Hadoop-组件-HDFS-源码学习-元数据管理-持久化 EditLog-双缓存设计
数据在写入 editlog 文件前,会首先被写入到输出流的缓冲区中。EditLogFileOutputStream 的缓冲区用到了一个比较特殊的数据结构—Edits Double Buffer,这儿我们涉及到了一点源码修改哦~
一、概述
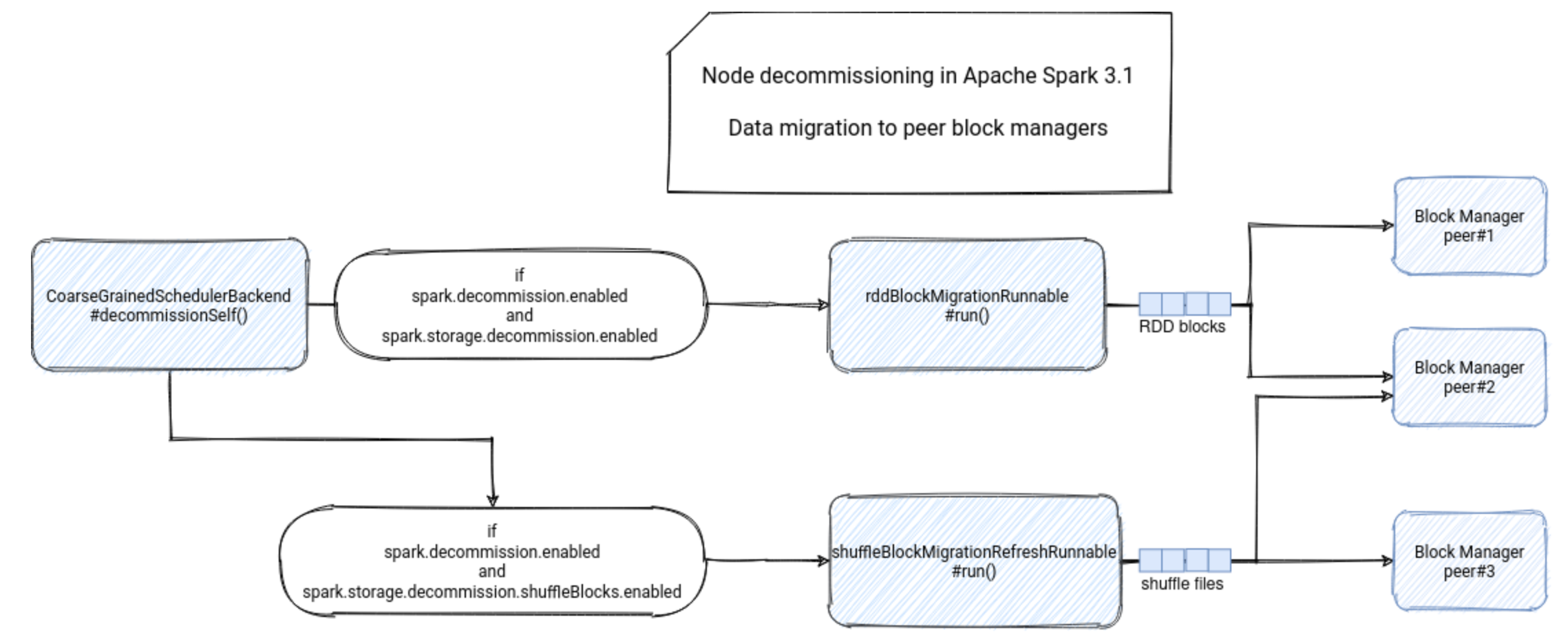
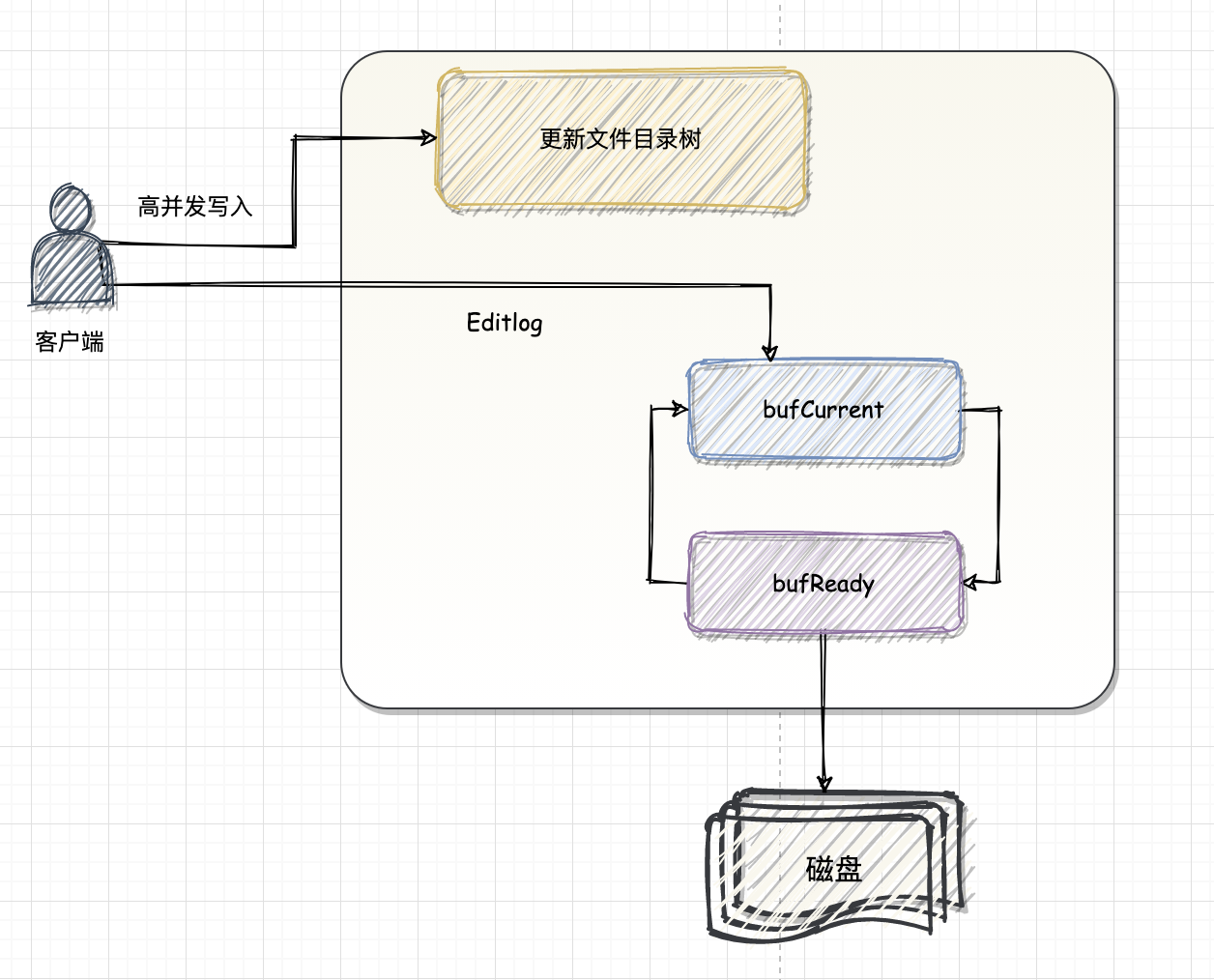
一块内存不能同时并发读写一块内存数据, 因此 HDFS 引入的双缓冲机制,把一块内存划分为两个部分, 将缓冲区分为 2 份,1份为当前缓冲区 buf current,另外 1 份为预写入分区 buf ready,两个缓冲区空间大小一致。current 区负责当前的写操作存放,当我们达到缓冲处罚条件时,执行一次双缓冲的调换操作。然后由另外的程序执行 ready 区的 flush 操作。被交换变为空缓冲区的 current 区重新用于这的数据写入。
以上的执行模式有以下2大优势:
- 程序无需反复进行创建新缓冲的操作
- 程序的写请求不会被阻塞住,除非current缓冲区已经满了同时ready缓冲区数据还没有全部flush出去
