
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-架构设计
一、概述
SQL 引擎负责承接客户端输入的 SQL 请求,并根据负载场景将 SQL 语句经过其解析、优化、执行等模块的处理后,将结果返回至客户端。
对于 Spark SQL 系统,从 SQL 到 Spark 中 RDD 的执行需要经过两个大的阶段,分别是逻辑计划(LogicalPlan)和物理计划( PhysicalPlan)

1.1. 逻辑计划
逻辑计划阶段会将用户所写的 SQL 语句转换成树型数据结构(逻辑算子树),SQL 语句中蕴含的逻辑映射到逻辑算子树的不同节点,逻辑计划阶段生成的逻辑算子树并不会直接提交执行,仅作为中间阶段。
1.2. 物理计划
物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树。物理算子树的节点会直接生成 RDD 或对RDD 进行 transformation 操作。
从 SQL 语句的解析一直到提交之前,上述整个转换过程都在 Spark 集群的 Driver 端进行,不涉及分布式环境。SparkSession 类的 sql 方法调用 Session State 中的各种对象,包括上述不同阶段对应的 SparkSqlParser 类、Analyzer 类、Optimizer 类和 SparkPlanner 类等,最后封装成一个 QueryExecution 对象。
二、基础设施
2.1. 数据结构
2.1.1. InternalRow
数据处理首先需要考虑如何表示数据。对于关系表来讲,通常操作的数据都是以 行 为单位。在 Spark SQL 内部实现中,InternalRow 就是用来表示一行行数据的类。此外,InternalRow 中的每一列都是 Catalyst 内部定义的数据类型。
2.1.2. TreeNode
无论是逻辑计划还是物理计划,都离不开中间数据结构。在 Catalyst 中,对应的是 TreeNode 体系。TreeNode 类是 Spark SQL 中所有树结构的基类,定义了一系列通用的集合操作和树遍历操作接口。
2.2. Rule 体系
2.3. Stragety 体系
三、模块设计
3.1. 逻辑计划模块
逻辑计划阶段会将用户所写的 SQL语句转换成树型数据结构(逻辑算子树),SQL 语句中蕴含的逻辑映射到逻辑算子树的不同节点,逻辑计划阶段生成的逻辑算子树并不会直接提交执行,仅作为中间阶段。最终逻辑算子树的生成过程经历3个子阶段,分别对应未解析的逻辑算子树(Unresolved LogicalPlan,仅仅是数据结构,不包含任何数据信息等)、解析后的逻辑算子树(Analyzed LogicalPlan,节点中绑定各种信息)和优化后的逻辑算子树 (Optimized LogicalPlan,应用各种优化规则对一些低效的逻辑计划进行转换)
