Hadoop-组件-HDFS-源码学习-元数据管理-checkpoint-editLogTailer 线程
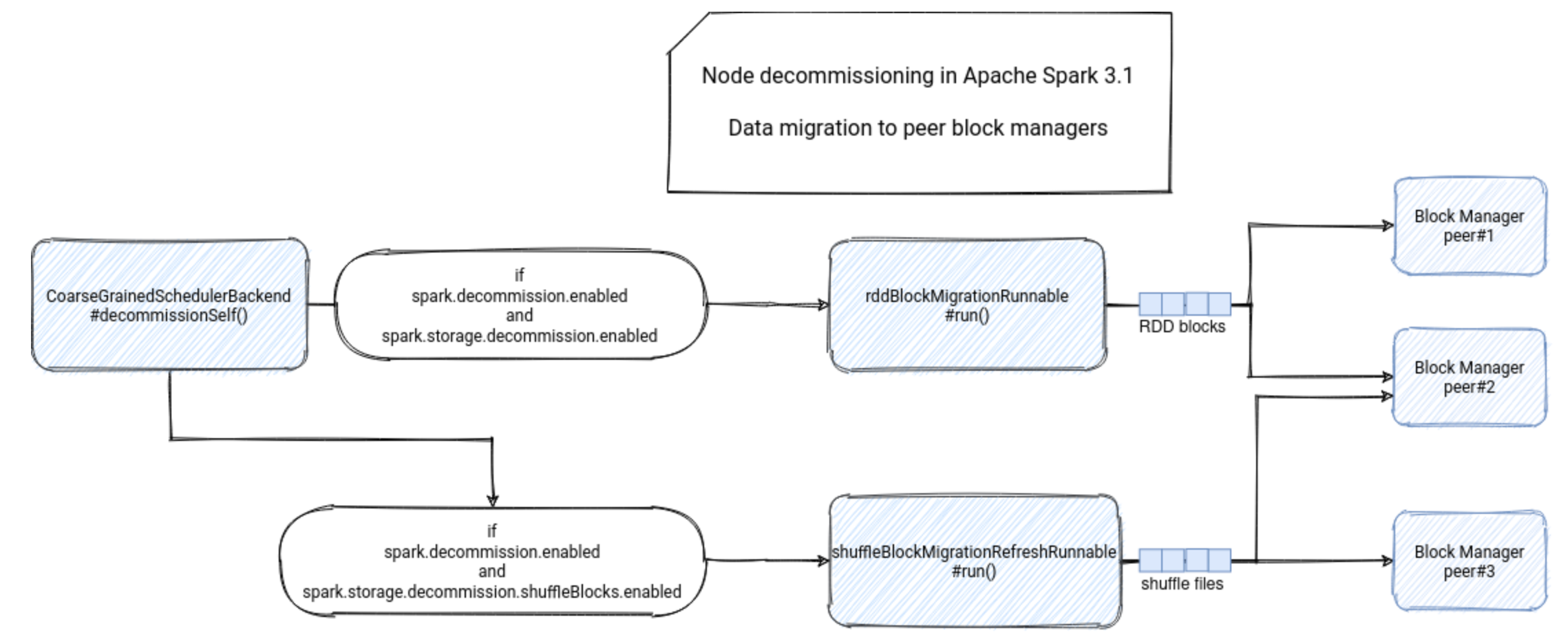
HDFS 会定时将 editlog 文件与 fsimage 文件合并以产生新的 fsimage 文件。Namenode 可以直接从 fsimage 加载元数据,而不用读取与合并 editlog 中的记录了。Namenode 命名空间的重建效率会大大提高,同时 Namenode 的启动时间也会相应减少。但是合并 fsimage 与editlog 以产生新的fsimage 文件是一项非常消耗 I/O 和 CPU 资源的操作。在执行检查点操作期间,Namenode 还需要限制其他用户对 HDFS 的访问和操作。为了预防这种情况的发生,HDFS 将检查点操作从Active Namenode 移动到 StandbyNamenode
Editlog 文件会变得非常大,甚至将磁盘空间写满。在 Namenode启动过程中一个很重要的部分就是逐条读取editlog文件中的记录,之后与 Namenode 命名空间合并。巨大的 editlog 文件会导致 Namenode 的启动时间过长,为了解决这个问题,HDFS引入了检查点机制