二、源码
2.1. EditLog
EditLog 类 是对 EditLog 日志的一个封装,属性 txid 和 content,分别是日志的事务id(保证唯一性)和 内容。
2.2. EditsDoubleBuffer
双缓冲类 EditsDoubleBuffer 在内存里面维护了两个有序的 LinkedList,分别是当前写编辑日志的缓冲和同步到磁盘的缓冲,其中的元素就是 EditLog 类。
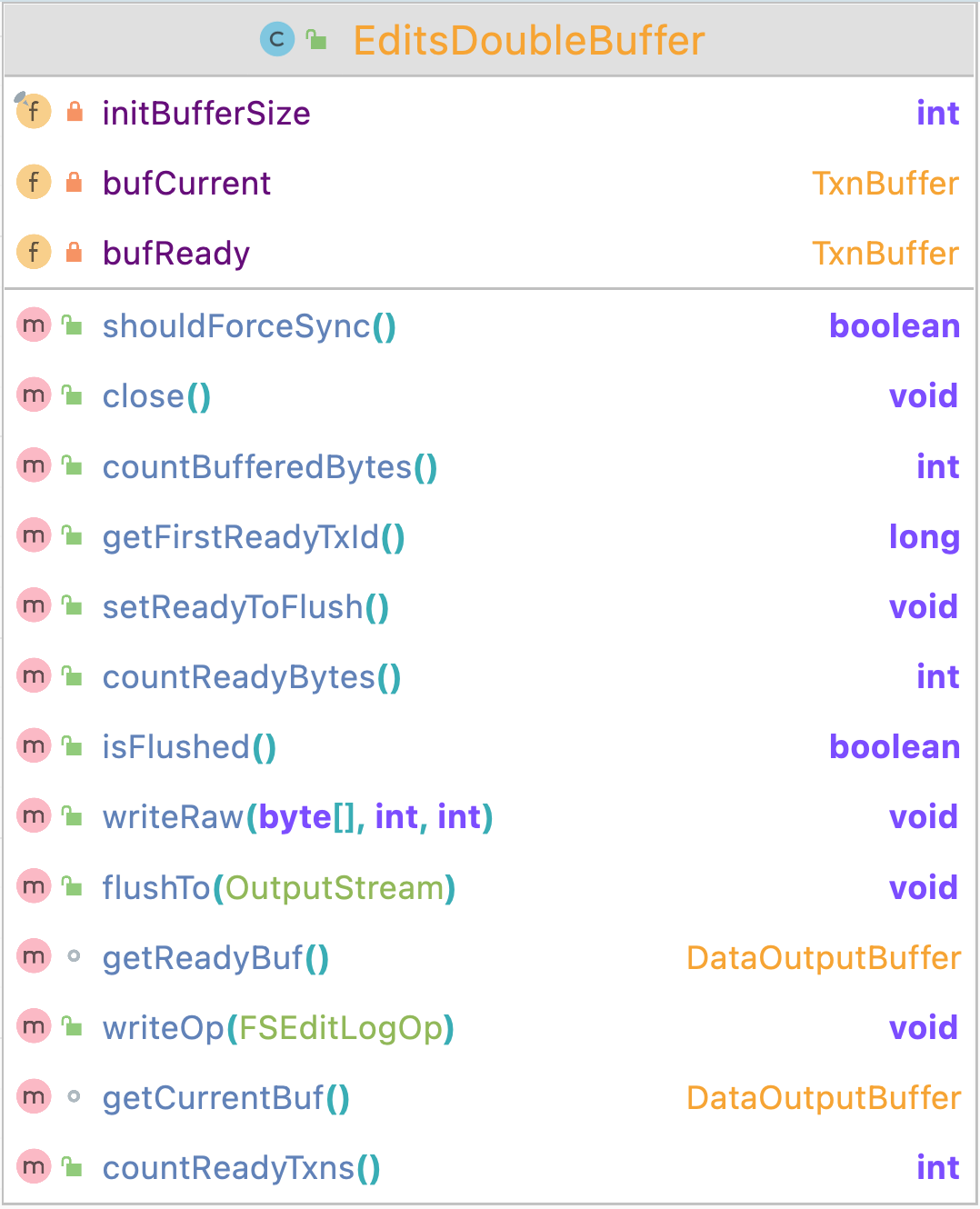
write() 方法就是把一条编辑日志写到当前缓存里。
setReadyToSync() 方法,交换两个缓存
getSyncMaxTxid ()方法,获得正在同步的那个缓存去里的最大的事务id。
flush() 方法,遍历同步的缓冲的每一条编辑日志,写到磁盘,并最终清空缓冲区内容。
2.3. 写数据
1 | // 将 edit 文件日志刷到磁盘 |
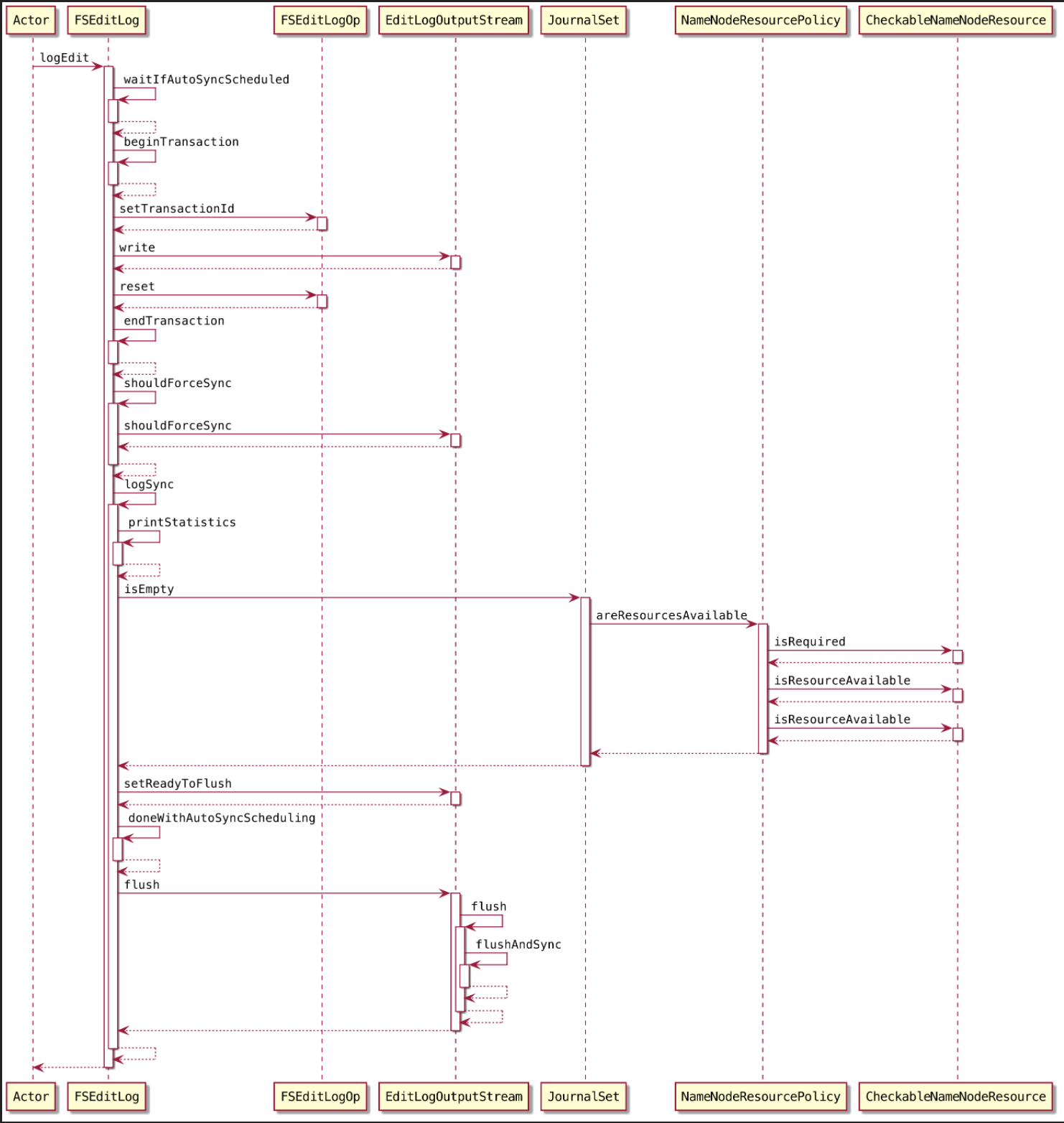
2.3.1. 等待
1 | waitIfAutoSyncScheduled(); |
如果当前操作被其他线程调度了,则等待1s时间(同步操作)
