
Spark-源码学习-SparkSQL 系列-代码生成-整体流程
一、概述
1 | select name from student where age > 18 |
二、CollapseCodegenStages 规则
Catalyst 全阶段代码生成的入口是 CollapseCodegenStages 规则,当设置了支持全阶段代码生成的功能时(默认将 spark.sql.codegen.wholeStage 设置为 true,CollapseCodegenStages 规则会将生成的物理计划中支持代码生成的节点生成的代码整合成一段,因此称为全阶段代码生成 WholeStageCodegen。
本例中查询生成的物理计划包括 FileSourceScanExec、FilterExec 和 ProjectExec 3 个节点。这 3 个节点都支持代码生成,因此 CollapseCodegenStages 规则会在 3 个物理算子节点上添加 WholeStageCodegenExec 节点,将这 3 个节点生成的代码整合在一起。此外,加入 WholeStageCodegenExec 物理节点后,物理计划打印输出时不会打印该节点本身,其所囊括的所有子节点在打印输出字符串时,都会统一加入特定的 * 字符作为前缀,用来区别不支持代码生成的物理计划节点。

执行计划说明
*代表当前节点可以 WSCG- 括号中的数字,代表的是 codegen stage id,即代码生成的阶段 id
codegen stage的划分: 相邻节点(父子节点)且节点支持codegen ,会被划分到同一个 codegen stage, 直到不支持 codegen 的节点。
比如: HashAggregate、SerializeFromObject 节点支持,Exchange 节点不支持,那么HashAggregate 、SerializeFromObject就会被划分到同一个stage中
- 括号里的数字,代表字段 id, id 相同的代表同一个字段,相同的 codegen stage id 代码会被折叠在一起,减少函数的调用
- 支持 Codegen 的 SparkPlan 上添加一个 WholeStageCodegenExec,不支持 Codegen 的 SparkPlan 则会添加一个 InputAdapter
三、WholeStageCodegenExec 执行
3.1. 概述
WholeStageCodegenExec 执行时会调用其子节点 ProjectExec 中的 $produce()$ 方法得到生成的代码,因此 ProjectExec 的 $produce()$ 方法是整个代
码生成过程的入口。
ProjectExec 节点的 $produce()$ 调用 $doProduce()$ 方法,继而调用 FilterExec 节点的 $produce()$ 方法。依此类推,一直到叶子节点 FileSourceScanExec 的 $doProduce()$ 方法,构造出将要生成的 Java 代码框架。

RowDataSourceScanExec
$produce()$ 方法除设置当前 CodegenSupport 节点的 Parent 节点和 CodegenContext 的变量前缀外,只是添加注释,然后直接调用 $doProduce()$ 方法。
1 | this.parent = parent |
3.2. InputRDDCodegen#doProduce()
