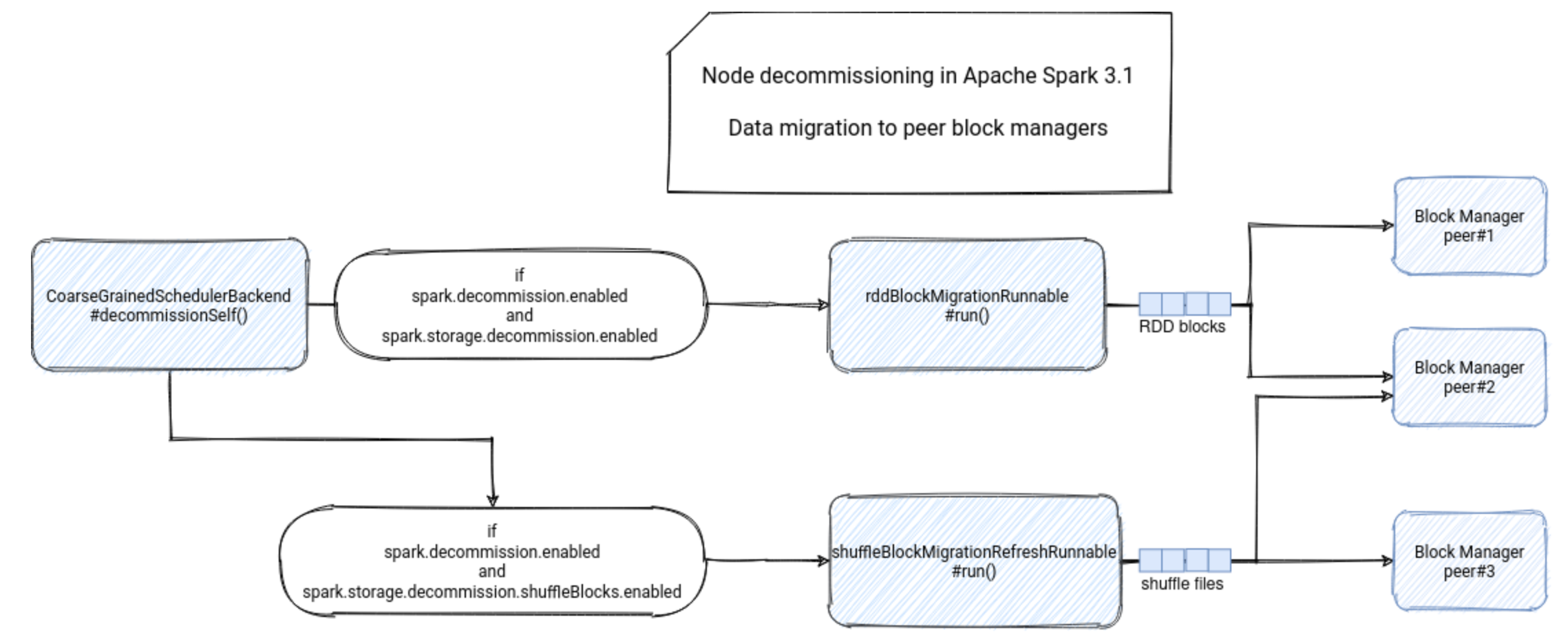
Hadoop-组件-HDFS-源码学习-集群启动-DataNode 启动-initDataXceiver
initDataXceiver() 方法是 DataNode 启动的核心代码之一啦!内容很多~,开始看源码😯~~~
一、概述
在 Java 的 Socket 实现中,首先需要创建一个 java.net.ServerSocket 对象,绑定到某个指定的端口,然后通过 ServerSocket.accept() 方法监听是否有连接请求到达这个端口。当有 Socket 连接请求时,ServerSocket.accept() 方法会返回一个 Socket 对象,之后服务器就可以通过这个 Socket 对象与客户端通信了。
Datanode 的流式接口就参考了 Socket 的实现,设计了 DataXceiverServer 以及 DataXceiver 两个对象,其中 DataXceiverServer 对象用于在 Datanode 上监听流式接口的请求,每当有 Client 发起流式接口请求时,DataXceiverServer 就会监听并接收这个请求,然后创建一个 DataXceiver 对象用于响应这个请求并执行对应的操作。