一、概述
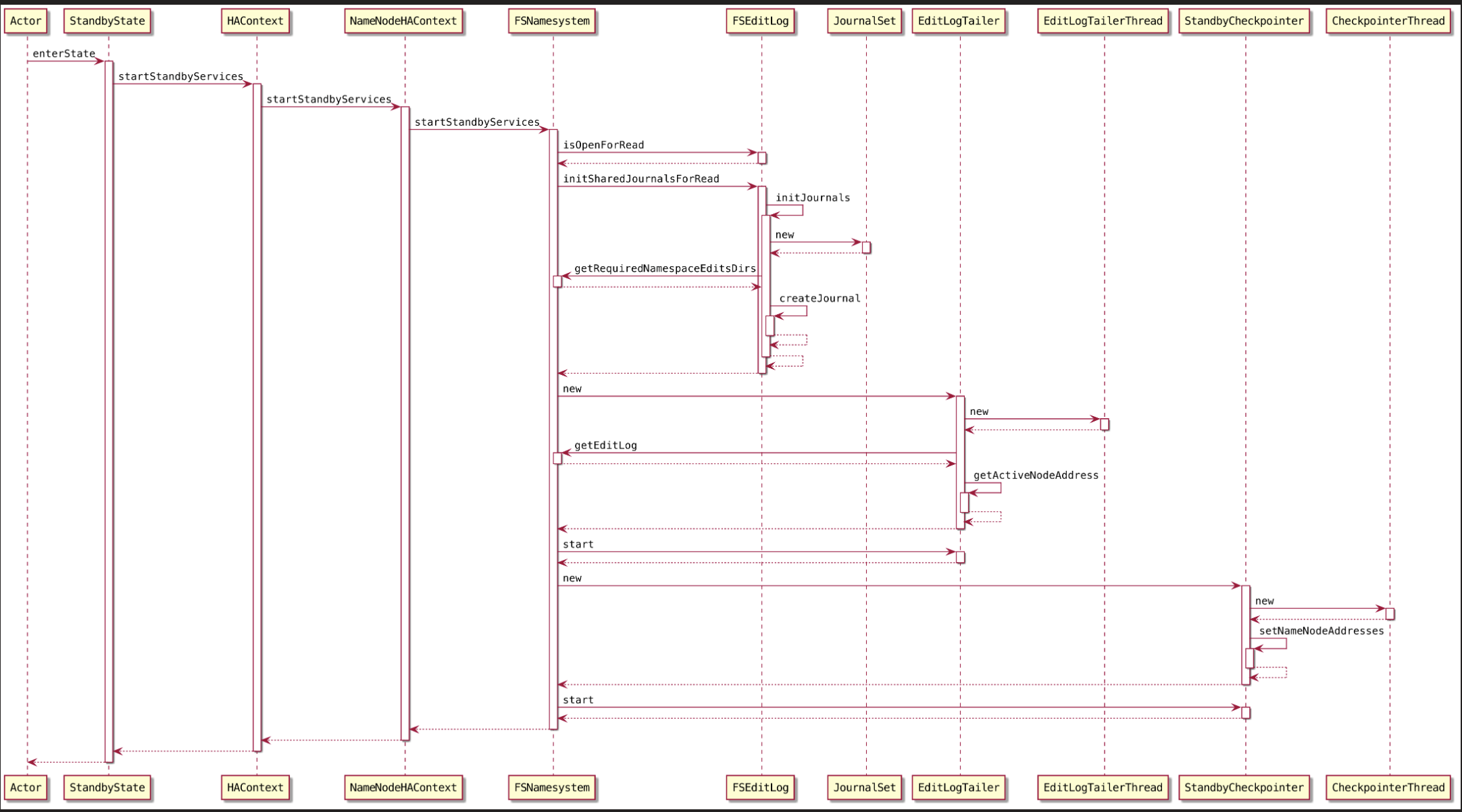
变量初始化
tailerThread
实例化 EditLogTailerThread
conf
namesystem
editLog
从 NameSystem 中获取 editLog
lastLoadTimeMs
最新加载 edit log 时间 lastLoadTimestamp 初始化为当前时间
logRollPeriodMs
StandBy NameNode 滚动编辑日志的时间间隔 logRollPeriodMs
activeAddr
1
2
3
4
5
6if (logRollPeriodMs >= 0) {
// 调用 getActiveNodeAddress() 方法初始化 Active NameNode 地址activeAddr
this.activeAddr = getActiveNodeAddress();
} else {
...
