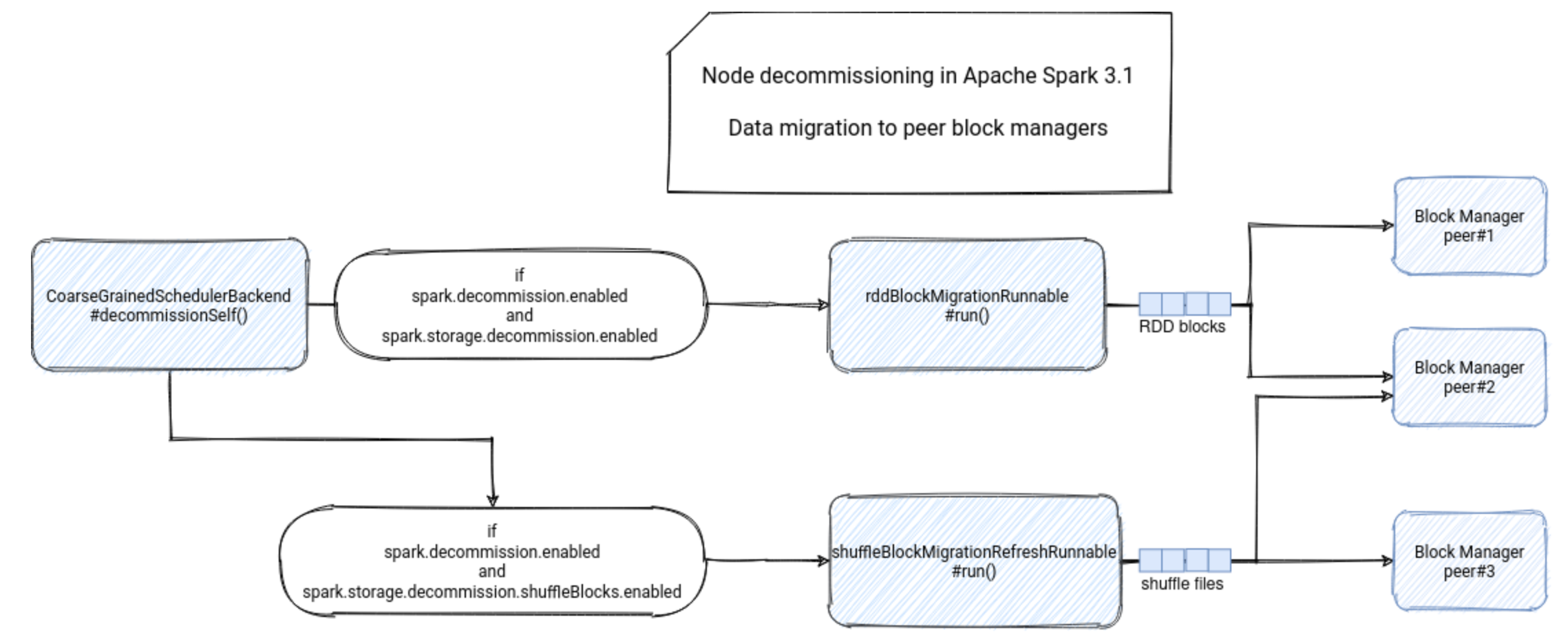
Hadoop-组件-HDFS-源码学习-集群启动-NameNode 启动设计
一、概述
NameNode 是 Hadoop 分布式文件系统的核心,架构中的主角色。它维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。基于此,NameNode 成为了访问 HDFS 的唯一入口。
我们详细看看 HDFS NameNode 启动流程~~~
二、源码
通过这个 start-dfs.sh 启动脚本,找到了 hdfs

最终将 Namenode 启动类定位在 org.apache.hadoop.hdfs.server.namenode.NameNode

来到 org.apache.hadoop.hdfs.server.namenode.NameNode 的 main() 方法中,开始调试~~~

2.1. 前置操作
2.1.1. 参数校验
1 | if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)) { |
通过脚本来执行 Namenode#main() 一进来对我们当前这个参数呢作一个合法化的校验,如果参数不合法退出
2.1.2. 打印启动日志
1 | StringUtils.startupShutdownMessage(NameNode.class, argv, LOG); |
紧接者 main() 打印启动时候参数信息。在启动 Hadoop 的时候打印了非常多的 info 信息,CPU 、内存啊等等这些东西就是这个方法打印的。

2.2. 创建 NameNode
main() 方法调用 createNameNode() 创建一个 NameNode 对象,创建成功后调用 NameNode.join() 方法等待 RPC 服务结束。
1 | NameNode namenode = createNameNode(argv, null); |
createNameNode() 方法会根据启动 Namenode 时传入的启动选项,调用对应的方法执行操作。switch 里面会根据传入的参数执行不同的逻辑,默认不加参数的,也就是启动 NameNode,在最后的 default 逻辑里面,会创建 NameNode 对象