在 DataNode 的初始化代码中,会创建一个 DataXceiverServer 对象监听所有流式接口请求,Datanode 会调用 Datanode.initDataXceiver()方法来完成 DataXceiverServer 对象的构造~
二、源码
开始源码~

2.1. 实例化 TcpPeerServer
initDataXceiver() 方法会首先创建 TcpPeerServer 对象(对 ServerSocket 的封装),它能通过accept() 方法返回 Peer 对象(封装了 Socket 对象,提供通信的输入/输出流)TcpPeerServer
1 | TcpPeerServer tcpPeerServer; |
2.1.1. TcpPeerServer 是什么🤔️?
类似于ServerSocket,TcpPeerServer 对 ServerSocket 进行了封装,它能通过accept() 方法返回 Peer 对象(封装了 Socket 对象,提供通信的输入/输出流)TcpPeerServer

1 | public Peer accept() throws IOException, SocketTimeoutException { |
Peer 对象封装了 Socket 对象,提供通信的输入/输出流

2.1.2. 设置数据接收缓冲区大小
设置数据接收缓冲区大小,默认为 128KB
1 | tcpPeerServer.setReceiveBufferSize(HdfsConstants.DEFAULT_DATA_SOCKET_SIZE); |
2.1.3. 获取 Socket 地址
通过 tcpPeerServer 获取 Socket 地址 InetSocketAddress,赋值给 DataNode 成员变量 streamingAddr
1 | streamingAddr = tcpPeerServer.getStreamingAddr();//50010 |
2.2. 实例化 DataXceiverServer
DataXceiverServer 是数据节点 DataNode 上一个用于接收数据读写请求的后台工作线程,为每个数据读写请求创建一个单独的线程去处理。它提供了一请求一线程的模式,并对线程数目做了控制,对接收数据读写请求时发生的各种异常做了很好的容错处理,特别是针对内存溢出异常,允许等待短暂时间再继续提供服务,避免内存使用高峰期等等。
1 | xserver = new DataXceiverServer(tcpPeerServer, conf, this); |
在当前的构造参数中主要做 DataXceiverServer 中的成员变量的设置包括
peerServer
PeerServer 是一个接口,实现了它的 TcpPeerServer 封装了一个 ServerSocket,提供了 Java Socket 服务端的功能
根据传入的 peerServer 设置同名成员变量
datanode
maxXceiverCount
设置DataNode中DataXceiver的最大数目 maxXceiverCount
取参数 dfs.datanode.max.transfer.threads,参数未配置的话,默认值为 4096
estimateBlockSize
设置估计块大小 estimateBlockSize,取参数
dfs.blocksize,默认 128MbalanceThrottler
设置集群平衡节流器
1
2
3
4
5
6
7this.balanceThrottler = new BlockBalanceThrottler(
// 带宽取参数 dfs.datanode.balance.bandwidthPerSec,参数未配置默认为 1024*1024
conf.getLong(DFSConfigKeys.DFS_DATANODE_BALANCE_BANDWIDTHPERSEC_KEY,
DFSConfigKeys.DFS_DATANODE_BALANCE_BANDWIDTHPERSEC_DEFAULT),
// 最大线程数取参数 dfs.datanode.balance.max.concurrent.moves,参数未配置默认为 5
conf.getInt(DFSConfigKeys.DFS_DATANODE_BALANCE_MAX_NUM_CONCURRENT_MOVES_KEY,
DFSConfigKeys.DFS_DATANODE_BALANCE_MAX_NUM_CONCURRENT_MOVES_DEFAULT));
2.3. 构造 dataXceiverServer 守护线程
构造 dataXceiverServer 守护线程,并将 xserver 加入线程组 threadGroup
1 | this.dataXceiverServer = new Daemon(threadGroup, xserver); |
DataXceiverServer 的功能都是在 run() 方法中实现的。run() 循环调用 peerServer 的 accept() 方法监听,如果有新的连接请求则创建 Peer 对象,并构造一个 DataXceiver 线程服务这个流式请求,也就是 DataXceiverServer 只负责连接的建立以及构造并启动 DataXceiver,流式接口请求则是由 DataXceiver 响应的,真正的操作都是由 DataXceiver 来进行的。
监听
阻塞,直到接收到客户端或者其他 DataNode 的连接请求,如果有新的连接请求则创建 Peer 对象
1
peer = peerServer.accept();
确保 DataXceiver 数目没有超过最大限制
