
Spark-源码学习-统计信息 Statistics 设计
一、概述
Spark 统计信息不仅对了解数据质量非常有用,对使用 Spark SQL 进行查询也能得到优化,进一步提升速度。统计信息是通过执行计划树的叶子节点计算的,然后从树的最底层往上传递,同时 Spark 也会利用这些统计信息来修改执行树的执行过程。
https://www.cnblogs.com/starqiu/p/12132539.html
https://blog.51cto.com/u_15127525/2686187
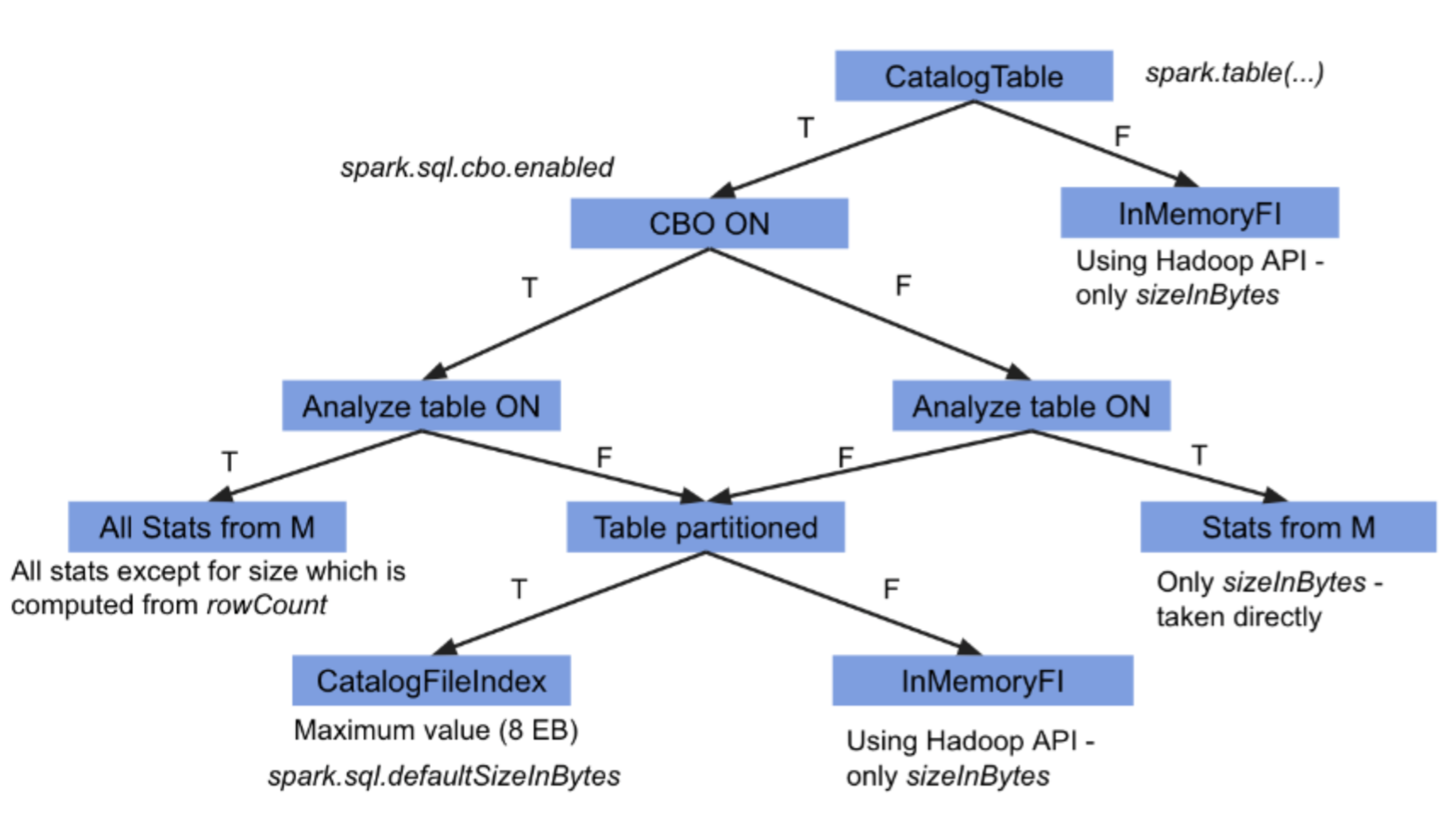
二、设计
2.1. Statistics
SparkSQL 逻辑阶段中,统计信息一般被记录在 Statistics 类中,最初它只计算了逻辑计划的物理大小。现在它还可以估计的行数、列统计信息等。
1 | case class Statistics( |
统计信息主要包含三个字段 sizeInBytes、rowCount 和 attributeStats。统计信息首先会由叶节点计算,每个叶节点会以某种方式来计算统计信息。然后他们通过某些rules应用遍历到 plan 树上。
- sizeInBytes: 物理大小(以字节为单位),对于叶子运算符此值默认为1, 非叶子运算符为child节点的sizeInBytes乘积。
- rowCount: 估计的行数
- attributeStats: logicalPlan 涉及到的列的统计信息,一个 expressID 到列信息的映射
2.1.1. ColumnStat
ColumnStat 表示表中列的详细统计信息,例如最大值,最小值,空值个数,平均长度,最大长度
2.1.2. Catalog 相关
CatalogStatistics
CatalogStatistics 表示存储在外部 Catalog (例如 hive metastore)中的表的信息,这些表的信息需要使用
analyze table命令来计算,然后存储到 Catalog 里。CatalogColumnStat
2.2. 相关规则
2.2.1. DetermineTableStats
2.3. Statistics 计算
SparkSQL 使用访问者模式和 mixin 来在逻辑计划阶段实现统计信息的传播,要实现统计信息的传播就需要实现 LogicalPlanStats 接口,这样就可以直接在逻辑计划中通过 stats 来获取当前节点的统计信息。
从Statistics类定义可以看出,统计信息主要包含三个字段sizeInBytes、rowCount和attributeStats。统计信息首先会由叶节点计算,每个叶节点会以某种方式来计算统计信息。然后他们通过某些rules应用遍历到plan树上。
SparkSQL使用访问者模式和mixin来在逻辑计划阶段实现统计信息的传播,要实现统计信息的传播就需要实现LogicalPlanStats接口,这样就可以直接在逻辑计划中通过stats来获取当前节点的统计信息。
$LogicalPlanStats.stats$ 方法用来计算 statistics,如果开启了 cbo,则用 $BasicStatsPlanVisitor.visit()$ ,否则调用 $SizeInBytesOnlyStatsPlanVisitor.visit()$ 方法。
1 | def stats: Statistics = statsCache.getOrElse { |
从类的名字就可以看出来,只有 cbo 开启,才会计算 rowCount 以及 attributeStats 信息,如果没有 cbo,SizeInBytesOnlyStatsPlanVisitor 只会计算 size 信息。
2.3.1. LogicalPlanVisitor
LogicalPlanVisitor 采用 visitor 设计模式来计算 stats 信息,根据不同的 plan 会有不同的 $visit$ 方法来实现 stats 信息生成。

1 | def visit(p: LogicalPlan): T = p match { |
$visitAggregate/Distinct/…()$
$default()$
$BasicStatsPlanVisitor.default()$
在开启 CBO 的情况下,计算