3.2.1. 加入变量: input
加入 Iterator 类型的 input 变量,用来不断读取数据。
1 | val input = ctx.addMutableState("scala.collection.Iterator", "input", v => s"$v = inputs[0];", forceInline = true) |
3.2.2. 生成 ExprCode 对象
此外,当前读取的数据行(InternalRow) 在生成的代码中对应命名为 row 的变量,同时将 CodegenContext 对象中的 INPUT_ROW 指向 row 变量。有了该变量,InputRDDCodegen 节点读取的数据列就能够顺利地根据 BoundReference 生成 ExprCode 对象 (columnsRowInput 列表)
1 | val row = ctx.freshName("row") |
3.2.3. 加入变量: numOutputRows
通过 $metricTerm$ 方法在 CodegenContext 中加入一个变量名为 numOutputRows 的 SQLMetric 对象,用来记录从文件中读取的数据行数
1 | val updateNumOutputRowsMetrics = if (metrics.contains("numOutputRows")) { |
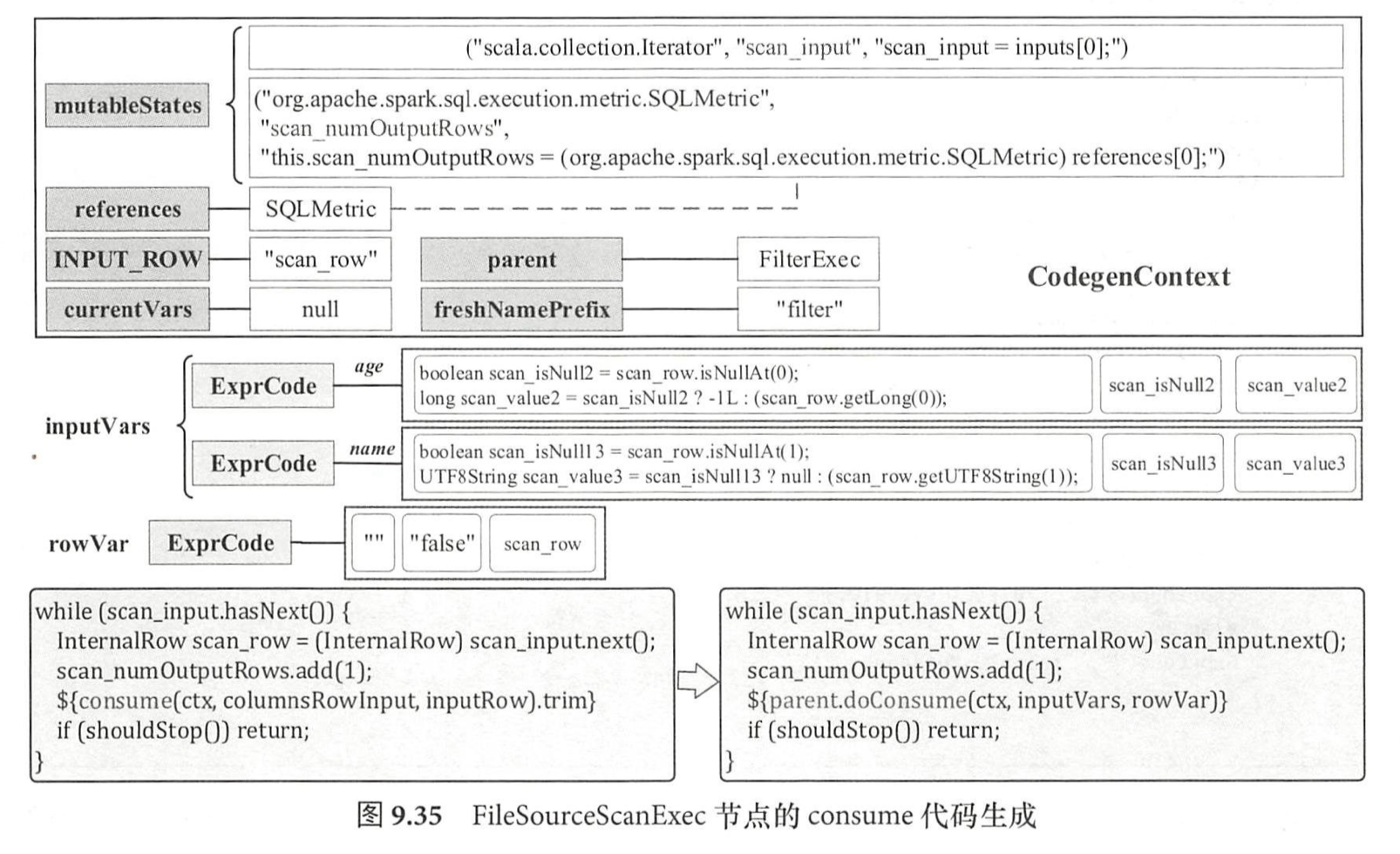
3.2.4. consume()
除读取数据 row 和更新 numOutputRows 的值外,接下来继续交给 InputRDDCodegen 节点的 $consume()$ 方法。
由于是 final 类型,所以所有节点的 $consume()$ 处理逻辑均相同。总体来讲,CodegenSupport 对象的 $consume()$ 方法所起到的作用是整合当前节点的处理逻辑,构造 (ctx, inputVars, rowVar)三元组并提交到下一个处理逻辑(交节点的 $doConsume()$ 方法)。
$consume()$ 方法会检查当前生成的代码中是否已经包含了下一步所需的变量,并完成 3 个方面的功能。
生成下一步逻辑处理的变量 inputVars,类型为 Seq[ExprCode],不同的变量代表不同的列。
其中 row 表示当前数据行对应的变量(ExprCode),outputVars 对应列信息的变量列表(Seq[ExprCode])。分为两种情况,如果有行变量,那么将 CodegenContext 对象的 INPUT_ROW 指向该行变量,且 currentVars 设为 null,得到的 inputVars 为该节点的输出字段对应的 BoundReference 生成的代码;如果行变量为空,则直接将 outputVars 复制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16val inputVarsCandidate =
if (outputVars != null) {
assert(outputVars.length == output.length)
outputVars.map(_.copy())
} else {
assert(row != null, "outputVars and row cannot both be null.")
