个 NamedExpressionContext 子节点分别代表 name 和 score 列。
对于 Join 查询,图中的第一个 TableNameContext 子节点对应文法定义中的 relationPrimary,即 student 数据表;第二个 TableNameContext 子节点对应 exam 数据表,在 JoinRelationContext 节点下还包含对应 Join 类型的 JoinTypeContext 子节点和对应 Join 条件的 JoinCriteriaContext 子节点。
实际上,在上述语法树对应的数据结构中,FromClauseContext 节点下包含的是 RelationContext 列表,列表中每个 RelationContext 又包含 JoinRelationContext 列表。

JoinCriteriaContext 子节点本质上是一个表示 True 和 False 谓词逻辑的表达式节点(BooleanDefaultContext)。JoinCriteriaContext 子节点内容展开如图所示:

在本例中,该表达式的左、右子表达式分别为 student.id 和 exam.studentId,这两个表达式都设置了数据表名,属于 DereferenceContext 类型。ComparisonOperatorContext 节点对应列之间的相等关系。
四、Join 逻辑计划
逻辑计划阶段的开始由 AstBuilder 将抽象语法树 AST 生成 Unresolved LogicalPlan,然后在此基础上经过解析得到 Analyzed LogicalPlan,最后经过优化得到 Optimized LogicalPlan。
五、Join 物理计划
5.1. 物理计划生成
从逻辑计划到物理计划的生成是基于 Strategy 进行的,逻辑算子树将应用 3 个策略: 文件数据源(FileSource)策略、 Join 选择(JoinSelection)策略和基本算子( BasicOperators)策略。
结合 Shuffle、广播这两种网络分发方式和 NLJ、SMJ、HJ 这 3 种计算方式,对于分布式环境下的数据关联,就能组合出 6 种 Join 策略,从执行性能来说,6 种策略中,CPJ 的执行效率是所有实现方式当中最差的,网络开销、计算开销都很大。BHJ 是最好的分布式数据关联机制,网络开销和计算开销都是最小的。
Spark 并没有选择支持 Broadcast + Sort Merge Join 这种组合方式。当数据能以广播的形式在网络中进行分发时,说明被分发的数据,也就是基表的数据足够小,完全可以放到内存中去。这个时候,相比 NLJ、SMJ,HJ 的执行效率是最高的。因此,在可以采用 HJ 的情况下,Spark 自然就没有必要再去用 SMJ 这种前置开销比较大的方式去完成数据关联。

5.2. 物理计划选取
在生成物理计划的过程中,JoinSelection 根据若干条件判断采用何种类型的 Join 执行方式。 目前在 Spark SQL 中, Join 的执行方式主要有 BroadcastHashJoinExec (BHJ)、 ShuffledHashJoinExec (SHJ)、SortMergeJoinExec (SMJ)、BroadcastNestedLoopJoinExec (BNLJ) 和 CartesianProductExec (CPJ) 这 5 种。
六、Join 执行
6.1. 执行基本框架
在 Spark SQL 中, Join 的实现都基于一个基本的流程, 根据角色的不同,参与 Join 操作的两张表分别被称为”流式表”(StreamTable) 和 “构建表”( BuildTable),不同表的角色在 Spark SQL 中会通过一定的策略进行设定。 通常来讲,系统会默认将大表设定为流式表,将小表设定为构建表。
6.1.1. Build
流式表的迭代器为 streamedIter,构建表的迭代器为 buildIter,遍历 streamedIter 中每条记录,然后在 buildIter 中查找相匹配的记录。 这个查找过程称为 Build 过程。
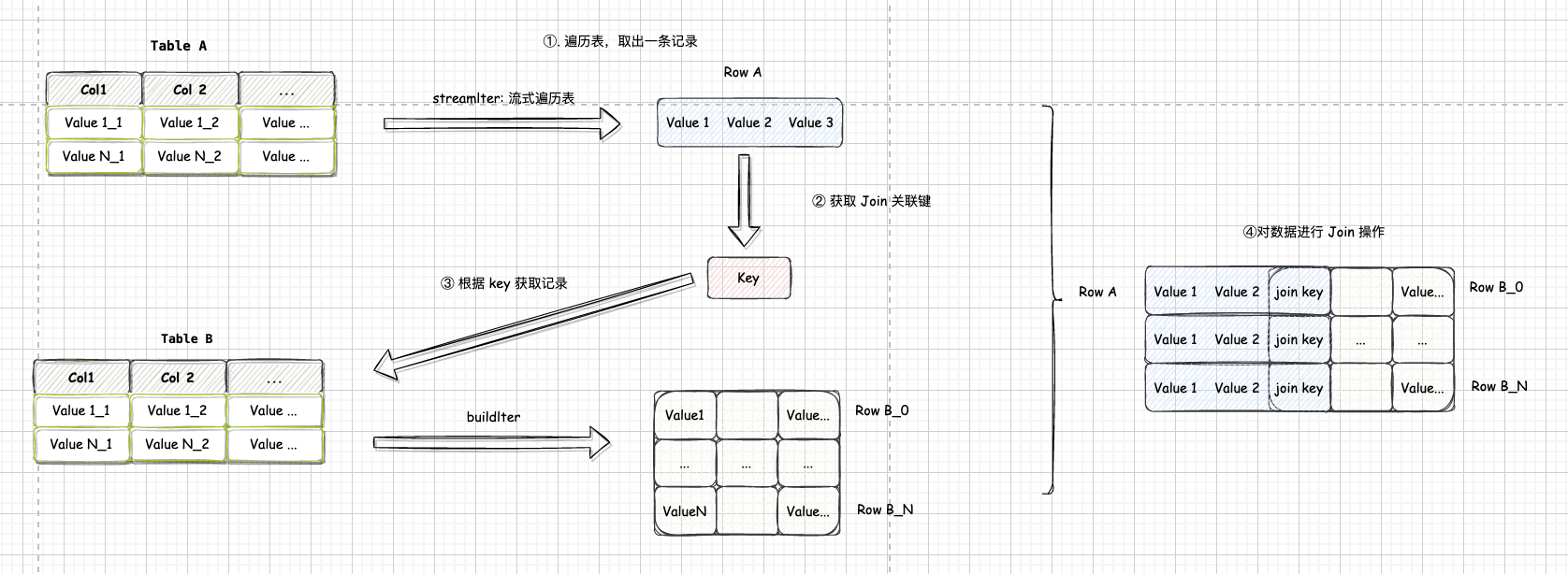
每次 Build 操作的结果为一条 JoinedRow(A, B),其中 A 来自 streamedIter, B 来自 buildIter,这 个过程为 BuildRight 操作;而如果 B 来自 streamedIter , A 来自 buildIter,则为 BuildLeft 操作。
对于 LeftOuter、 RightOuter、 LefSemi 和 LeftAnti,它们的 Build 类型是确定的:
- LeftOuter、LeftSemi、 LeftAnti 为 BuildRight
- RightOuter 为 Buildleft 类型。
对于 Inner 来说, BuildLeft 和 BuildRight 两种都可以,选择不同,可能有着很大的性能区别。
 微信
微信 支付宝
支付宝








