大数据-存储格式-OrcFile
一、概述
二、RCFile(Record Columnar File)
2.1. File Format
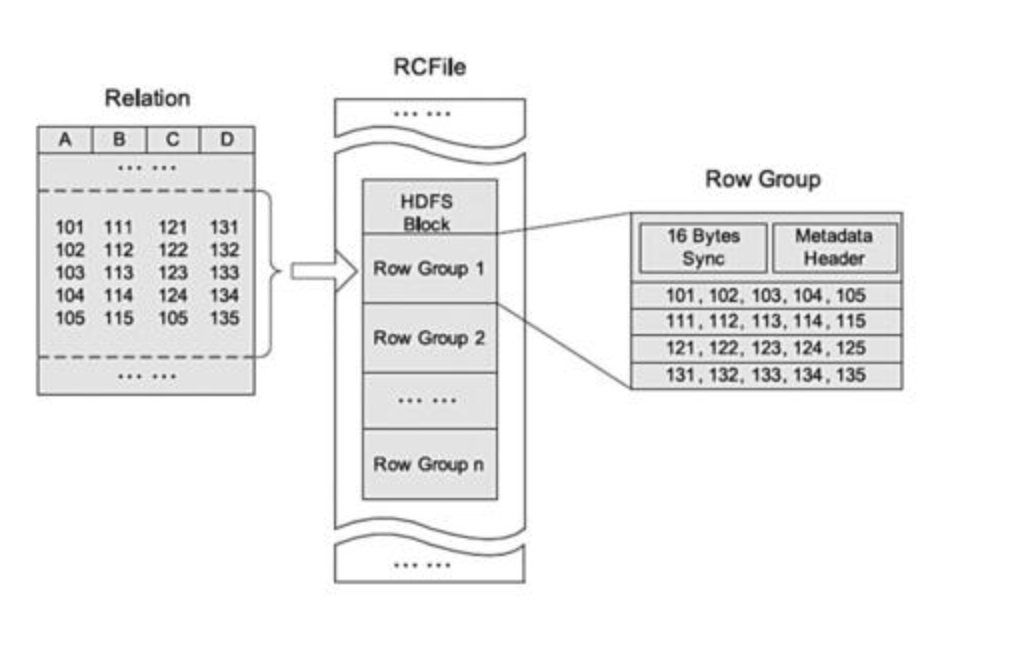
RCFile 基于 HDFS 架构,存储在一个 HDFS 块中的所有记录被划分为多个行组。
对于一张表,所有行组大小都相同。一个行组包括三个部分。第一部分是行组的头部标识,主要用于分隔 HDFS 块中的两个连续行组;第二部分是行组的元数据头部,用于存储行组单元的信息,包括行组中的记录数、每个列的字节数、列中每个域的字节数;第三部分是数据段,即实际的列存储数据。在该部分中,同一列的所有域顺序存储。
RCFile 由于相同的列都是在一个 HDFS 块上,所以相对列存储而言会节省很多资源。
一种行列存储相结合的存储方式。首先,其将表数据分为几个行组,对每个行组内的数据按列存储,先水平划分,再垂直划分的理念。它结合了行存储和列存储的优点,保证同一行的数据位于同一节点,并且像列存储一样,RCFile 能够利用列维度的数据压缩,跳过不必要的列读取。
RCFile 具备相当于行存储的数据加载速度和负载适应能力;其次,RCFile 的读优化可以在扫描表格时避免不必要的列读取
2.2. 存储空间
RCFile 采用游程编码,相同的数据不会重复存储,节约了存储空间
游程编码是一种比较简单的压缩算法,其基本思想是将重复且连续出现多次的字符使用(连续出现次数,某个字符)来描述。比如一个字符串
AAAAABBBBCCC
使用游程编码可以将其描述为
5A4B3C
2.3. 行组大小
I/O性能是RCFile关注的重点,因此RCFile需要行组够大并且大小可变。行组大小和下面几个因素相关。
行组大的话,数据压缩效率会比行组小时更有效。
根据对Facebook日常应用的观察,当行组大小达到一个阈值后,增加行组大小并不能进一步增加Gzip算法下的压缩比。
行组变大能够提升数据压缩效率并减少存储量。因此,如果对缩减存储空间方面有强烈需求,则不建议选择使用小行组。需要注意的是,当行组的大小超过4MB,数据的压缩比将趋于一致。
尽管行组变大有助于减少表格的存储规模,但是可能会损害数据的读性能,因为这样减少了Lazy解压带来的性能提升。而且行组变大会占用更多的内存,这会影响并发执行的其他MapReduce作业。
考虑到存储空间和查询效率两个方面,Facebook选择4MB作为默认的行组大小,当然也允许用户自行选择参数进行配置。
2.4. 懒加载
数据存储到表中都是压缩的数据,Hive读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
1 | select c from table where a>1 |
针对行组来说,会对一个行组的a列进行解压缩,如果当前列中有a>1的值,然后才去解压缩c。若当前行组中不存在a>1的列,那就不用解压缩c,从而跳过整个行组。
