
Spark-源码学习-SparkSQL 系列-代码生成
一、概述
SparkSQL 的优越性能背后有两大技术支柱: Optimizer 和 Runtime。前者致力于寻找最优的执行计划,后者则致力于把既定的执行计划尽可能快地执行出来。Runtime 的多种优化可概括为两个层面:
全局优化
从提升全局资源利用率、消除数据倾斜、降低 IO 等角度做优化,包括自适应执行 (Adaptive Execution), Shuffle Removal 等。
局部优化
优化具体的 Task 的执行效率,主要依赖 Codegen 技术,具体包括 Expression 级别和 WholeStage 级别的 Codegen。
1.1. Volcano 模式
1.1.1. 概述
在 Apache Spark 2.0 之前,Spark SQL 的底层实现基于火山模型 $Volcano\ Iterator\ Model$ 。 Volcano 模型的执行可以概括为: 数据库引擎会将 SQL 翻译成一系列的关系代数算子或表达式 Operator/Expression,然后依赖这些关系代数算子 Operator 逐条处理输入数据并产生结果。
每个算子 Operator 在底层都实现同样的接口,比如 $next$ 方法,Volcano 模式中每个算子 Operator 不断地迭代调用 $next$ 函数,直到最底层算子的 $next$ 来读入数据,经过表达式处理后输出一个数据元组的流(Tuple stream)。
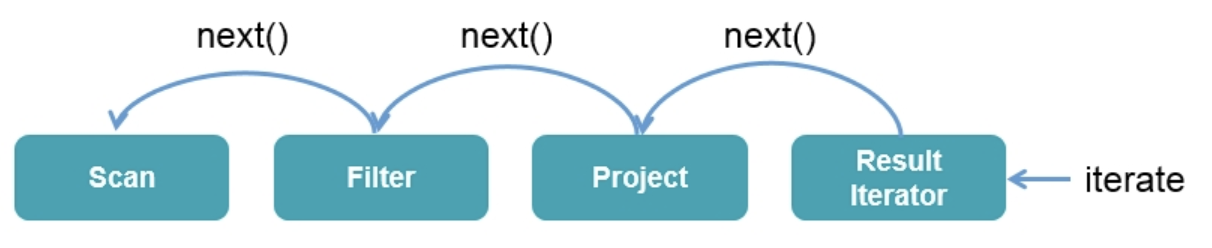
Volcano 模式可以通过任意组合算子来表达复杂的查询,可以让查询引擎优雅的组装任意 Operator 在一起。而不需要查询引擎去考虑每个 Operator 具体的一些处理逻辑,比如数据类型等。Volcano 模型也因此成为数据库 SQL 执行引擎领域内最流行的一种标准。而且 Spark SQL 最初的 SQL 执行引擎也是基于这个思想来实现的。
1.1.2. Volcano vs 手写代码
手写的代码的性能比 Volcano Iterator Model 高了一整个数量级,而这其中的原因包含以下几点:
避免了虚函数调用 Virtual Function Dispatch
在火山模型中,至少需要调用一次 $next()$ 函数来获取下一个 Operator。这些函数调用在操作系统层面,会被编译为 virtual function dispatch。而手写代码中,没有任何的函数调用逻辑。