1 | synchronized void waitIfAutoSyncScheduled() { |
2.3.2. 获取事务 ID
1 | private long beginTransaction() { |
这儿我们在后面会改哦~~~
2.3.3. 将元数据信息写入内存
将元数据信息写入内存(其实内部就是往 bufCurrent写数据)
1 |
|
2.3.4. 将缓存的 EditLog 同步到持久性存储
logEdit() 方法通过调用 beginTransaction() 方法成功地获取一个 transactionld 之后,就会通过输出流向 editlog 文件写数据以记录当前的操作,但是写入的这些数据并没有直接保存在editlog 文件中,而是暂存在输出流的缓冲区中。所以当 logEdit()方法将一个完整的操作写入输出流后,需要调用 logSync() 方法同步当前线程对 editlog 文件所做的修改。
1 | logSync(); |
同一时间会有多个线程同时写 editlog 文件,所以 editlog 制订了以下同步策略。
- 所有的操作项同步地写入缓存时,每个操作会被赋予一个唯一的 transactionld。
- 在logSync() 方法中使用 isSyncRunning 变量标识当前是否有线程正在进行同步操作
logSync() 方法主要流程
获取当前线程 transactionld
当一个线程要将它的操作同步到 editlog 文件中时,logSync0方法会使用 ThreadLocal 变量 myTransactionld 获取该线程需要同步的 transactionld
1
long mytxid = myTransactionId.get().txid;
条件判断
采用了递增的事务 Id 来标识,通过最大事务 Id 保持刷盘顺序性,
如果当前工作的线程 > 最大事务ID 并且是同步状态,说明当前线程正处于刷盘状态。说明此事务正处于刷盘状态,则等待
1s如果 当前线程的 transactionld 大于 editlog 文件中的 transactionld,则表明 editlog 文件中记录的数据不是最的,同时如果当前没有别的线程执行同步操作,则开始同步操作将输出流缓存中的数据写入 editlog 文件中。
1
2
3
4
5
6while (mytxid > synctxid && isSyncRunning) {
try {
wait(1000);
