
Spark-源码学习-SparkSQL 系列-代码生成-WholeStageCodegenExec
一、概述
WholeStageCodegenExec 是全阶段代码生成的实现类,用来将多个处理逻辑整合到单个代码模块中,然后将SQL中的逻辑表达式转换成 Java 函数,其也是 SparkPlan,所以主逻辑在 $execute()$ 方法中。具体可以分为:代码生成、代码编译和数据获取
二、执行 doExecute()
2.1. 生成代码 doCodeGen()
WholeStageCodegenExec 生成代码的入口在 $doCodeGen()$ 方法中
1 | val (ctx, cleanedSource) = doCodeGen() |
2.1.1. 构造 CodegenContext
$doCodeGen()$ 方法首先构造一个 CodegenContext 对象,然后将此对象作为 CodegenSupport 中 $produce()$ 方法的参数,直接调用 $produce()$ 方法生成具体的处理代码片段;最终基于该代码片段和代码生成之后的 CodegenContext 对象,构造完整的代码段。
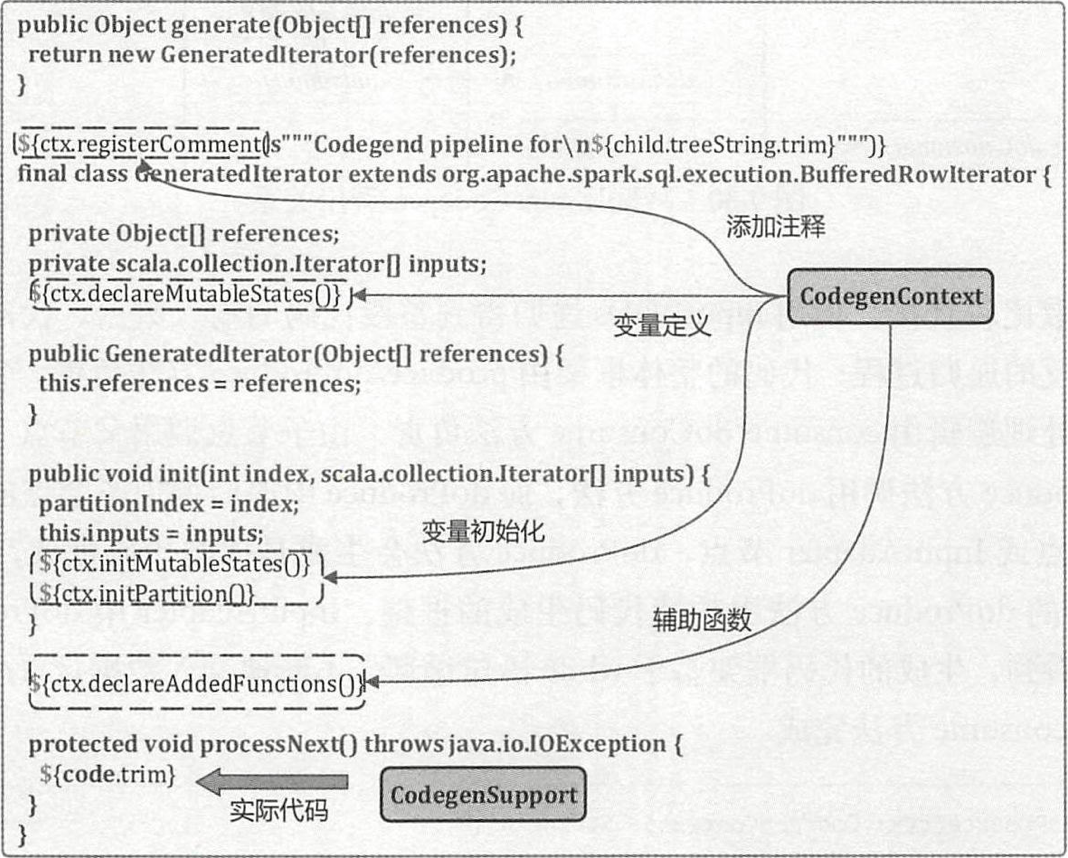
WholeStageCodegenExec 生成的代码中通过一个 $generate()$ 静态方法来构造 GeneratedIterator 对象。GeneratedIterator 对象是 Spark 中 BufferedRowIterator 对象的子类,重载实现了 $init()$ 方法负责相关变量的初始化和 $ProcessNext()$ 方法用于循环处理 RDD 中 的数据行。GeneratedIterator 类中会声明 CodegenContext 中保存的状态变量,在初始化方法 $init()$ 中会加入 $initMutableStates()$ 与 $initPartition()$ 方法。同样的,也会加入 declareAddedFunctions 来声明 CodegenContext 中定义的相关函数。
2.1.2. Produce-Consume 模式
如果一个 Physical plan 想要支持 codegen,就需要实现 Codegensupport 接口,井且重写 $doProduce$ 和 $doConsume$ 函数。
$doProduce$ 方法用于生成 “手写” 代码的主要框架,$doConsume$ 方法主要用于向框架填充每一个操作符的运算逻辑,$inputRDDs$ 用于获得产生输入数据的
在核心的 $processNext()$ 方法中,直接加入 WholeStageCodegenExec 中 $produce()$ 方法生成的代码(code.trim)
2.2. 编译代码
WholeStageCodegenExec 生成 Java 代码之后,就会交给 Janino 编译器进行编译。