ctx.currentVars = null
ctx.INPUT_ROW = row
output.zipWithIndex.map { case (attr, i) =>
BoundReference(i, attr.dataType, attr.nullable).genCode(ctx)
}
}
val inputVars = inputVarsCandidate match {
case stream: Stream[ExprCode] => stream.force
case other => other
}生成 rowVar,类型为 ExprCode,代表整行数据的变量名。
如果传入的行变量不为空,则直接对应该行变量的 ExprCode 对象;如果行变量为空,但是传入的列变量不为空,那么根据 output 由 GenerateUnsafeProjection 生成代码的主要内容(createCode),否则构造名为 unsafeRow 的 ExprCode对象。
1
val rowVar = prepareRowVar(ctx, row, outputVars)

在构造上述对象的过程中,相应修改 CodegenContext 对象中的元素。

$consume()$ 方法中通常还会用到 $evaluateVariables$ 和 $evaluateRequiredVariables$ 两个辅助函数。
这里的 evaluate 直接翻译为“评价”,体现在生成的代码中就是该代码片段已经声明。因此,evaluateVariables 方法得到按行分隔的所有 code 不为空的 ExprCode 代码,并将 ExprCode 对应的 code 设置为空;而 evaluateRequiredVariables 只是根据所需的列集合 (AttributeSet) 筛选出
对应的 ExprCode 代码,其他操作和 evaluateVariables 方法中的逻辑相同。
经过 $consume()$ 操作后的变化主要有两个地方:
一个是 CodegenContext 对象中的 freshNamePrefix 从 scan 变为 filter,表示接下来的代码开始进入 FiterExec 的处理逻辑范围;另一个是传递给 $doProduce()$ 的输入变量 inputVars,可以看到 scan_value2 和 scan_value3 分别表示 age 与 name 两个字段。
在 $consume()$ 的逻辑中:
如果传入的变量 row 不为空(对应数据源节点),则根据 output 重新得到 BoundReference
这里 FileSourceScanExec 节点就对应这种情况。
如果传入的变量 row 为空,inputVars 会对 outputVars 执行 copy 操作
因为这里的 outputVars 变量会用到 CodegenContext 中的 currentVars 来生成 UnsafeRow 代码。
FilterExec
$FilterExec.doConsume()$
同样在 FilterExec 中首先会通过 $metricTerm()$ 方法在 CodegenContext 中加入一个变量名为