} catch (InterruptedException ie) {
}
}如果当前的线程ID < 当前处理事务的最大ID,则说明当前线程的任务已经被其他线程完成了,什么也不用做了,直接返回
1
2
3
4
5
6
7
8if (mytxid <= synctxid) {
numTransactionsBatchedInSync++;
if (metrics != null) {
// Metrics is non-null only when used inside name node
metrics.incrTransactionsBatchedInSync();
}
return;
}
此事务开启同步状态,开始刷盘
1
2
3
4// 此事务开启同步状态,开始刷盘
syncStart = txid;
isSyncRunning = true;//开启同步
sync = true;双缓冲区交换数据
判断当前操作是否己经同步到了 edidog 文件中,如果还没有同步,则将 editlog 的双buffer 调换位置,为同步操作做准备,同时将 isSyncRunning 标志位设置为 true,这部分代码需要进行 synchronized 加锁操作。
1
editLogStream.setReadyToFlush();
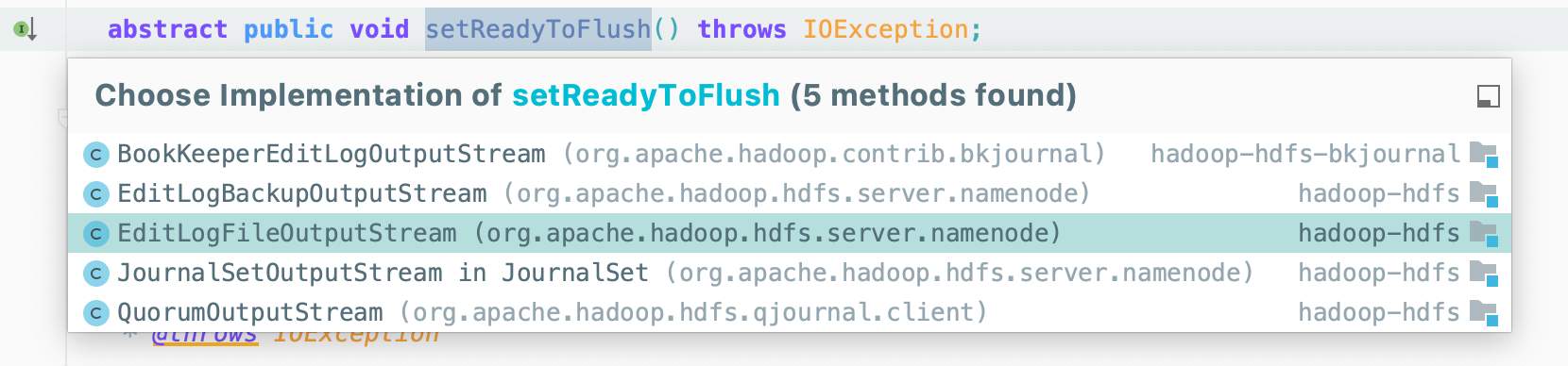
1
2
3
4
public void setReadyToFlush() throws IOException {
doubleBuf.setReadyToFlush();
}允许别的线程往buffer中写数据
1
doneWithAutoSyncScheduling();
将缓存区数据刷到磁盘
调用 logStrearn.flush() 方法将缓存的数据持久化到存储上
这部分代码不需要进行加锁操作,因为在上一段同步代码中已经将双 buffer 调换了位置,不会有线程向用于刷新数据的缓冲区中写入数据,所以调用 flush() 操作并不需要加锁。
1
logStream.flush();
恢复标志位
重置 isSyncRunning 标,志位,并且通知等待的线程
这部分代码需要进行 synchronized加锁操作。
1
2
3
4
5
6
7
8synchronized (this) {
if (sync) {
synctxid = syncStart;
isSyncRunning = false;
}
// 同时唤醒线程,通知该事务已经完成,可以进行下一次刷写
