Spark-理论笔记-本地化执行引擎-Gluten
一、概述
Spark 计算模型目前基于 JVM 实现,而 JVM 只能利用一些基础的 CPU 指令集。虽然有 JIT 的加持,但相比目前市面上很多的 Native 向量化计算引擎而言,性能还是有较大差距。因此考虑将具有高性能计算能为的 Native 向量引擎引用到 Spark 里来,从而提升 Spark 的计算性能,突破 CPU 瓶颈。Spark 作为基础计算框架,不管是在稳定性还是可扩展性方面,以及生态建设都得到了业界广泛认可。在不考虑改动 Spark 基础框架,使用 Native 计算引擎替换掉 Spark 原有基于 JVM 的 Task 计算模型,可以把高性能计算能力带给 Spark,突破 CPU 的瓶颈问题。
Native 计算引擎基于 C++ 开发,容易利用 CPU 原生指令集的优化。另外 Native 引擎基于列式数据格式,容易做向量化处理,进而达到高性能计算。基于这两点,Gluten 项目应运而生。Gluten 是一个基于 Spark 的向量化引擎中间件,把 Spark SQL 整个执行过程当中的计算转移到向量化引擎去执行,获得指令集的原生加速。
二、设计
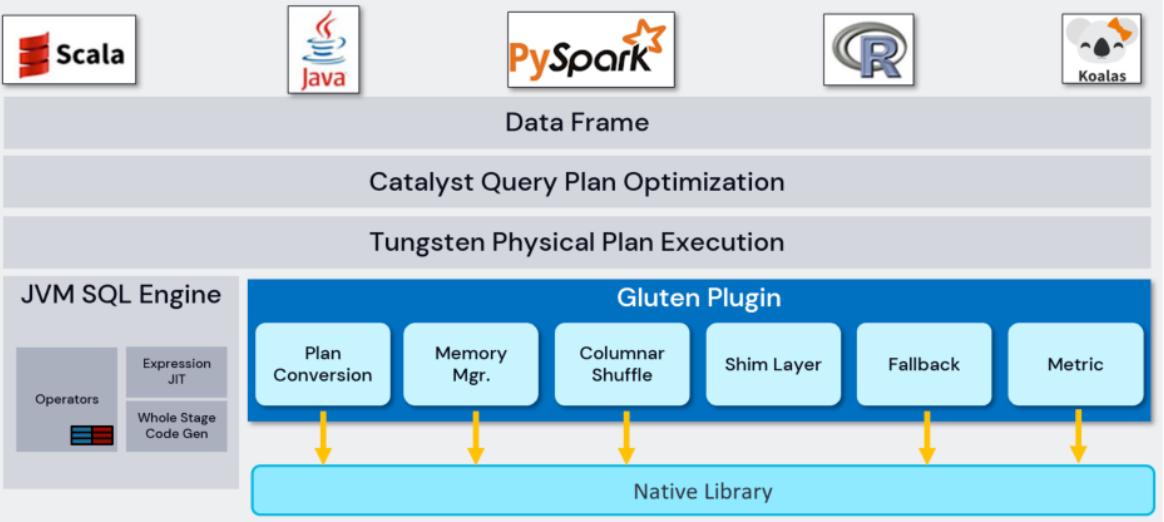
Gluten 沿用 Spark 原有的框架。当一个 SQL 进来,会通过 Spark 的 Catalyst 把 SQL 转成 Spark 的物理计划,然后物理计划会传递给 Gluten。Gluten 会以 Plugin 的方式集成到 Spark 中。在 Physical Plan 交给 Gluten Plugin 的时候,添加扩展规则,把 Physical Plan 转换成语言无关的 Substrait Plan。转换后交由下面的各种 Native 向量化引擎去执行计算。各自的向量化引擎会根据 Substrait Plan 构建自己的 Execute pipeline,然后读取 Input 数据去做计算,计算完后都会以列式方式返回给 Spark。
整个数据流转过程是基于 Spark 原生 ColumnarBatch 和 ColumnarVector 抽象,为 Native 向量化引擎做具体的扩展和实现。
目前 Gluten 支持 Velox、 ClickHouse、 Arrow Computer Engine。对于 ClickHouse,其内部有 block 概念,以 block 的方式去扩展 vector。对于 Arrow Computer Engine,Arrow 定义了内存数据格式,引擎把计算后的数据转为 ArrowColumnarVector 的格式表达 Arrow 类型的数据,从而让 Spark 能够去识别和读取。
2.1. 组件
在整个流转过程当中,Gluten 的 Plugin 层起到承上启下的关系
2.1.1. Conversion
Conversion 组件是最核心的组件,负责把 Spark Physical Plan 通过 Extension rule inject 的方式转成 Substrait Plan,然后再把 Substrait Plan 传递到底层的 Native Engine 执行。
2.1.2. Memory Management
在 Gluten 中 Native 代码和 Spark Jave 代码在同一个进程中运行,Native 空间的代码在申请内存的时候,会先向本地的 Memory Pool 申请内存,如果内存不足,会进一步向 JVM 中 Task Memory Manager 申请内存配额,得到相应配额后才会在 Native 空间成功申请下内存。通过这种方式,Native 空间的内存申请也受到 Task Memory Manager 的统—管理。当发生内存不足的现象时,Task Memory Manager 会触发 spill,不管是 Native 还是 JVM 中的 operator 在收到 spill 通知时都会释放内存。