1 | val (_, compiledCodeStats) = try { |
$doCodeGen()$ 方法返回 CodegenContext 对象与生成并格式化后的代码 (cleanedSource),Spark 首先尝试编译,如果编译失败且配置回退机制(参数 spark.sql.codegen.wholeStage 默认为 true),则代码生成将被舍弃转而执行 Spark 原生的逻辑 $child.execute()$。
编译任务由 CodeGenerator 中的 $doCompile()$ 方法执行,调用 Janino 中的 ClassBodyEvaluator 对象。
ClassBodyEvaluator 类单独定义了一个 ParentClassLoader,这样避免编译过程中抛出 ClassNotFoundException 异常。最终得到的是一个 GeneratedClass 类,提供了 generate 方法入口供外部调用。
2.3. 调用 inputRDDs() 数据获取
WholeStageCodegenExec 的后续处理和其他物理算子节点 (mapPartitionsWithIndex) 类似。调用 $inputRDDs()$ 方法得到 RDD 列表后,会根据 RDD 的数量采取不同的处理逻辑。在现有的实现中,代码生成仅最多支持对两个 RDD 的处理。
1 | val rdds = child.asInstanceOf[CodegenSupport].inputRDDs() |
- 构造 WholeStageCodegenEvaluatorFactory
三、总结
每一个 WholeStageCodegenExec 执行时,首先获取输入 $inputRDDs$ ,递归执行子节点的 $inputRDDs$ 函数,直到碰到 InputAdapter 或者数据源物理计划节点,返回子物理计划节点的 executor 计算结果 RDD 或者数据源 RDD。然后进行代码生成,递归执行 $produce()$ 函数,直到碰到 InputAdapter 或者数据源物理计划节点,返回所有子节点生成的综合代码。利用在WholeStageCodegenExec 节点上利用生成代码对 $inputRDDs$ 进行处理。
所以 WholeStageCodegenExec 的 $executor()$ 方法不会递归调用子物理计划节点的 $executor()$ 方法,首先获得整个 WholeStageCodegenExec 子树的输入 $inputRDDs$ ,然后获得整个 WholeStageCodegenExec 子树的生成代码。最后用生成代码对 $inputRDD$ 进行处理,一次性的完成了子树中所有物理计划节点的执行任务。这样避免了火山模型中的迭代调用。
WholeStageCodegenExec 其实是将迭代调用转移到了代码生成的阶段,在执行阶段只需一次调用即可。
 微信
微信 支付宝
支付宝