this.notifyAll();
}
三、源码修改
logEdit()方法中输出日志记录和调用 logSync(刷新缓冲区数据到磁盘这两个操作是独立加锁的,同时 EditLogOutputStream 提供了两个缓冲区可以同时进行日志记录和刷新缓冲区操作,所以 logEdit() 方法中使用 synchronized 关键字同步的日志记录操作和 logSync() 方法中使用synchronized 关键字同步的刷新缀冲区数据到磁盘的操作是可以并发同步进行的,它们都使用
FSEditLog 对象作为锁对象。这种设计大大地提高了多个线程记录 editlog 操作的并发性,且通过 transactionld 机制保证 了 editlog 日志记录的正确性。
3.1. 缓存区大小
如图所示,在 Hadoop 源码中双缓存中每个缓存区是固定的 512k,无法根据实际需求更改
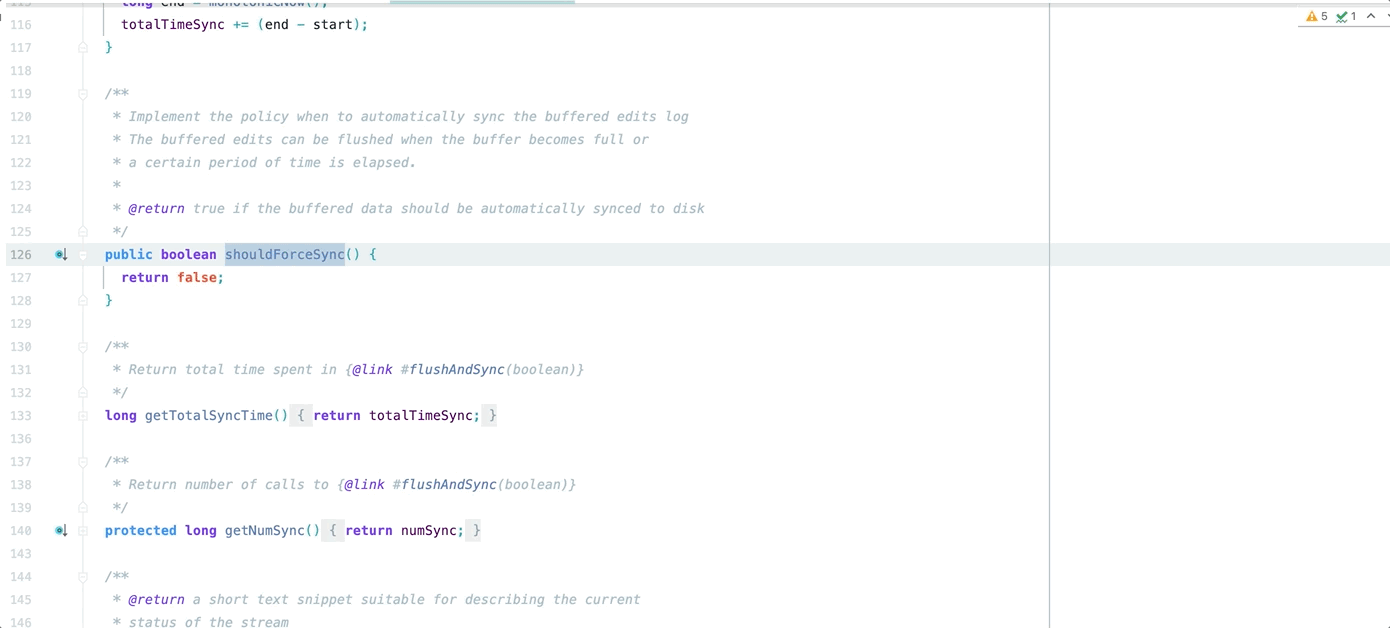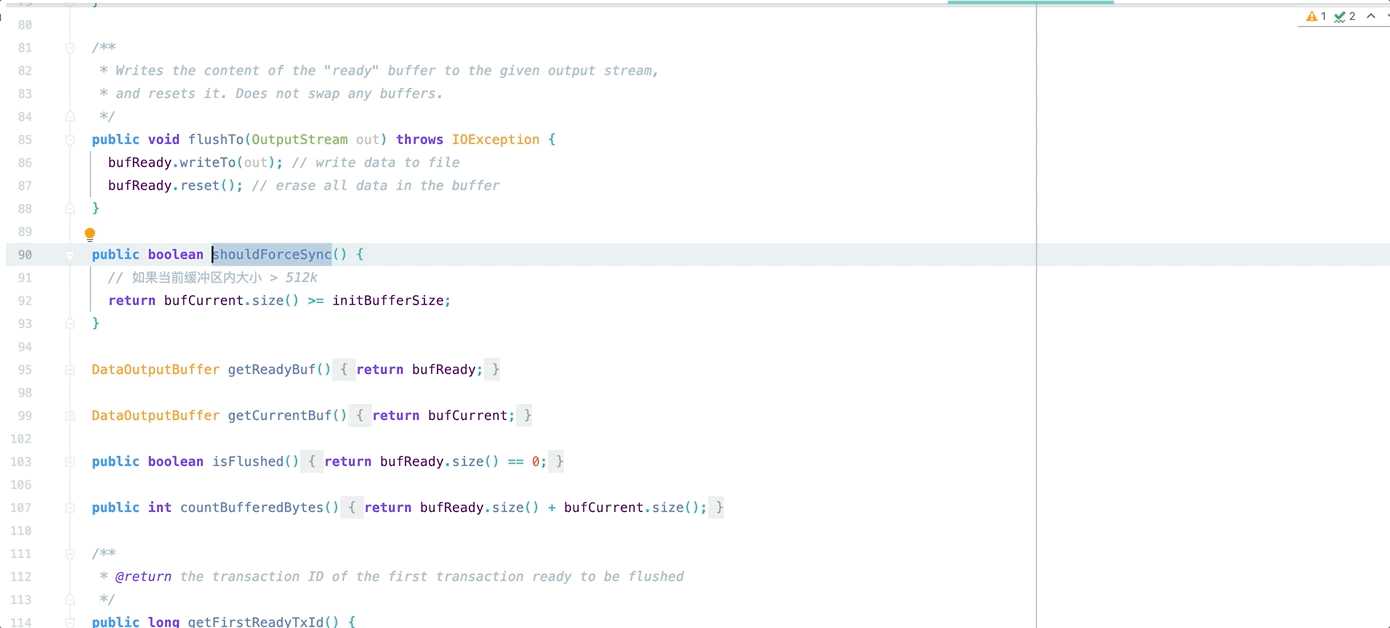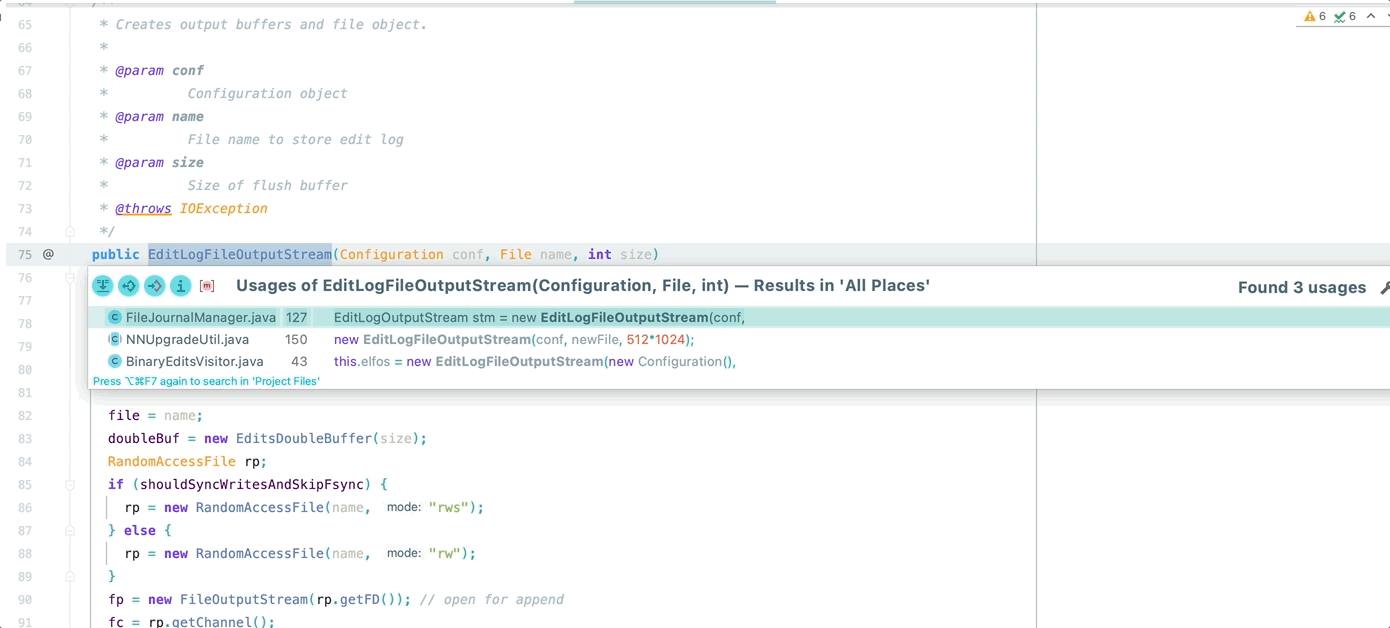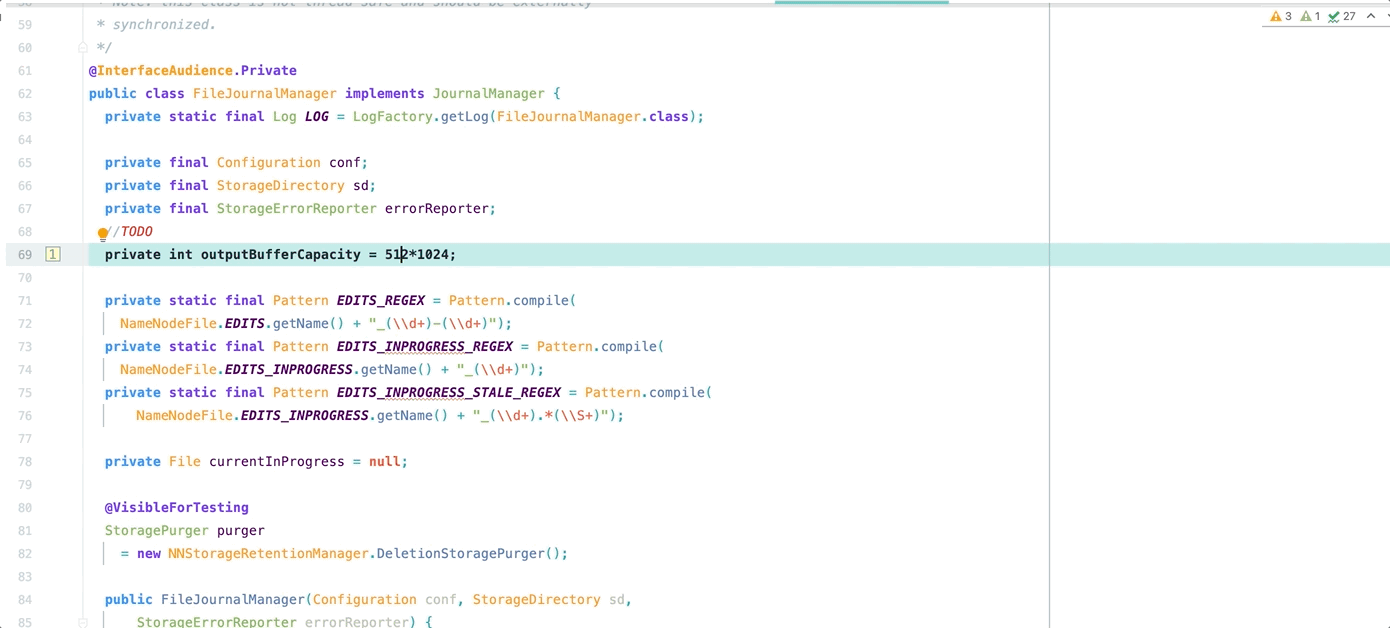