sizeInBytes会首先根据每一列的数据类型信息计算单行的大小,然后乘以 rowCount 得到最终的sizeInBytes。如果rowCount为零,则将sizeInBytes设置为 1 以避免在其他一些统计信息计算中除以零。1
2
3
4
5
6
7
8
9
10
11override def default(p: LogicalPlan): Statistics = p match {
case p: LeafNode => p.computeStats()
case _: LogicalPlan =>
val stats = p.children.map(_.stats)
val rowCount = if (stats.exists(_.rowCount.isEmpty)) {
None
} else {
Some(stats.map(_.rowCount.get).filter(_ > 0L).product)
}
Statistics(sizeInBytes = stats.map(_.sizeInBytes).filter(_ > 0L).product, rowCount = rowCount)
}$SizeInBytesOnlyStatsPlanVisitor.default()$
1
2
3
4override def default(p: LogicalPlan): Statistics = p match {
case p: LeafNode => p.computeStats()
case _: LogicalPlan => Statistics(sizeInBytes = p.children.map(_.stats.sizeInBytes).filter(_ > 0L).product)
}
2.3.2. default()
LeafNode
统计信息都是一层一层从叶子节点往上传递的,当匹配到叶子节点的时候,则直接调用该 $computeStats()$ 方法。
DataSourceV2Relation
直接调用 $table.newScanBuilder$ 如果继承了 SupportsReportStatistics,则调用该 $estimateStatistics()$ 方法
1
2
3
4
5
6
7
8
9
10
11
12override def computeStats(): Statistics = {
if (Utils.isTesting) {
throw new IllegalStateException(s"BUG: computeStats called before pushdown on DSv2 relation: $name")
} else {
table.asReadable.newScanBuilder(options).build() match {
case r: SupportsReportStatistics =>
val statistics = r.estimateStatistics()
DataSourceV2Relation.transformV2Stats(statistics, None, conf.defaultSizeInBytes, output)
case _ => Statistics(sizeInBytes = conf.defaultSizeInBytes)
}
}
}$estimateStatistics()$
ParquetScan,默认是继承 FileScan 的 $estimateStatistics()$ 方法
1
2
3
4
5
6
7
8
9
10
11
12override def estimateStatistics(): Statistics = {
new Statistics {
override def sizeInBytes(): OptionalLong = {
val compressionFactor = sparkSession.sessionState.conf.fileCompressionFactor
val size = (compressionFactor * fileIndex.sizeInBytes /
(dataSchema.defaultSize + fileIndex.partitionSchema.defaultSize) *