三、ORCFile
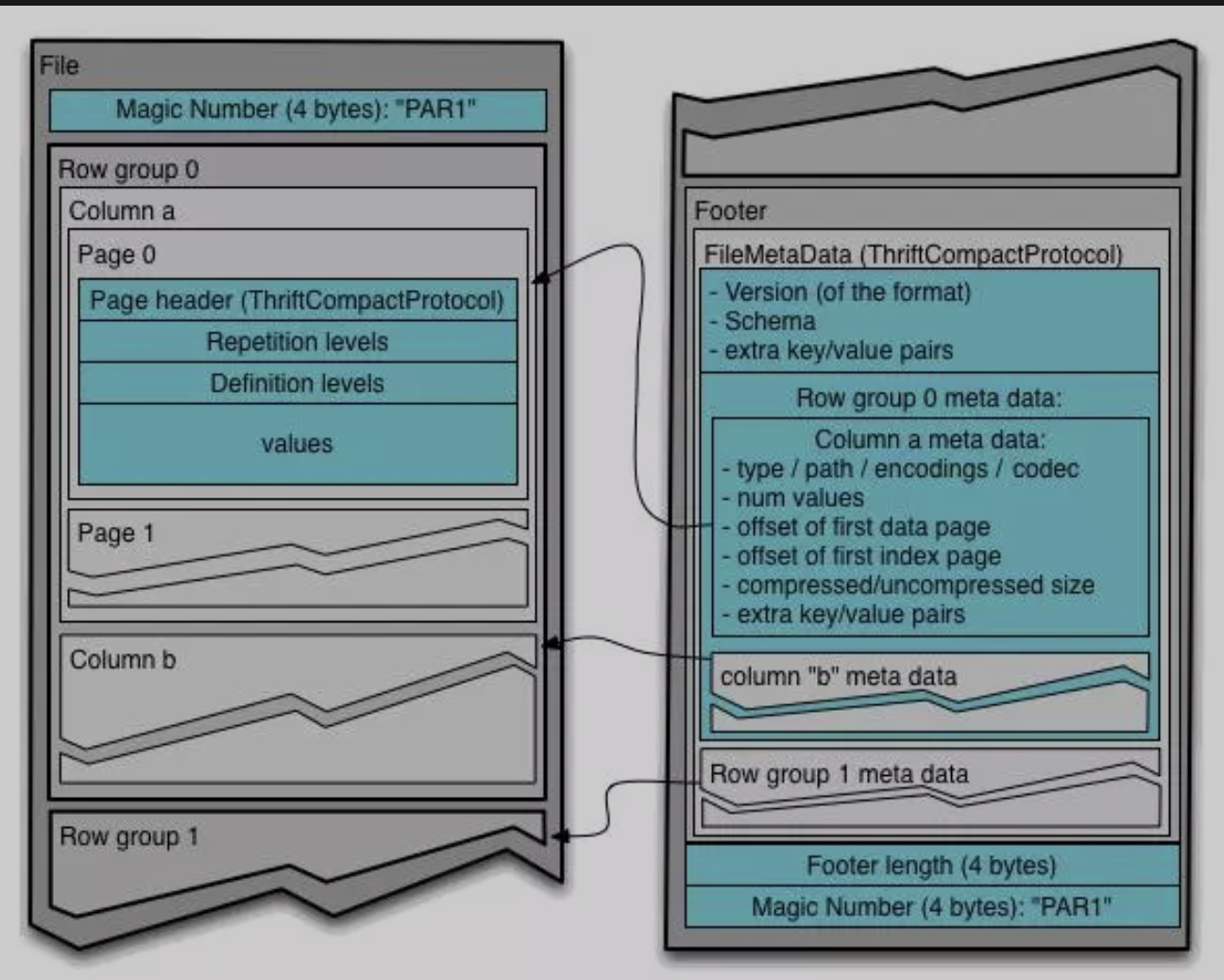
3.1. File Format
$ORC$ $(Optimized\ Record\ Columnar)$ 是 $RC\ File$ 的改进,主要在压缩编码、查询性能上进行了升级。在 $ORC$ 格式的 $hive$ 表中,记录首先会被横向的切分为多个 $stripes$ ,然后在每一个 $stripe$ 内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。
每个 ORC 文件由1个或多个 stripe 组成,每个 stripe 大小 250MB

这个 Stripe 实际相当于 RowGroup 概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。
每个 Stripe 里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
3.1.1. Index Data
轻量级的 index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
3.1.2. Row Data
存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储。与RCfile不同的地方在于每个列进行了编码,分成多个Stream来存储
Stream保存了用户真正关心的业务数据内容,这也是ORC列式存储的根本所在:正如开头的架构图一样,一个大文件由各Stripe分割,每个Stripe负责一个或多个行组(一个行组默认10000行),在一个Stripe负责的这多行范围内,各列的数据内容以Stream的形式按列存储。为了描述每个Stream,ORC以字节为单位存储Stream的类型、列ID和Stream的大小。每个Stream中存储内容的详细信息取决于列的类型和编码。也就是说,在一个Stripe中的每一列都可能有多个表示不同信息的Stream
如果该Stripe中所有列的值都不为空,则从Stripe中省略PRESENT stream
3.1.3. Strip Footer
存的是各个 Stream 的类型,长度等信息
每个文件有一个 $File\ Footer$ ,这里面存的是每个 $stripe$ 的行数,每个 $column$ 的数据类型信息等
每个文件的尾部是一个 $PostScript$ ,这里面记录了整个文件的压缩类型以及 $File\ Footer$ 的长度信息等。
在读取文件时,会首先到文件尾部读 $PostScript$ ,从里面解析到 $File\ Footer$ 长度,再读 $File\ Footer$ ,从里面解析到各个$stripe$ 信息,再读各个 $stripe$ ,即从后往前读。
 微信
微信 支付宝
支付宝