
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode-QueryPlan-SparkPlan
一、概述
Spark SQL 最终将 SQL 语句经过逻辑算子树转换成物理算子树。在物理算子树中,叶子类型的 SparkPlan 节点负责 “从无到有” 地创建 RDD,每个非叶子类型的 SparkPlan 节点等价于在RDD 上进行一次 Transformation,即通过调用 execute() 函数转换成新的 RDD,最终执行 collect() 操作触发计算,返回结果给用户。
SparkPlan 在对 RDD 做 Transformation 的过程中除对数据进行操作外,还可能对 RDD 的分区做调整。此外,SparkPlan 除实现 execute 方法外,还有一种情况是直接执行 executeBroadcast 方法,将数据广播到集群上。
二、模块
具体来看,SparkPlan 的主要功能可以划分为 3 大块。首先,每个 SparkPlan 会记录其元数据(Metadata) 与指标(Metric)信息,这些信息以 Key-Value 的形式保存在 Map 数据结构中,统称为 SparkPlan 的 Metadata 与 Metric 体系。其次,在对 RDD 进行 Transformation 操作时,会涉及数据分区(Partitioning)与排序 (Ordering) 的处理,称为 SparkPlan 的 Partitioning 与 Ordering 体系;最后,SparkPlan 作为物理计划,支持提交到 Spark Core 去执行,即 SparkPlan 的执行操作部分,以 execute() 和 executeBroadcast() 方法为主。此外,SparkPlan 中还定义了一些辅助函数,如创建新谓词的 newPredicate 等。
2.1. Metadata 与 Metrics 体系
元数据和指标信息是性能优化的基础,SparkPlan 提供了 Map 类型的数据结构来存储相关信息,以便更加详细地刻画 SparkPlan 的细节。默认情况下,SparkPlan 中这两个 Map 的值均为空。
2.2. Partitioning 与 Ordering 体系
分区 (Partitioning) 和排序(Ordering) 相关的操作 (如 repartition 等) 在 Spark 中一直都是较为重要的内容。除涉及正确性外,分区的策略还对集样资源和应用性能有着重要的影响。Spark SQL 作为高层模块,需要灵活控制这些重要操作,SparkPlan 中实现了较为完整的分区与排序操作体系。
2.3. 执行操作体系
三、实现
3.1. 属性
3.1.1. prepared
1 | /** |
3.2. 方法
3.2.1. supportsRowBased
1 | def supportsRowBased: Boolean = !supportsColumnar |
3.2.2. supportsColumnar
表示如果计划的此阶段支持列式执行,则返回true。
1 | def supportsColumnar: Boolean = false |
3.2.3. executeColumnar()
3.2.3. vectorTypes
在列式处理模式下向量类型。 这是代码生成的性能优化。
3.2.4. setLogicalLink
3.2.5. execute()
四、继承体系
4.1. LeafExecNode
叶子节点类型的物理执行计划不存在子节点。物理执行计划中与数据源相关的节点都属于该类型。在 Spark SQL中,叶子节点类型的物理执行计划以 DataSourceScanExec 作为基类,具体的实现包括 FileSourceScanExec 和 RawDataSourceScanExec 两种。
LeafExecNode 类型的 SparkPlan 负责对初始 RDD 的创建。例如,RangeExec 会利用 SparkContext 中的 $parallelize()$ 方法生成给定范围内的 64 位数据的 RDD, Hive TableScanExec 会, FileSourceScanExec 根据数据表所在的源文件生成 FileScanRDD。

4.2. UnaryExecNode
UnaryExecNode 类型的物理执行计划的节点是一元的,只包含 1 个子节点,UnaryExecNode 节点的作用主要是对 RDD 进行转换操作。
如: ProjectExec 和 FilterExec 分别对子节点产生的 RDD 进行列剪裁与行过滤操作; Exchange 负责对数据进行重分区,SampleExec 对输入RDD 中的数据进行采样,SortExec 按照一定条件对输入 RDD 中数据进行排序,WholeStageCodegenExec 类型的 SparkPlan 将生成的代码整合成单个 Java 函数。
4.3. BinaryExecNode
BinaryExecNode 类型的 SparkPlan 具有两个子节点。
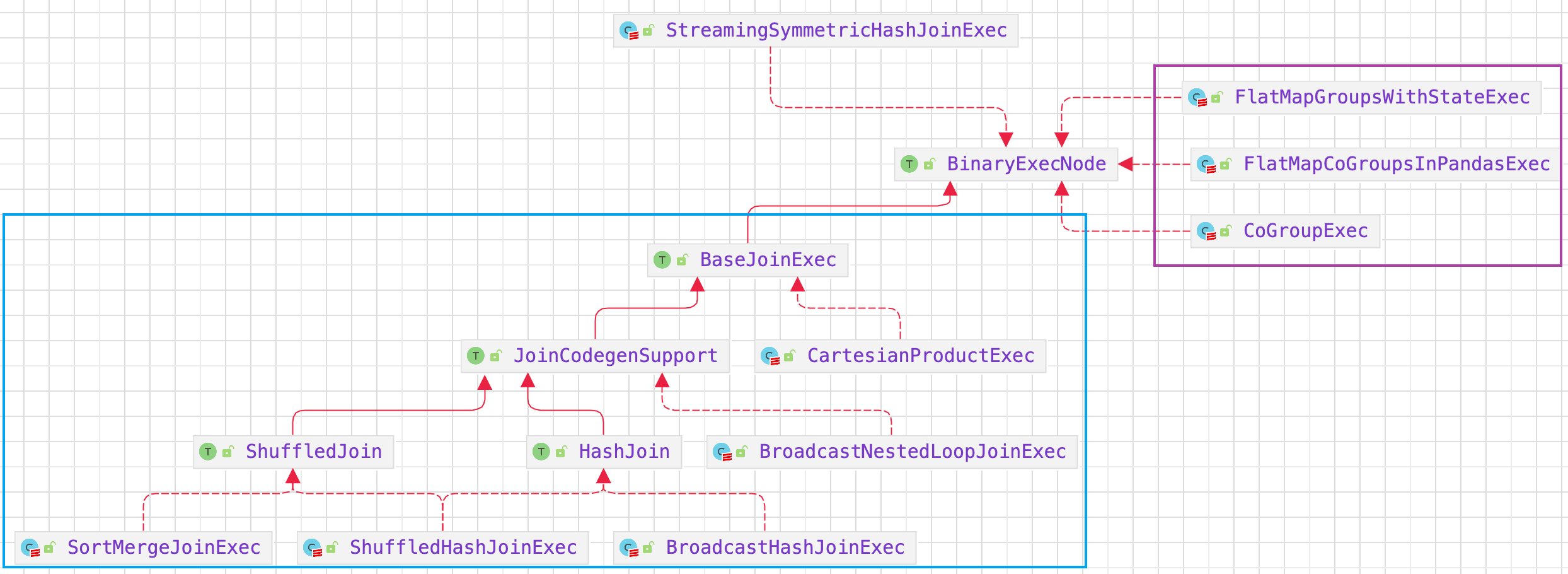
4.3.1. BaseJoinExec
4.3.2.
4.4. V2CommandExec
4.5. CodegenSupport
 微信
微信 支付宝
支付宝