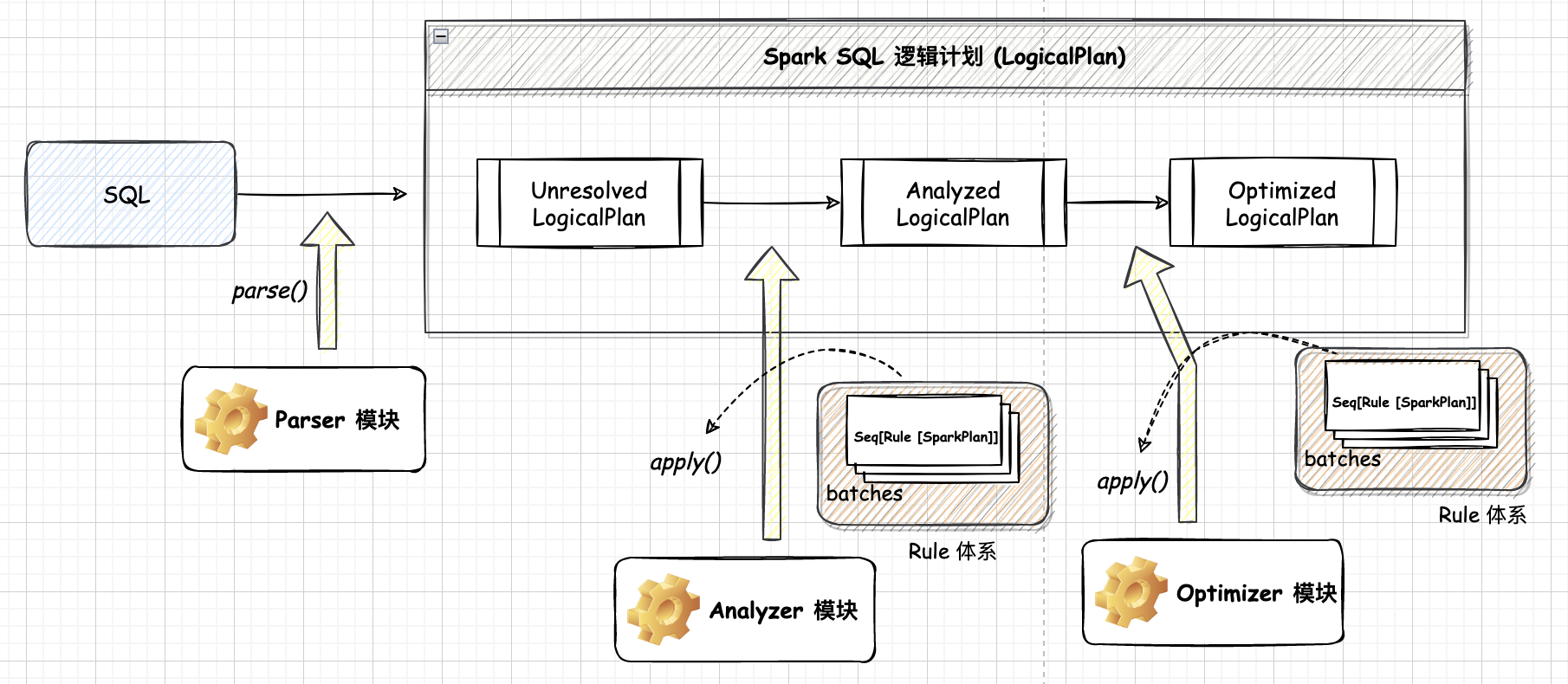
3.1.1. 解析 Parser
Parser 模块目前基本都使用第三方类库 ANTLR 进行实现,比如 Hive、Presto、SparkSQL 等。SQL 经过词法和语法解析,由字符串转换为抽象语法树,通过遍历抽象语法树生成未解析的逻辑算子树 (Unresolved logic plan)
3.1.2. 分析 Analyzer
Analyzer 模块遍历整个未解析的逻辑算子树,对 Unresolved logic plan 的节点进行数据类型的绑定以及函数绑定,然后根据元数据信息 Catalog 对数据表中的字段进行解析。
3.1.3. 优化 Optimizer
Optimizer 根据预先定义好的规则 (RBO) 对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan(最优逻辑计划)
至此,逻辑执行计划已经得到了比较完善的优化,然而,Spark 并不知道如何去执行逻辑计划。比如 Join 只是一个抽象概念,代表两个表根据相同的 id 进行合并,然而具体怎么实现这个合并,逻辑执行计划并没有说明~所以需要将逻辑执行计划转换为物理执行计划,将逻辑上可行的执行计划变为 Spark 可以真正执行的计划~
3.2. 物理计划模块 Planner
物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树。物理算子树的节点会直接生成 RDD 或对 RDD 进行 transformation 操作。物理计划阶段也包含 3 个子阶段:
根据逻辑算子树,生成物理算子树的列表 Iterator[PhysicalPlan]
一个 LogicalPlan 可能产生多种 SparkPlan,SparkPlanner 将各种物理计划策略 (Strategy) 作用于对应的逻辑计划节点上,Strategy 将某个逻辑算子转化成对应的物理执行算子,生成多个可以执行的物理计划 Physical Plan
在转化过程中,一个逻辑算子可能对应多个物理算子的实现,比如 Join 算子,Spark 根据不同场景为该算子制定了不同的算法策略,有 BroadcastHashJoin、ShuffleHashJoin 以及 SortMergeJoin 等
从列表中按照一定的策略选取最优的物理算子树(SparkPlan)
目前实现较为简单,在候选列表中直接用 $next()$ 方法获取第一个。
最后,对选取的物理算子树进行提交前的准备工作,例如,通过 $prepareForExecution()$ 方法调用若干规则 (Rule) 确保分区操作正确、物理算子树节点重用、执行代码生成等,最终调用 $SparkPlan.execute()$ 方法,返回 RDD。
经过逻辑计划和物理计划阶段,物理算子树生成的 RDD 执行 action 操作,即可提交执行。

 微信
微信 支付宝
支付宝