(readDataSchema.defaultSize + readPartitionSchema.defaultSize)).toLong
OptionalLong.of(size)
}
override def numRows(): OptionalLong = OptionalLong.empty()
}
}
Non-LeafNode
如果不是 LeafNode,会根据所有的 children 的size信息来生成自己的stats 信息
2.3.3. visitAggregate/Distinct/…
关闭 CBO: SizeInBytesOnlyStatsPlanVisitor
SizeInBytesOnlyStatsPlanVisitor 每个 UnaryNode 统计信息计算的通用方法: $visitUnaryNode()$
1
2
3
4
5
6
7
8
9private def visitUnaryNode(p: UnaryNode): Statistics = {
val childRowSize = EstimationUtils.getSizePerRow(p.child.output)
val outputRowSize = EstimationUtils.getSizePerRow(p.output)
var sizeInBytes = (p.child.stats.sizeInBytes * outputRowSize) / childRowSize
if (sizeInBytes == 0) {
sizeInBytes = 1
}
Statistics(sizeInBytes = sizeInBytes)
}$getSizePerRow()$ 的主要作用是给定逻辑计划返回的一行的大小,在获取行大小的开销为8(用于避免除以 0)。再加上各个数据类型的大小。举个例子,结果集由 2 列 (IntType, StringType) 组成,其中IntType分别为 4 和 StringType类型为20,再加上获取行的开销8。则每行的大小为 32 (4 + 20 + 8)。
但并非所有的所有的 plan 节点都是这么计算,一些特定的 plan 节点可能会覆盖这个结果。在 SizeInBytesOnlyStatsPlanVisitor 类中,除了$visitUnaryNode()$ 方法外。还有些特定方法,如 $visitFilter()$ ,$visitProject()$,$visitJoin()$ 等。
- $visitFilter()$
开启 CBO: BasicStatsPlanVisitor
开启 CBO 的情况
$visitFilter()$
1
2
3override def visitFilter(p: Filter): Statistics = {
FilterEstimation(p).estimate.getOrElse(fallback(p))
}在 $visitFilter()$ 中调用了 $FilterEstimation.estimate$ 的方法:
1
2
3
4
5
6
7
8
9
10
11
12def estimate: Option[Statistics] = {
if (childStats.rowCount.isEmpty) return None
val filterSelectivity = calculateFilterSelectivity(plan.condition).getOrElse(1.0)
val filteredRowCount: BigInt = ceil(BigDecimal(childStats.rowCount.get) * filterSelectivity)
val newColStats = if (filteredRowCount == 0) {
AttributeMap[ColumnStat](Nil)
} else {
colStatsMap.outputColumnStats(rowsBeforeFilter = childStats.rowCount.get, rowsAfterFilter = filteredRowCount)
}
val filteredSizeInBytes: BigInt = getOutputSize(plan.output, filteredRowCount, newColStats)