所以第一步,我们将其改成可配置哒~~~
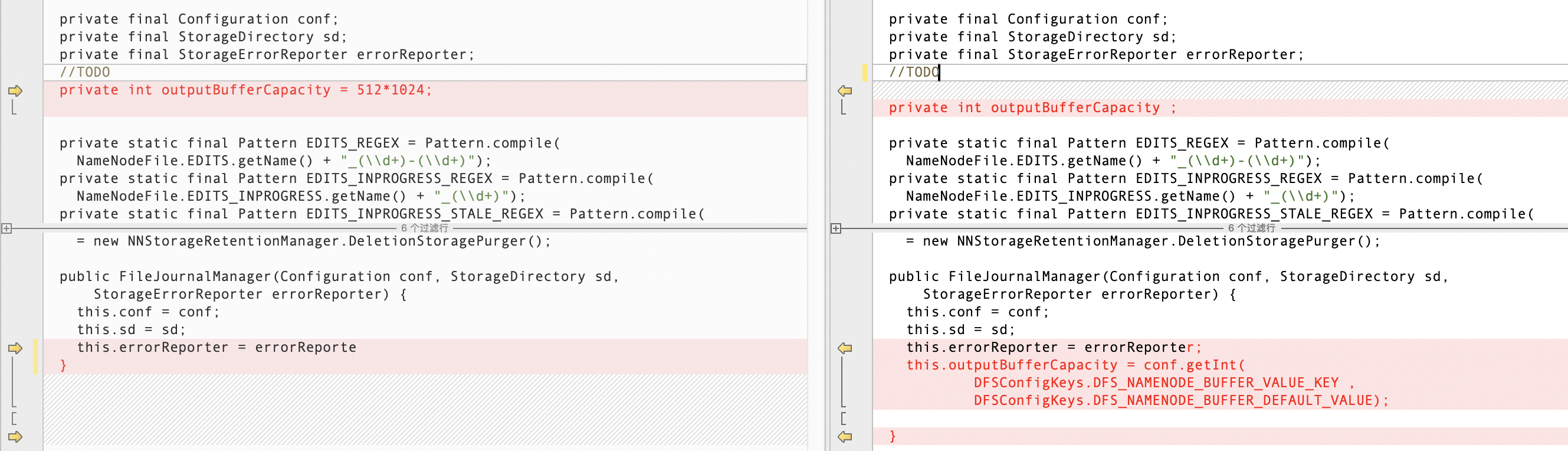
1 | //添加 buffer 大小 |
在配置文件中增加配置项
1 | <property> |
3.2. 降低锁粒度
edits 写磁盘的动作存在 IO 开销, 大量客户端同时写会导致写入本地磁盘文件时出现多线程安全问题,对每个写入的 edits log 分配一个全局顺序递增的 transactionid(txid), 基于这个序号可以标识每个 edits log 的先后顺序, 针对 txid,要保证全局顺序一致,就要加锁保证安全,也就是每个修改元数据的线程都要先拿到锁然后生成 txid 才能写入 edits log
获取到锁生成 txid 之后,就把数据写入缓冲区就释放锁而不是落磁盘网络传输之后再释放锁, 缓冲区也是有大小限制,所以缓冲区数据达到一定大小后还需要定期刷写到磁盘,但是
HDFS很巧妙运用了双缓存机制和分段加锁的方式实现了快速写入数据流量,包括现在外面很多公司进行二次开发的Hadoop,有很大部分优化是将重点放在降低锁粒度上,可以提高HDFS数据读写性能。

 微信
微信 支付宝
支付宝