通过 CPU Register 存取中间数据,而不是内存缓冲
在火山模型中,每次一个 Operator 将数据交给下一个 Operator,都需要将数据写入内存缓冲中。然而在手写代码中,JVM JIT 编译器会将这些数据写入 CPU Register。CPU 从内存缓冲种读写数据的性能比直接从 CPU Register 中读写数据,要低了一个数量级。
Loop Unrolling 和 SIMD
现代的编译器和 CPU 在编译和执行简单的 for 循环时,性能非常地高。编译器通常可以自动对 for 循环进行 unrolling,并且还会生成 SIMD 指令以在每次 CPU指令执行时处理多条数据。CPU 也包含一些特性,比如 pipelining,prefetching,指令 reordering,可以让 for 循环的执行性能更高。然而这些优化特性都无法在复杂的函数调用场景中施展,比如 Volcano Iterator Model。
1.2. 全阶段代码生成 WSCG
从 Apache Spark 2.0 开始,社区开始引入了全阶段代码生成 WSCG ($whole\ stage\ code\ generatior$),全阶段代码生成检测到物理算子树中有多个连续的可以进行代码生成的物理计划节点后。对这多个连续的物理计划节点一次性进行代码生成,将多个物理计划节点的代码生成放在一个类中。利用这个类一次性的完成多个物理计划节点的逻辑操作。
举个栗子🌰:
1 | select count(*) from store_sales where ss_item_sk = 1000 |
Spark 会自动生成以下代码。

如果只是一个简单的查询,那么 Spark 会尽可能就生成一个 stage,并且将所有操作打包到一起。但是如果是复杂的操作,就可能会生成多个 stage。
1.3. Vectorization
对于很多查询操作,WSCG 技术都可以很好地优化其性能。但是有一些特殊的操作,却无法很好的使用该技术,如: Parquet 文件扫描、csv 文件解析等,或者是跟其他第三方技术进行整合。
为了在上述场景提升性能,Spark 引入另外一种技术,称作 向量化 $Vectorization$。向量化避免每次仅仅处理一条数据,将多条数据通过面向列的方式来组织成一个 batch,然后对一个 batch 中的数据来迭代处理。每次 $next$ 函数调用都返回一个 batch 的数据,以减少虚函数调用的开销。同时通过循环的方式来处理,也可以使用编泽器和 CPU 的 Loop unrolling 等优化特性。