}sleepTimeMs
StandByNameNode 检查是否存在可以读取的新的最终日志段的时间间隔 sleepTimeMs,取参数 dfs.ha.tail-edits.period,参数未配置默认为 1 min

start()
start() 方法中启动了EditLogTailer 线程, StandbyNameNode 使用 EditLogTailer 线程来负责向远程的 QuorumJournalNode 读取新的EditLog文件
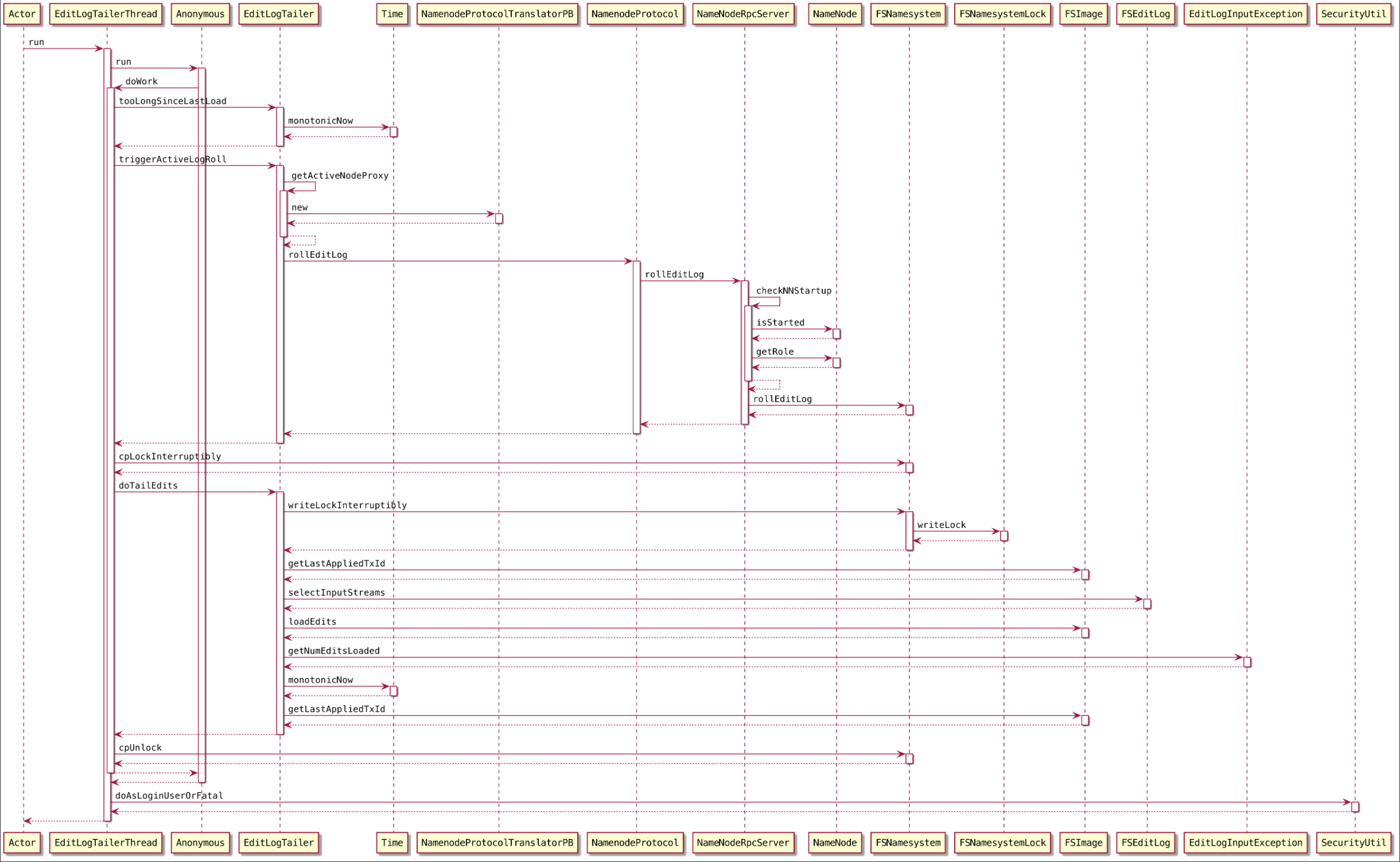
滚动条件
1
2
3if (tooLongSinceLastLoad() && lastRollTriggerTxId < lastLoadedTxnId) {
...
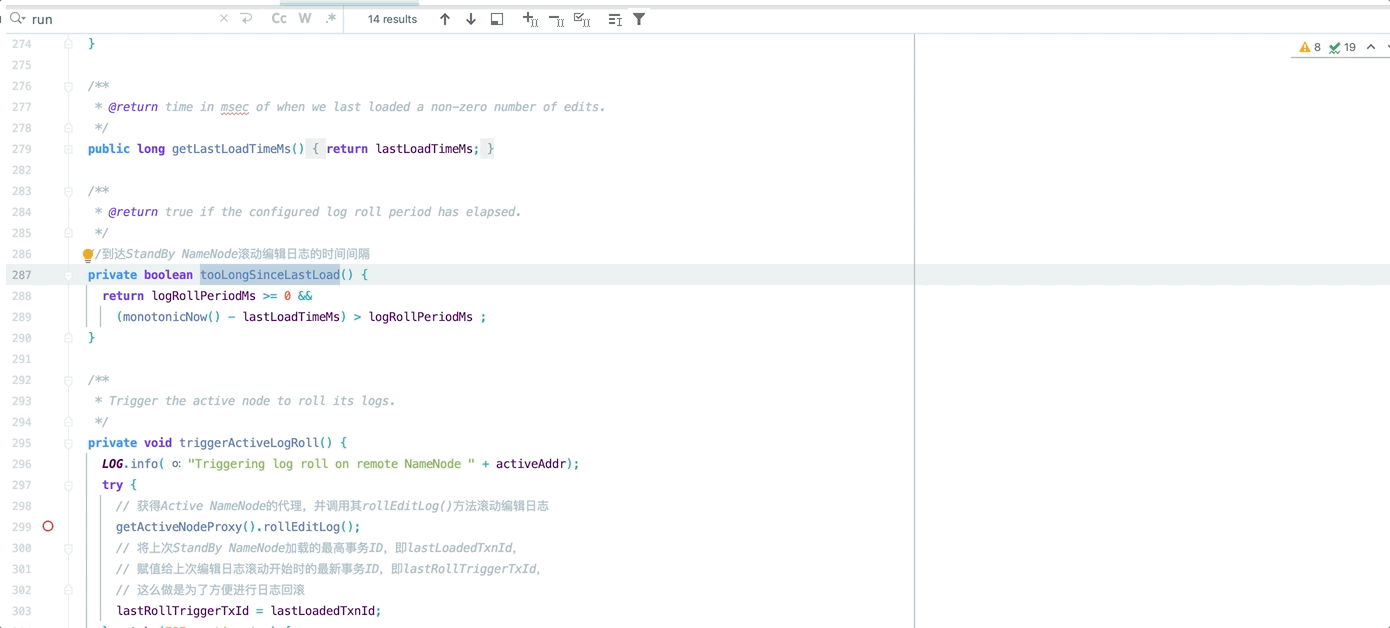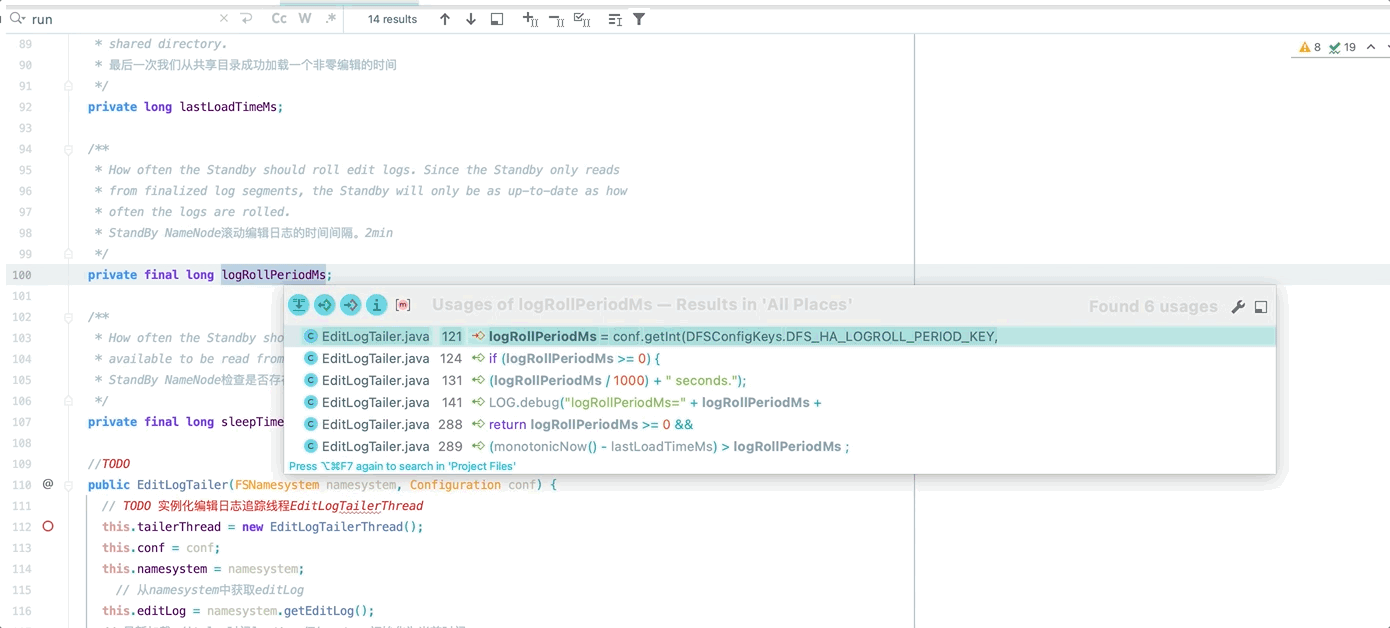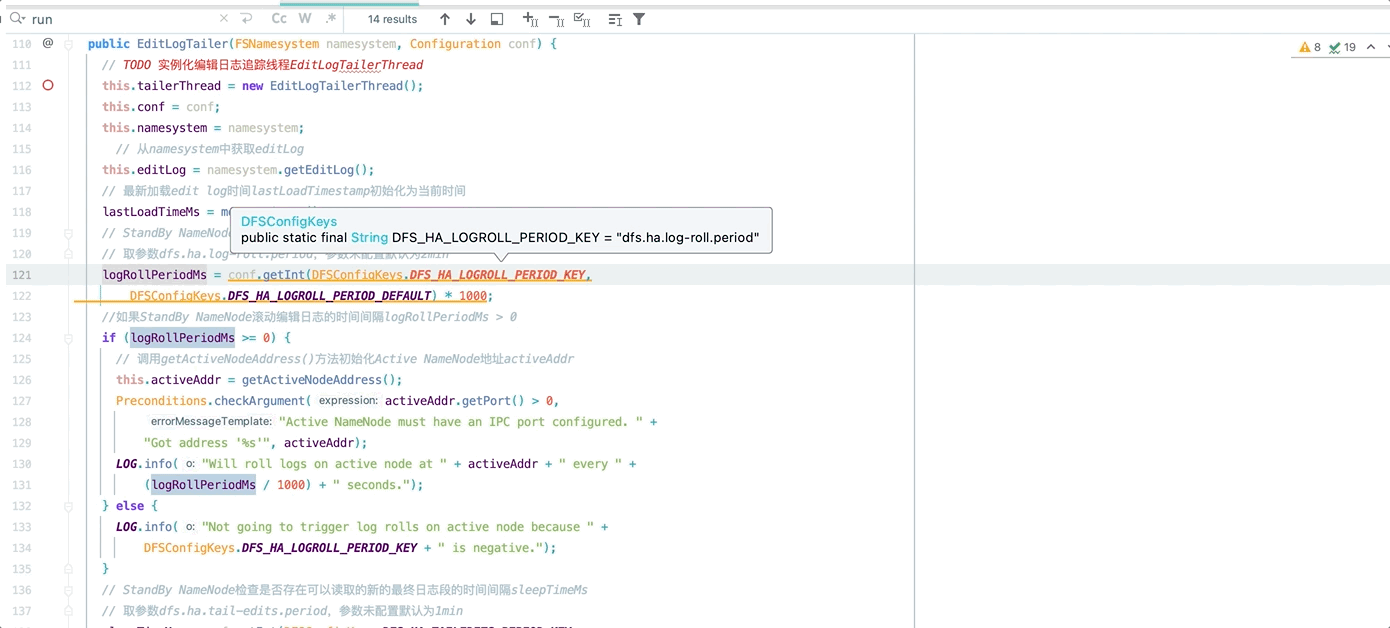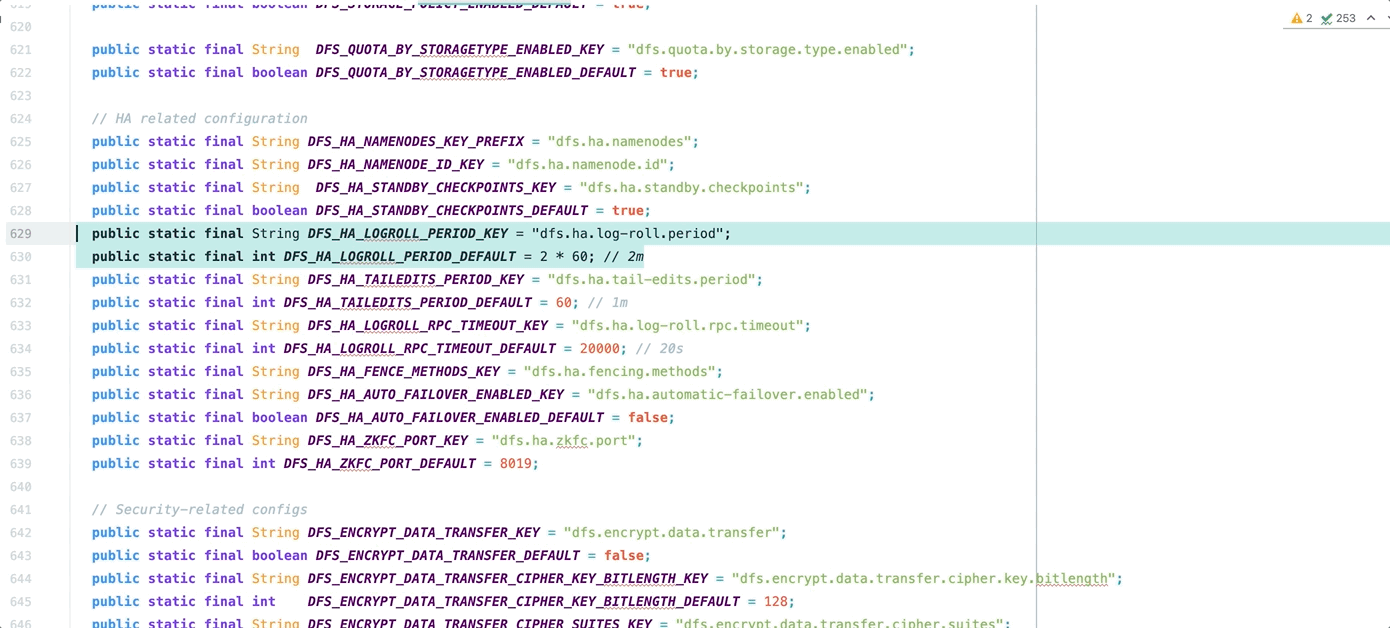
}达到 StandByNameNode 滚动编辑日志的时间间隔(2min)
1
2
3
4private boolean tooLongSinceLastLoad() {
return logRollPeriodMs >= 0 &&
(monotonicNow() - lastLoadTimeMs) > logRollPeriodMs ;
}
上一次编辑日志滚动开始时的最新事务ID < StandBy NameNode加载的最高事务ID
1
lastRollTriggerTxId < lastLoadedTxnId
roll 操作