判断当前 DataNode 上 DataXceiver 线程数量是否超过阈值,如果超过的话,直接抛出IOException,利用IOUtils的cleanup()方法关闭peer后继续循环,否则继续 3
1
2
3
4
5int curXceiverCount = datanode.getXceiverCount();
if (curXceiverCount > maxXceiverCount) {
throw new IOException("Xceiver count " + curXceiverCount + " exceeds the limit of concurrent xcievers: "
+ maxXceiverCount);
}创建一个后台线程 DataXceiver,并将其加入到 Datanode的 线程组 threadGroup 中,并启动该线程,响应数据读写请求
1
new Daemon(datanode.threadGroup, DataXceiver.create(peer, datanode, this)).start();
DataXceiverServer 主要用于监听并接收流式请求,然后创建并启动 DataXceiver 对象。DataXceiver 的执行逻辑主要是在 run() 方法中完成的。
在 dataXceiverServer 中增加 peer 与该 DataXceiver 实例所在线程和 DataXceiver 实例的映射关系
1
dataXceiverServer.addPeer(peer, Thread.currentThread(), this);
设置写超时时间
1
peer.setWriteTimeout(datanode.getDnConf().socketWriteTimeout);
获取输入输出流
根据传入的 Peer 对象获取此层网络的输入/输出流,并对输入/输出流进行装饰,然后调用父类 Receiver 的 initialize() 方法执行初始化操作。
1
2
3
4
5
6
7
8
9
10
11
12IOStreamPair saslStreams = datanode.saslServer.receive(peer, socketOut,
socketIn, datanode.getXferAddress().getPort(),
datanode.getDatanodeId());
// 包装 saslStreams 的输入流 in 为 BufferedInputStream,得到输入流 input,
// 其缓冲区大小取参数 io.file.buffer.size 的一半,
// 默认为 512,且最大也不能超过 512
input = new BufferedInputStream(saslStreams.in, HdfsConstants.SMALL_BUFFER_SIZE);
// 从 saslStreams 中获取输出流 socketOut
socketOut = saslStreams.out;
//...
// 调用父类 initialize() 方法,完成初始化,实际上就是设置父类的输入流 in
super.initialize(new DataInputStream(input));设置读超时时间
第一次创建一个新的 socket 使用,连接的时间可能会很长,所以连接超时时间设置的比较大,后续使用的话,是复用socket,连接的超时时间限制就没必要设置那么大了~~~
1
2
3
4
5if (opsProcessed != 0) {
peer.setReadTimeout(dnConf.socketKeepaliveTimeout);//4s
} else {
peer.setReadTimeout(dnConf.socketTimeout);//60s
}读取操作符 op
1
op = readOp();
Op 是一个枚举类型,使用一个 byte 类型的变量 code 标识操作码。一个操作码对应 DataTransferProtocol 接口中的一个方法,例如操作码 80对应 DataTransferProtocol.writeBlock()
1
2
3
4
5
6
7
8
9public enum Op {
WRITE_BLOCK((byte)80),
READ_BLOCK((byte)81),
READ_METADATA((byte)82),
REPLACE_BLOCK((byte)83),
COPY_BLOCK((byte)84),
BLOCK_CHECKSUM((byte)85),
// ...
}根据操作符 op 调用相应的方法处理操作符 op
1
processOp(op);

2.4. 构造短路读注册实例
DataNode 会创建一个 localDataXceiverServer 响应本地的短路读取请求。
1 | this.shortCircuitRegistry = new ShortCircuitRegistry(conf); |
Hadoop 的一大基本原则是移动计算的开销要比移动数据的开销小。因此,Hadoop通常是尽量移动计算到拥有数据的节点上。这就使得Hadoop中读取数据的客户端DFSClient和提供数据的Datanode经常是在一个节点上,也就造成了很多“Local Reads”。

短路读关键思想是因为客户端和数据块在同一节点上,所以DataNode不需要出现在读取数据路径中。而客户端本身可以直接从本地磁盘读取数据。这样会使读取性能得到很大的提高。在以前实现的短路读是 DataNode 将所有数据块路径的权限开放给客户端,客户端直接通过本地磁盘路径来读取数据。

所谓的“短路”读取绕过了 DataNode,从而允许客户端直接读取文件。显然,这仅在客户端与数据位于同一机器的情况下才可行。短路读取为许多应用提供了显着的性能提升。
 微信
微信 支付宝
支付宝