numOutputRows的 SQLMetric 对象,用来记录经过过滤处理之后的数据行数。此外,CodegenContext 中的currentVars会设置为当前传递进来的输入变量 所对应的 ExprCode 对象,其 parent 对象在 $produce()$ 方法中也会对应变为 ProjectExec 算子。FilterExec 算子的 $doConsume()$ 方法实际上完成了 4 件事:
- 实际过滤条件的代码生成(Predicated)
- null 检测的代码生成(nullChecks)
- SQLMetric 变量更新: numOutput.ada(1)
- $FilterExec.consume()$
过滤条件与 null 检测是 FilterExec 算子代码生成的核心。在 FilterExec 算子中,会将过滤谓词分为 notNullPreds 和 otherPreds 两部分,notNullPreds 是所有的 IsNotNull 表达式,otherPreds 对应其它的过滤条件。

例如,本例中的 notNullPreds 列表中只有一个表达式
isnotnull(age), otherPreds 列表中也只有一个过滤条件age> 18$FilterExec.consume()$
FilterExec 算子完成了 $doConsume()$ 操作之后进入 $consume()$ 方法的操作。
$consume()$ 方法中主要完成 3 件事:
首先传递给父节点 $doConsume()$ 方法的 inputVars 变量
对于 FilterExec 节点来讲,传递的 row 为空,因此 inputVars 变量是 outputVars 的复制,从生成的代码来看两者完全相同。
FilterExec 算子中的 $consume()$ 方法由 GenerateUnsafeProjection 类得到输出的行 (rowVar) 并传递给 ProjectExec 节点。可以知道 CodegenContext 中的 INPUT_ROW 会被设置为当前传入的 row 即 null,而 currentVars 则会被设置为 outputVars 变量。
rowVar 生成的代码包括两部分: 输入列(age 与 name 列)变量的声明(evaluate),因为 age 列在之前已经声明过了,code 为空,因此这里会加上 name 列的相关代码GenerateUnsafeProjection 类在代码生成时会在 CodegenContext 中加入 3 个变量(
filter_holder、filter_rowWriter和filter_result)。经过这一步后,最终可以看到,FilterExec 算子的 $consume()$ 方法中得到的 evaluated 为空,因此在最终的代码中没有加入多的内容。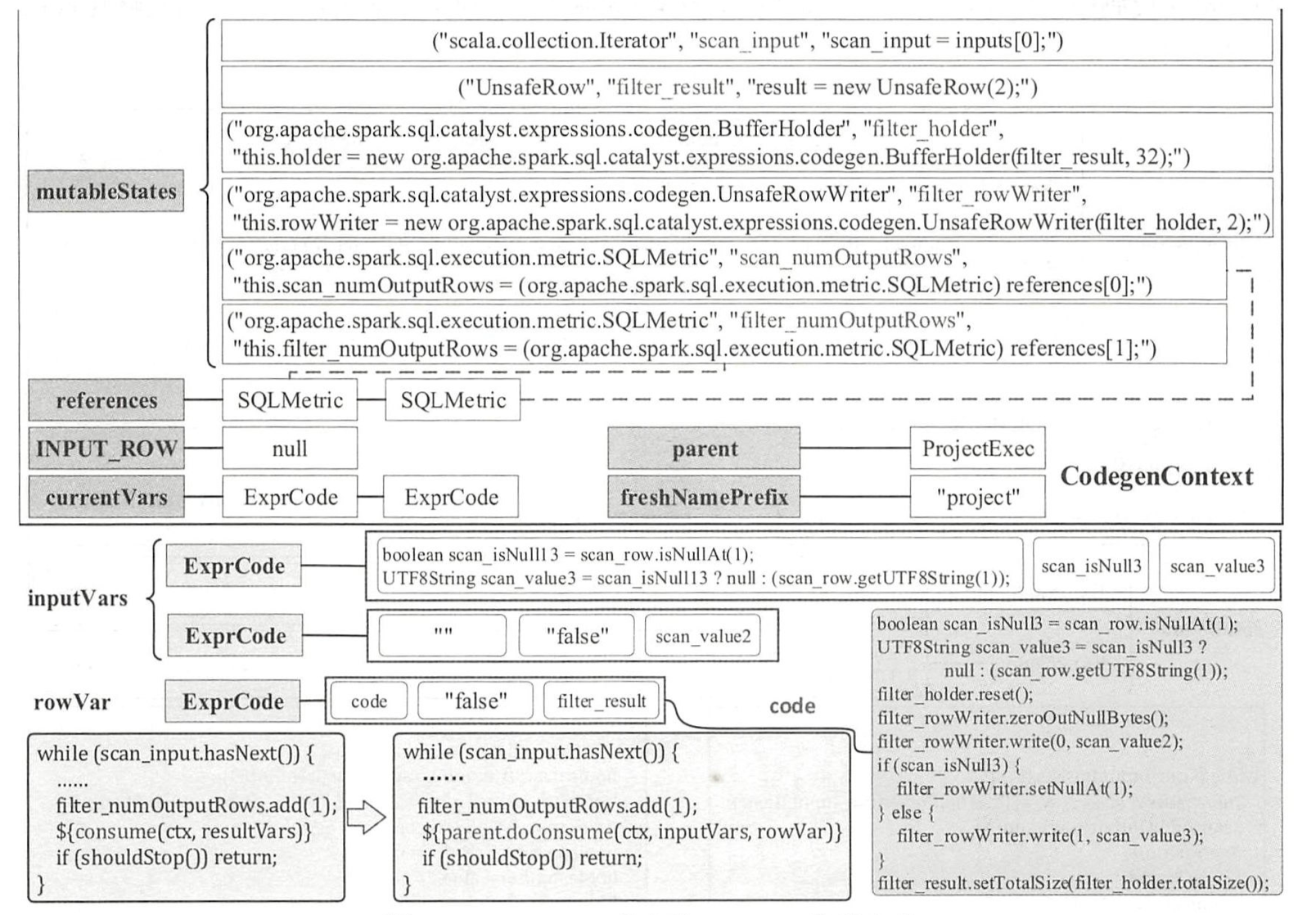
ProjectExec
$ProjectExec.doConsume()$
$ProjectExec.doConsume()$ 方法的参数 input 为 age 和 name 两个变量对应的 ExprCode (scan_value2 和 scan_value3),参数 Iow 对应上一步 FilterExec 得到的 filter_result 变量。