CPU 密集型的操作,可以通过 WSCG、 Vectorization 这些新技术得到性能的大幅度提升,但是很多 IO 密集型的操作,比如 shuffle 过程的读写磁盘,是无法通过该技术提升性能的。在未来,Spark 会花费更多的精力在优化 IO 密集型的操作的性能上。
二、Spark 代码生成实现
Spark 代码生成分为两部分: 表达式代码生成以及全阶段代码生成,用来将多个处理逻辑整合到单个代码模块中。代码生成的实现中 CodegenContext 可以算是最重要的类,CodegenContext 作为代码生成的上下文,记录了将要生成的代码中的各种元素,包括变量、函数等。
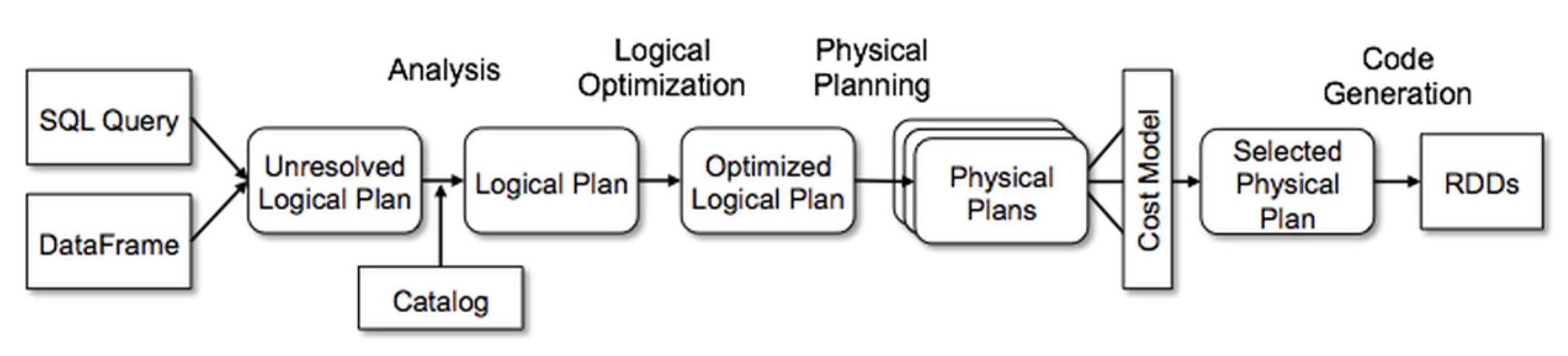
Spark Codegen 包含 Expression 和 WholeStage 两个级别
2.1. 表达式代码生成
表达式代码生成是将一个物理计划节点中的表达式进行代码生成,转换成一个类。利用这个生成的类完成物理节点的逻辑操作。
表达式生成完整的类代码只有在将 spark.sql.codegen.wholeStage 设置为 false 才会进行的,否则只会生成一部分代码,并且和其他代码组成 Whole-stage Code。
2.1.1. CodeGenerator
表达式代码生成的基类是 CodeGenerator
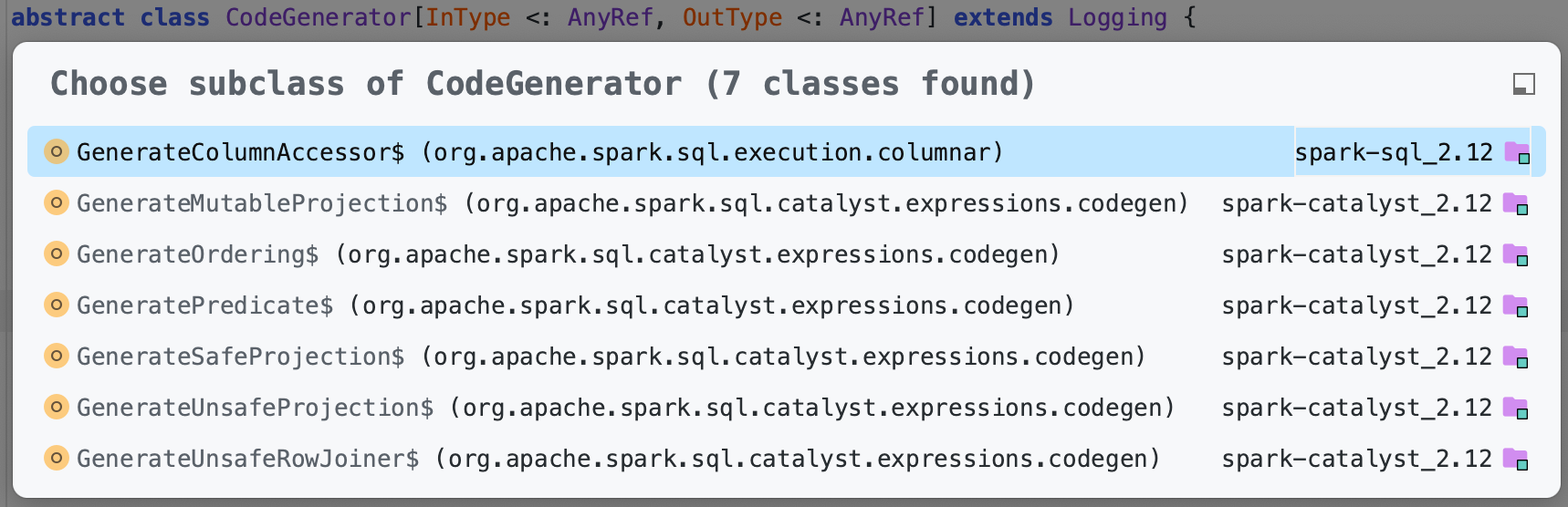
- GenerateUnsafeProjection
- GenerateSafeProjection
2.1.2. 流程
- SQL 在经过 Antlr4 后会被解析为 AST 树结构,经过逻辑计划阶段转换为逻辑表达式。经过物理执行阶段逻辑表达式会转换为物理执行节点。
- 在运行时会调用物理执行节点的 $doExecute$ 方法来执行其对应的逻辑。在物理执行的 $doExecute$ 方法方法中则会通过调用工厂方法,来触发 CodeGenerator的不同子类。
- 通过调用到 CodeGenerator 子类对象的 $generate$ 方法来动态编译生成预定义的 “手写” 代码,完成 Java 版本