2.1.3. Columnar Shuffle
由于 Native Engine 大多采用列式数据结构暂存数据,如果简单的沿用 Spark 的基于行数据模型的 Shuffle,则会在 Shuffle Write 阶段引入数据列转行的环节,在 Shuffle Read 阶段引入数据行转列的环节,才能使数据可以流畅周转。但是无论行转列,还是列转行的成本都不低。因此,Gluten 提供了完整的列式 Shuffle 机制及及统一 API接口用于街接市场受欢迎的第三方 RemoteShuffleService 如 Celeborn,避免了数据转换开销及提供服务。
Celeborn
Gluten 集成 Celeborn 的设计目标是同时保留 Gluten Columnar Shuffle 和 Celeborn Remote Shuffle 的核心设计,让两者的优势叠加。
2.1.4. Shim Layer
Shim Layer 是为了让 Gluten 能支持多个版本的 Spark。
2.1.5. Fallback
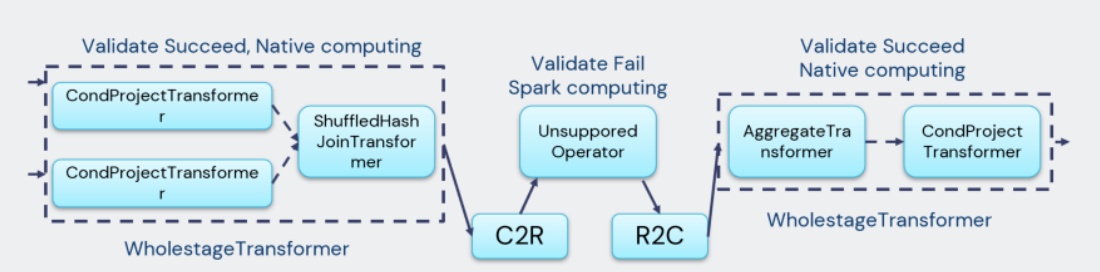
Gluten 目前没有支持 Spark 的全部 operator/expression。在 pipeline 的转换过程中,对 Spark 的 Physical Plan 做验证,验证成功说明该 Physical Plan 包含的 operator/expression 都支持使用 Native 向量化引擎执行。则尽可能打包成一个 whole Stage 的 Transformer。验证失败说明 Native Engine 无法支持当前 operator/expression,触发 fallback 机制。
因为 Spark 的计算是基于行式的,而 Native 向量化引擎是基于列式的。因此需要在 fallback 这个 operator 前后插入行转列、列转行的算子,要尽可能避免 fallback 操作,因为这两次转换对整个执行的过程的性能损耗是很大的。
2.1.6. Metrics
负责把 Native Engine 执行过程中的指标统计上报给 Gluten Plugin,然后再由 Plugin 上报给 Spark 的 Metrics System 做展示或 API 调用。
2.2. Backend
为了兼容不同的本地引擎,Gluten 定义了清晰的 JNI 接口,作为 Spark 框架和底层引擎之间的桥梁。这些接口用于请求传递、数据传输和能力检测等方面的需求。开发者只需实现这些接口,并满足相应的语义要求,即可利用 Gluten 完成 Spark 和本地引擎的整合工作
Gluten 这个单词在拉丁文中有胶水的意思,Gluten 项目的作用也正像胶水一样,主要用于”粘合” Apache Spark 和作为 Backend 的 Native Vectorized Engine。Backend 的选项有很多,目前在 Gluten 项目中已经明确开始支持的有 Velox、 Clickhouse 和 Apache Arrow。
Gluten 本身不提供 Native 引擎,而只是把 Spark 和 Native 引擎用胶水 Glue 在一起~
2.2.1. Velox
2.2.2. Arrow Computer Engine
2.3. 数据传递和共享
在 Gluten 的执行过程当中,涉及到的数据传递流程。在 Spark 里有 ColumnarBatch 和对应的 ColumnarVector 抽象。基于这个抽象把 Native Engine 各自对应的 Native 列式数据表达做具体实现。
 微信
微信 支付宝
支付宝