ProjectExec 的 doConsume 方法用不到 row 参数。
根据需要输出的列 (projectList) 生成对应的代码,并封装为 ExprCode (resultVars)。这里的 resultVars 只包含 name 列,对应的变量为 scan_value3。最终输出的代码照样会执行 $evaluateRequiredVariables()$ 方法(针对的是不确定性的表达式,确保所有的变量都己经声明过了。因为这里不确定性表达式为空,所以不会输入额外的代码。
因此,ProjectExec 节点的 $doConsume()$ 方法基本上没做比较复杂的事情,只是生成 resultVars,作为参数传递给 $consume()$ 方法。

$ProjectExec.consume()$
类似 FilterExec 算子的效果,
inputVars直接复制传入的outputVars参数 ($doConsume()$ 中得到的 resultVars 变量)。同样的,
$consume()$ 方法中生成的行变量 (rowVar) 由 GenerateUnsafeProjection 类生成。在此过程中,同样会在 CodegenContext 中增加 project_result、project _holder 和 project_rowWriter 3 个变量,同时将currentVars设置为outputVars,并将变量字符串前缀改为父节点的名称 (wholestagecodegen)可以看到,rowVar 对应的代码和 FiterExec 节点执行 $consume()$ 方法时的代码类似。最终的结果是,ProjectExec 节点不直接产生代码,而是将得到的 inputVar 和 rowVar 传递给父节点的 $doConsume()$ 方法。此外,也可以看到,ProjectExec 算子不会在 CodegenContext 中构造 SQLMetric 变量记录输出的数据行数,这一点与 FileSourceScanExec 节点和 FilterExec 节点不同。实际上,在一些特殊的算子(例如 Aggregation 与 Join)中,都会添加辅助变量来记录一些关键信息。

$WholeStageCodegen.doConsume()$
全阶段代码生成(WholeStageCodegen)的最后一步都会落脚在 WholeStageCodegenExec 算子的 $doConsume()$ 方法。如图9.40 所示,生成的代码首先会输出 row 变量的 code,对应 ProjectExec 中得到的 project_result 变量。
需要注意的是,是否对得到的结果执行 copy 操作取决于 CodegenContext 对象中的 copyResult 变量。在上述例子中,不需要 copy 操作,因此最终添加结果的代码为 append (project_result)。
3.2.5. shouldStopCheckCode
 微信
微信 支付宝
支付宝