2.1.3. 举个栗子 ProjectExec 🌰~
SQL 在经过 Antlr4 后会被解析为 AST 树结构,在逻辑计划阶段转换为 Project 的表达式。在物理执行阶段 Project 表达式会转换为 ProjectExec 物理执行的节点。
在运行时会调用 $ProjectExec.doExecute$ 方法执行 Project 的逻辑。在 $ProjectExec.doExecute$ 方法方法中则会通过调用 $UnsafeProjection.create()$ 方法。
通过工厂接口其最终会调用到 GenerateUnsafeProjection 对象的 $generate$ 方法来生成预定义的”手写”代码 UnsafeProjection 类,完成 Java 版本的投影算子的逻辑。
2.2. 全阶段代码生成 WholeStageCodegen
全阶段代码生成(Whole-stage Code Generation),用来将多个处理逻辑整合到单个代码模块中,其中也会用到表达式代码生成。
和表达式代码生成不一样,全阶段代码生成是对整个 SQL 过程进行代码生成,表达式代码生成仅对于表达式的。
2.2.1. CodegenSupport 接口
CodegenSupport 接口代表支持代码生成的物理节点。CodegenSupport 本身也是 SparkPlan 的子类。
2.2.2. CollapseCodegenStages 规则
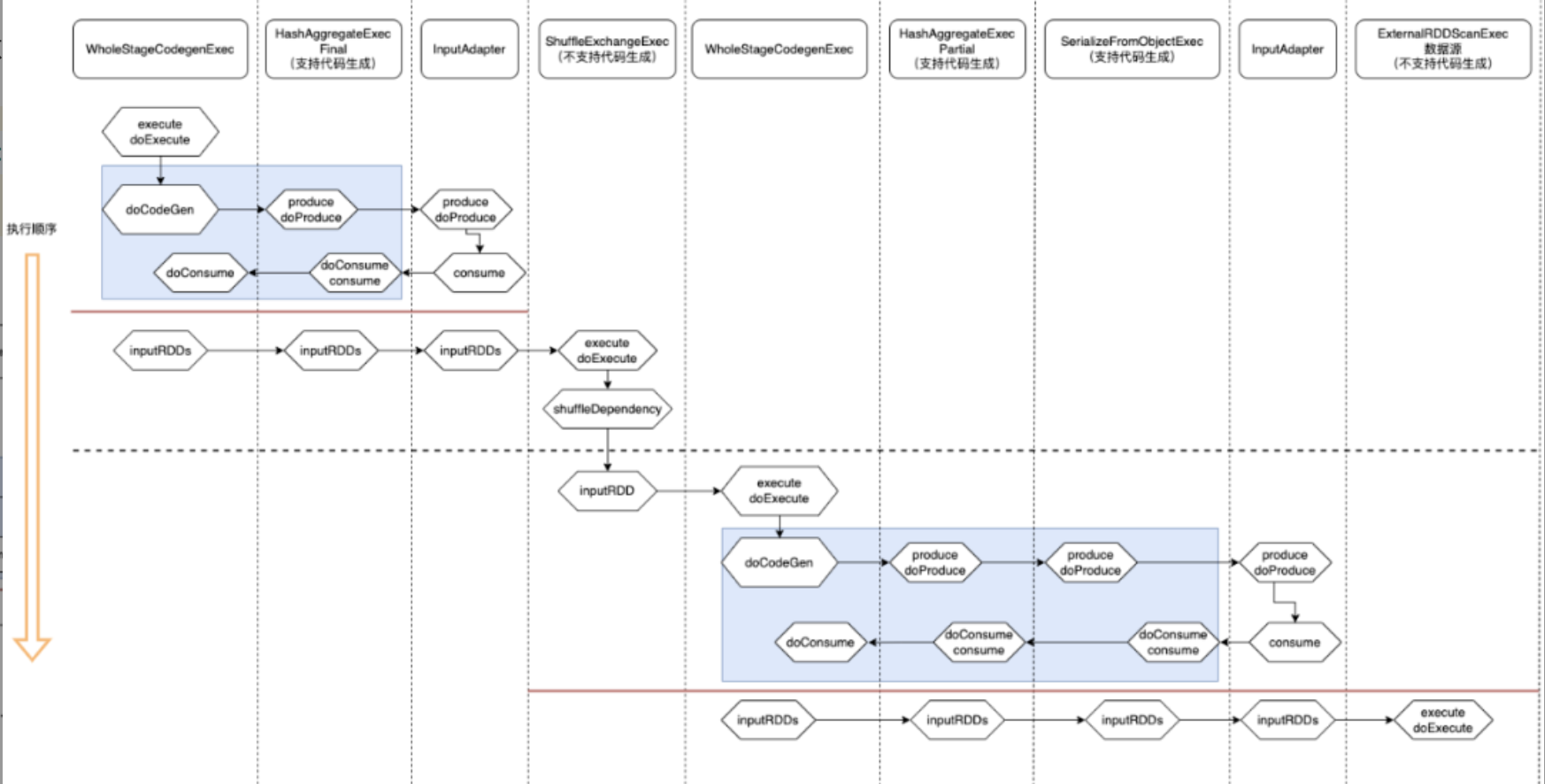
Catalyst 全阶段代码生成的入口是 CollapseCodegenStages 规则,CollapseCodegenStages 规则的执行逻辑是对物理执行计划树进行递归添加 WholeStageCodegenExec 和 InputAdapter 节点。
1 | def apply(plan: SparkPlan): SparkPlan = { |
2.2.3. WholeStageCodegenExec
WholeStageCodegenExec 是全阶段代码生成的实现类,用来将多个处理逻辑整合到单个代码模块中,然后将SQL中的逻辑表达式转换成 Java 函数,其也是 SparkPlan,所以主逻辑在 $execute()$ 方法中。具体可以分为:代码生成、代码编译和数据获取
三、总结
3.1. 参考
 微信
微信 支付宝
支付宝