NameNode roll操作会告知 QJM 也进行roll操作,这样,Standby Namenode就可以拉取到这个segment
1
2
3
4
5
6
7
8private void triggerActiveLogRoll() {
try {
getActiveNodeProxy().rollEditLog();
lastRollTriggerTxId = lastLoadedTxnId;
} catch (IOException ioe) {
LOG.warn("Unable to trigger a roll of the active NN", ioe);
}
}获得 ActiveNameNode 的代理,并调用其 rollEditLog() 方法滚动编辑日志
检查 NameNode 是否已经启动
1
checkNNStartup();
检查权限
1
namesystem.checkSuperuserPrivilege();
滚动 edits
1
namesystem.rollEditLog();
检查权限操作
检查状态
1
checkOperation(OperationCategory.JOURNAL);
检查当前 NameNode 是否是安全模式
回滚
1
getFSImage().rollEditLog();
双缓冲写日志
1
getEditLog().rollEditLog();
把处于正在写入的 editlog 文件变成完整的
1
endCurrentLogSegment(true);
获取最新的事务ID+1
开始给下一个edit文件命名
1
long nextTxId = getLastWrittenTxId() + 1;
创建 editLogStream
这个流会在刷元数据的时候使用到
1
startLogSegment(nextTxId, true);
方法调用了 journalSet.startLogSegment() 方法在所有 editlog 文件的存储路径上构造输出流,并将这些输出流保存在 FSEditLog 的字段journalSet.journals 中。
journalSet 的 journals 字段是一个 JournalAndStream 对象的集合,这个集合中的每一个 JournalAndStream 对象都封裝了一个 JournalManager,以及这个 JournalManager 打开的 editlog 文件的输出流
startLogSegment()方法最后会将 FSEditlog.curSegmentTxId 字段(FSEditlog 当前正在写入 txid) 设置为传入的segmentTxid, 同时将 editlog 的状态更改为 IN_SEGMENT 状态。
1
2curSegmentTxId = segmentTxId;
state = State.IN_SEGMENT;
将当前事务ID记录到
dfs/name/current/seen_txid里面,这个 id 就是当前 edit 文件的名称:fsimage_00000000000000000031
storage.writeTransactionIdFileToStorage(getEditLog().getCurSegmentTxId());
将上次 StandByNameNode加载的最高事务ID赋值给上次编辑日志滚动开始时的最新事务ID
1
lastRollTriggerTxId = lastLoadedTxnId
拉取远程的 segment 文件
1
doTailEdits()
加锁
加载 fsimage
1