FORMAT: 格式化当前 Namenode
FINALIZE: 提交上一次升级
目前 Namenode 命令不再支持 -finalize 选项,建议用户使用 hdfs dfsadmin-finalizeUpgrade 命令进行提交操作。
ROLLBACK: 回滚上一次升级
BOOTSTRAPSTANDBY: 复制 Active Namenode 的最新命名空间数据到 StandbyNamenode
INITIALIZESHAREDEDITS:
初始化 editlog 的共享存储空间,并从 Active Namenode 中复制足够的 editlog 数据,使得 Standby Namenode 能够顺利启动。
BACKUP: 启动 backup 节点,直接构造一个 BackupNode 对象并返回。
CHECKPOINT: 启动 checkpoint 节点,也是直接构造 BackupNode 对象并返回。
RECOVER: 恢复损坏的元数据以及文件系统。
默认: 正常启动 NameNode
1
2
3
4
5
6//正常启动NameNode
default: {
//初始化 metric 系统
DefaultMetricsSystem.initialize("NameNode");
return new NameNode(conf);
}
NameNode 的构造方法首先解析配置文件,确认当前 Namenode 是否开启了 HA,然后调用 initialize() 方法初始化 NameNode 对象,初始化完成后进入 Standby 状态。
如果出现异常,则调用 NameNode.stop() 方法停止 Namenode 服务。

2.3.1. 构造方法
conf
role: 保存 NameNode 的角色信息
nsId
namenodeId
haEnabled: 根据配置确认是否开启了 HA
1
this.haEnabled = HAUtil.isHAEnabled(conf, nsId);
state: 根据用户设置的启动参数,确定初始状态

如果是正常启动,则全部直接进入 Standby 状态初始启动的 Namenode 都处于 Standby 状态
allowStaleStandbyReads
haContext: 在创建 HA 的时候,也启动了 standByNameNode 的服务
1
this.haContext = createHAContext();
注意:这个很重要,等会还要过来专门看它源码哦~
2.3.2. initializeGenericKeys(conf, nsId, namenodeId)
设置联邦模式下 Namenode 的地址和 RPC 地址
2.3.3. initialize(conf)
NameNode.initialize() 主要负责构造 HTTP 服务器和 RPC 服务器,初始化FSNamesystem 对象,最后调用 startCommonServices()启动 HTTP 服务器、RPC 服务器。
权限设置
1
2
3
4
5
6// 设置权限,根据 hadoop.security.authentication 获取认证方式及规则
UserGroupInformation.setConfiguration(conf);
// 登录:如果认证方式为simple则退出该方法
// 否则调用 UserGroupInformation.loginUserFromKeytab 进行登陆,
// 登陆使用 dfs.namenode.kerberos.principal 作为用户名
loginAsNameNodeUser(conf);启动 Http 服务
启动 Namenode上的 http 服务~~~
1
startHttpServer(conf);
引用本站文章Hadoop-组件-HDFS-源码学习-集群启动-NameNode 启动-startHttpServerJoker既然启动 NameNode上的 Http 服务由 startHttpServer() 负责,为啥我们还是无法访问 localhost:50071(默认是50070)呢?

因为 hdfs 页面上的元数据信息,我们还需要去加载元数据才可以展示,看下一步加载元数据~~~
初始化 FSNamesystem
Namenode 启动时从本地文件系统加载镜像并重做编辑日志
1
loadNamesystem(conf);
引用本站文章Hadoop-组件-HDFS-源码学习-集群启动-NameNode 启动-loadNamesystemJoker创建 Hadoop 的 RPC 服务
Namenode 会在它的初始化方法 initialize() 中调用 createRpeServer() 创建 NameNodeRpcServer 对象的实例,createRpcServer() 方法会直接调用 NameNodeRpcServer 的构造方法。
1
rpcServer = createRpcServer(conf);
引用本站文章Hadoop-组件-HDFS-源码学习-集群启动-NameNode 启动-createRpcServerJoker启动公共服务
启动一些公共服务,NameNode 的 RPC 服务就是在这里启动
1
startCommonServices(conf);
引用本站文章Hadoop-组件-HDFS-源码学习-集群启动-NameNode 启动-startCommonServicesJoker
三、总结
Namenode 的启动 main() 方法首先调用 createNameNode() 创建 NameNode 对象,创建成功后调用 NameNode.join() 方法等待 RPC 服务结束。
createNameNode() 首先解析配置文件,确认当前 Namenode 是否开启了 HA,然后调用 initialize() 方法初始化 NameNode 对象,初始化完成后进入 Standby 状态。如果出现异常,则调用 NameNode.stop() 方法停止 Namenode 服务。
NameNode.initialize() 构造 HTTP 服务器和 RPC 服务器,初始化 FSNamesystem 对象,最后调用 startCommonServices() 启动 HTTP 服务器、RPC 服务器。
至此,NameNode 就已经成功地启动了,但是 NameNode 将对文件系统的管理都委托给了 FSNamesystem 对象,NameNode 会调用 FSNamesystem.loadFromDisk() 创建 FSNamesystem 对象。FSNamesystem.loadFromDisk() 首先调用构造方法构造 FSNamesystem 对象,然后将 fsimage 以及 editlog 文件加载到命名空间中。

 微信
微信 支付宝
支付宝