Some(childStats.copy(sizeInBytes = filteredSizeInBytes, rowCount = Some(filteredRowCount), attributeStats = newColStats))
}可见,在开启 CBO 后,Spark 可以利用 Metastore 中的统计信息。Spark 可以通过 $calculateFilterSelectivity()$ 返回在 Filter 节点中满足条件的行的百分比,它会区分单一和复合条件根据列统计信息更新统计信息。
三、Statistics 使用
统计信息在 Spark 中各处被使用:
Join 策略的选择
使用统计信息来确定 Spark SQL Join 的策略。它通过检查统计信息来校验表是否可广播,或者在 Shuffle Hash Join 的情况下物理计划的大小是否满足指定的阈值等。
星型表的检测
在星型模式中,区分事实表和维度表需要依赖事实表大于维度表的规则。这时基于统计信息(估计了行数和列数(空值和不同值的数量)统计信息)来判断表的类型。
Full Outer Join 和 Limit 一起使用
使用统计信息比较两边的大小并限制 join 查询的 left side 或 right side。
CBO 优化
AQE
3.1. Join 策略选择
3.2. 星型表检测
3.3. full outer join 和 limit 一起使用
3.4. CBO 优化
Cost-based optimizer(CBO) 基于数据表的统计信息(如表大小、数据列分布)来选择优化策略。CBO 支持的统计信息很丰富,比如数据表的行数、每列的基数(Cardinality)、空值数、最大值、最小值和直方图等等。
在 CBO 中使用统计信息主要是在 CostBasedJoinReorder Rule中,使用这个 Rule, Spark 可以更加精准的选择 Join 策略,避免在小表 join 的情况下仍然使用 SMJ。
但此规则默认是关闭的,使用前需要打开如下配置:
1 | spark.sql.cbo.enabled=true |
此外 CBO 规则的优化依赖于表的统计信息,需要在执行 SQL 前先运行 Analysis Table 语句收集统计信息,而各类信息的收集会消耗大量时间:
1 | ANALYZE TABLE table_name COMPUTE STATISTICS; |
CBO 仅支持注册到 Hive Metastore 的数据表,但在大量的应用场景中,数据源往往是存储在分布式文件系统的各类文件,如 Parquet、ORC、CSV 等等。此外,如果在运行时数据分布发生动态变化,CBO 先前制定的执行计划并不会跟着调整、适配。
https://blog.csdn.net/wankunde/article/details/103623897/
3.5. AQE
AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
首先,AQE 赖以优化的统计信息与 CBO 不同,这些统计信息并不是关于某张表或是哪个列,而是 Shuffle Map 阶段输出的中间文件。学习过 Shuffle 的工作原理之后,我们知道,每个 Map Task 都会输出以 data 为后缀的数据文件,还有以 index 为结尾的索引文件,这些文件统称为中间文件。每个 data 文件的大小、空文件数量与占比、每个 Reduce Task 对应的分区大小,所有这些基于中间文件的统计值构成了 AQE 进行优化的信息来源。
其次,AQE 从运行时获取统计信息,在条件允许的情况下,优化决策会分别作用到逻辑计划和物理计划。
下面我们来简单分析下 AQE 中如何获取 MapStage 运行时的统计信息:
1 | // ShuffleExchangeExec |
运行时的统计信息主要依赖于 Spark 的 metrics 进行统计收集, 例如在 ShuffleExchangeExec 中通过 runtimeStatistics 从 metrics 获取数据的统计信息。
1 | def computeStats(): Option[Statistics] = resultOption.map { _ => |
在 query stage 执行中,通过 metrics(“dataSize”) 更新计算其 sizeInBytes。
 微信
微信 支付宝
支付宝








