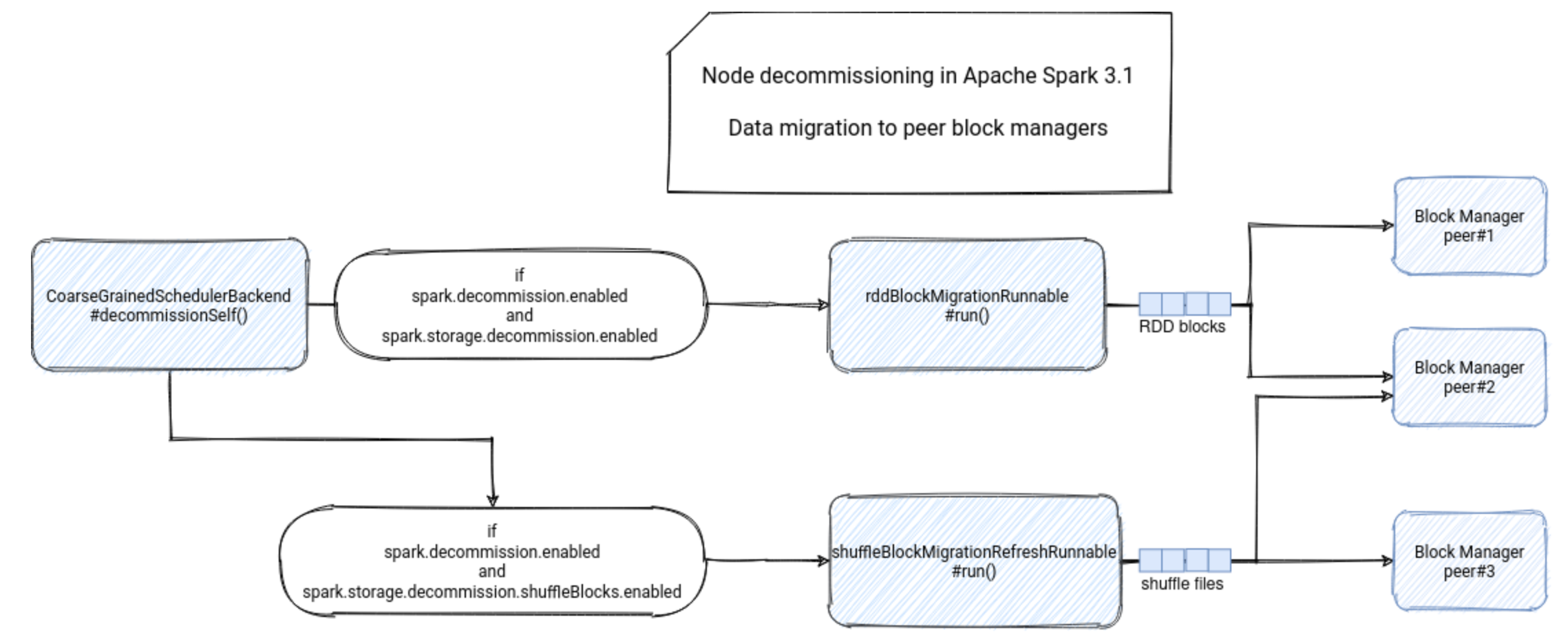
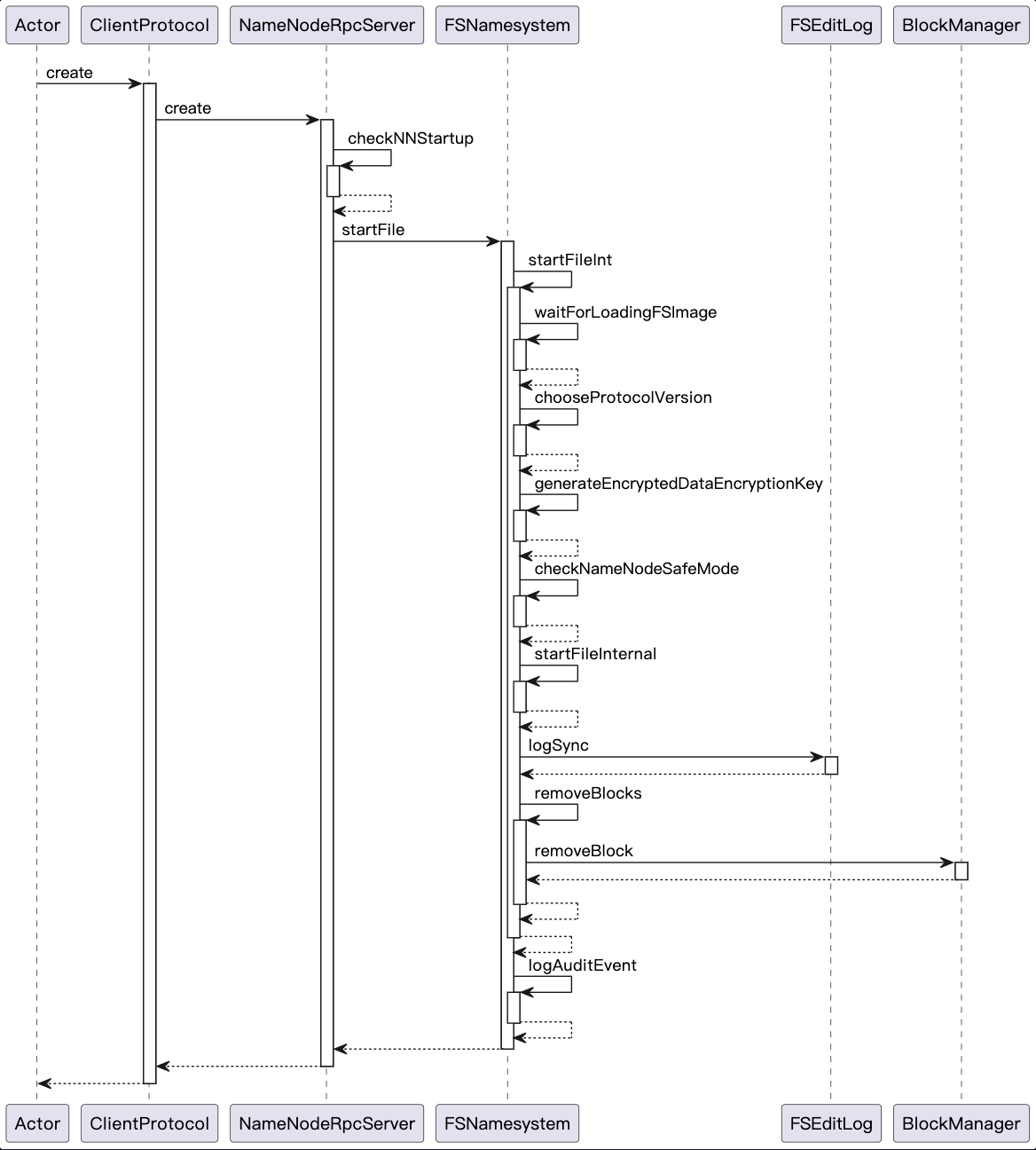
Hadoop-组件-HDFS-源码学习-数据读写-写文件-上传-创建文件
客户端在执行文件写操作前,首先需要调用 DistributedFileSystem.create() 创建一个空的 HDFS 文件,并且获取这个 HDFS 文件的输出流 HdfsDataOutputStream 对象。获取输出流对象后,客户端就可以在输出流 HdfsDataOutputStream 对象上调用 write() 方法执行写操作了。
一、概述
二、实现
客户端在执行文件写操作前,首先需要调用 DistributedFileSystem.create() 创建一个空的HDFS 文件,并且获取这个 HDFS 文件的输出流 HdfsDataOutputStream 对象。成功获取到输出流对象后,客户端就可以在输出流 HdfsDataOutputStream 对象上调用 write() 方法执行写操作了。
2.1. Namenode 文件目录树更新-创建文件
Namenode 作 为 HDFS 的大脑实现 了 ClientProtocol 、 DatanodeProtocol 以及 NamenodeProtocol 等远程接口,ClientProtocol 实现了与读写相关的方法在 Namenode 中的实现,包括创建文件、追加写文件、创建新的数据块、放弃数据块以及关闭文件等操作。
1 | stat = dfsClient.namenode.create(src, masked, dfsClient.clientName, |
2.2. 构造输出流
DFSOutputStream 扩展自抽象类 FSOutputSummer, FSOutputSummer 在 OutputStream 的基础上提供了写数据并计算校验和的功能,DFSOutputStream.write() 方法的实现就继承自 FSOutputSummer 类。
1 | final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat, |

2.2.1. 设置数据包 DFSPacket 参数
DFSOutputStream 中使用 DFSPacket 类来封装一个数据包。一个完整的数据包结构如图所示。首先是数据包包头,记录了数据包的概要属性信息,然后是校验和数据,最后是校验块数据。每个数据包中都包含若干个校验块,以及校验块对应的校验和。

通过 computePacketChunkSize 方法设置数据包的一些参数信息。
1 | private void computePacketChunkSize(int packetSize, int chunkDataSize) { |
2.2.2. 创建 DataStreamer
负责 pipeline 数据流管道,负责将数据包发送到 pipeline 中 第一个 datanode
1 | streamer = new DataStreamer(stat, null); |
2.3. 启动 streamer 线程
启动 DFSOutputStream 的内部类 DataStreamer 线程,用于接收要写入的数据包
1 | out.start(); |
 微信
微信 支付宝
支付宝