FSImage image = namesystem.getFSImage();
获取最新的事务ID
1
long lastTxnId = image.getLastAppliedTxId();
得到 JournalNode 上 editlog 的输入流
FSEditLog 会调用 QuorumJournalManager.selectInputStreams0 方法打开共享存储上的 editlog 文件,selectlnputStreams() 方法首先会发送 RPC 请求 QJournalProtocol.getEditLogManifest() 到集群中的所有 JournalNode 上,以获取集群中所有 JournalNode 上保存的 editlog 段落文件信息。之后对于 JournalNode上保存的每一个 editlog文件,selectInputStreams() 都会构造一个EditLogFilelnputStream 对象,然后将这些对象都封装在一个 RedundantEditLogInputStream 输入流对象中。
1
streams = editLog.selectInputStreams(lastTxnId + 1, 0, null, false);
Standby Namenode 就可以使用 RedundantEditLogInputStream 从任意一个 JournalNode 上读取每个 editlog 段落了。如果其中一个JournalNode 失败了,RedundantEditLogInputStream 会自动切换到另一个保存了这个 editlog 段落的 JournalNode 上。
去 JournalNode 上加载日志
1
2
3
4
5editsLoaded = image.loadEdits(streams, namesystem);
if (editsLoaded > 0) {
//更新最后一次我们从共享目录成功加载一个非零编辑的时间
lastLoadTimeMs = monotonicNow();
}标识当前进度为加载edit log文件
1
2StartupProgress prog = NameNode.getStartupProgress();
prog.beginPhase(Phase.LOADING_EDITS);加载edit log最新事务ID
1
long prevLastAppliedTxId = lastAppliedTxId;
FSEditLogLoader负责对当前这一轮的多个stream(editStreams)进行读取并加载到内存
1
FSEditLogLoader loader = new FSEditLogLoader(target, lastAppliedTxId);
- fsNamesys
- lastAppliedTxId
loadFSEdits
loader 会不断从远程读取新的 op,同时从 op 中提取 txId 来更新自己的 txId,从而让 StandbyNamenode 的 txid 逐渐向前递增, 从loader中获取当前已经 load 过来的最新的 txId, 更新到 FSImage 对象,用 lastAppliedTxId 记录当前已经成功读取并加载的位置
这样,当 EditLogTailer 的下一轮运行开始的时候,就从这个 lastAppliedTxId 开始请求 edit log 文件,因为这个位置之前的操作已经完成了同步和加载。对应—>FSEditLogLoader loader = new FSEditLogLoader(target, lastAppliedTxId);1
2
3
4
5try {
loader.loadFSEdits(editIn, lastAppliedTxId + 1, startOpt, recovery);
} finally {
lastAppliedTxId = loader.getLastAppliedTxId();
}- 标识进度
Phase.LOADING_EDITS
StartupProgress prog = NameNode.getStartupProgress(); Step step = createStartupProgressStep(edits); prog.beginStep(Phase.LOADING_EDITS, step);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- loadEditRecords
- op = in.readOp()
从编辑日志输入流 in 中读取操作符 op,如果操作符 op 为空,说明没有元数据,直接跳出循环,并返回
- applyEditLogOp()
在内存中将 edit 文件和 image 进行操作
- OP_MKDIR
创建目录日志,然后在内存中维护自己的元数据
- editIn.getLastTxId()
```java
if (editIn.getLastTxId() != HdfsConstants.INVALID_TXID) {
lastAppliedTxId = editIn.getLastTxId();
}记录同步过来的最后一个transactionId
1
lastLoadedTxnId = image.getLastAppliedTxId();
去除写锁
1
namesystem.writeUnlock();
 微信
微信 支付宝
支付宝